一 创建一个deployment的时候整个kubernets集群的资源和事件的调用链
1.1 创建一个deployment的资源,在提交的时候,集群中的调度器,控制器以及node节点上kubelet就已经通过监听各自资源类型的变化,如图所示

-
- kubernets组件通过API服务器监听API对象
1.2 观察本次创建资源的事件链
当你将deployment的yaml文件通过kubectl提交给API服务器的时候,实际上kubectl会对API服务器发起一个HTTP的post请求,API服务器对请求进行鉴权,认证,准入,最终效验,最后写入etcd存储中,并且将结果返回给API服务器,整个事件链如图所示
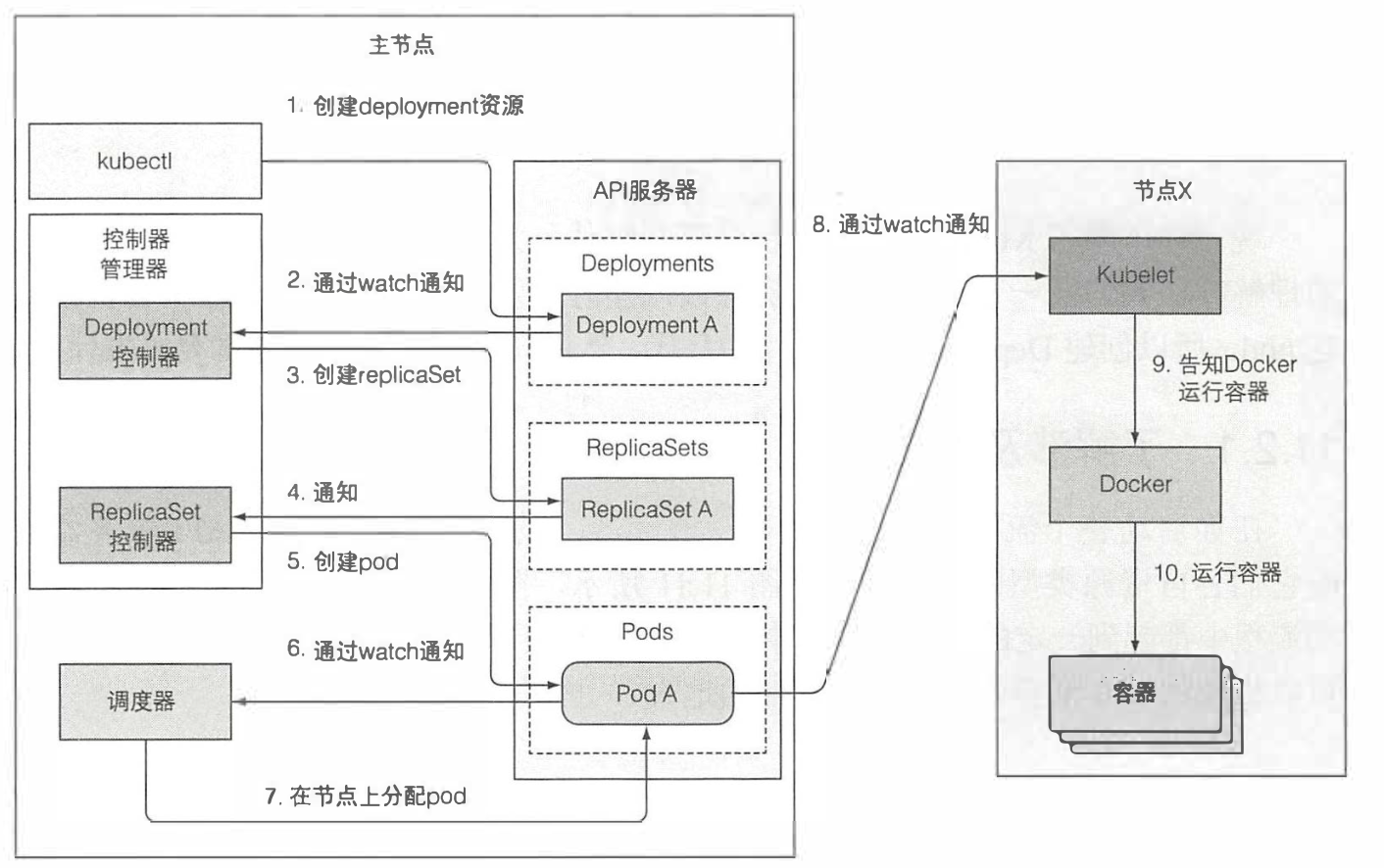
- 当客户端kubectl向API服务器发起创建一个deployment资源的时候
- 集群里面所有监听了deployment资源的调度器会收到一个通知,其中在这里我们要说明的只是deployment同样也会收到通知
- deployment调度器收到通知之后会去根据deployment的定义向API服务器发起创建RS
- 彼时在集群中的RS控制器通过监听也收到了RS的创建,并创建了pod
- 等待pod创建完成之后,调度器就会将其分配给工作节点,相应的工作节点通过订阅得知pod被调度自己的节点上
- 于是kubelet会去拉取镜像,启动容器,并将结果反馈给API服务器
1.3 观察集群事件
控制平面以及kubelet在执行相关操作的时候都会向API服务器发送事件,发送事件是通过创建事件资源来实现的,每次使用kubectl describe来检查资源的时候就能看到相关的事件,也可以直接使用kubectl get events --watch
[root@node01 ~]# k get events --watch NAME AGE kubia-0.1659b586ea3d7158 0s kubia-1.1659b586ec5d986a 0s kubia-2.1659b586ed5fc952 0s kubia.16591db959436c4c 0s kubia-0.1659b58e5854386e 0s kubia-0.1659b58e8bb8c852 0s kubia-0.1659b58ee400e30f 0s
了解运行中的pod都是些什么
查看下pod中的容器状况
[root@node01 Chapter10]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9a96d4501bee luksa/kubia-pet "node app.js" 40 seconds ago Up 39 seconds k8s_kubia_kubia-1_default_82c80622-5566-11eb-ae9a-5254002a5691_0 1733975abffb k8s.gcr.io/pause:3.1 "/pause" 44 seconds ago Up 43 seconds k8s_POD_kubia-1_default_82c80622-5566-11eb-ae9a-5254002a5691_0
- 从这里可以看到在一个容器起来之前就已经有了/pause容器起来
- 这个容器看起来没有任何实质的作用,但是实际上还是有很大的意义的,它会将一个pod的所有容器组织在同一个命名空间里面

- 实际上,这个基础容器的生命周期基本和pod保持一致,当pod里面的容器需要重启的时候,或者删除重新拉起的时候,需要和之前的容器在同一个命名空间里面,而这个基础容器使之成为可能,如果pod被删除,kubelet会重新去创建它,并包含基础容器以及该pod内部的所有容器
1.4 了解pod中的网络
kubernetes自身并不提供任何的网络插件,而是通过集群管理员或者CNI来配置pod之间的网络,集群的要求是,所有pod都应该在一个扁平的网络环境里面互相通信,换句话就是说pod之间的通信不能够过NAT。
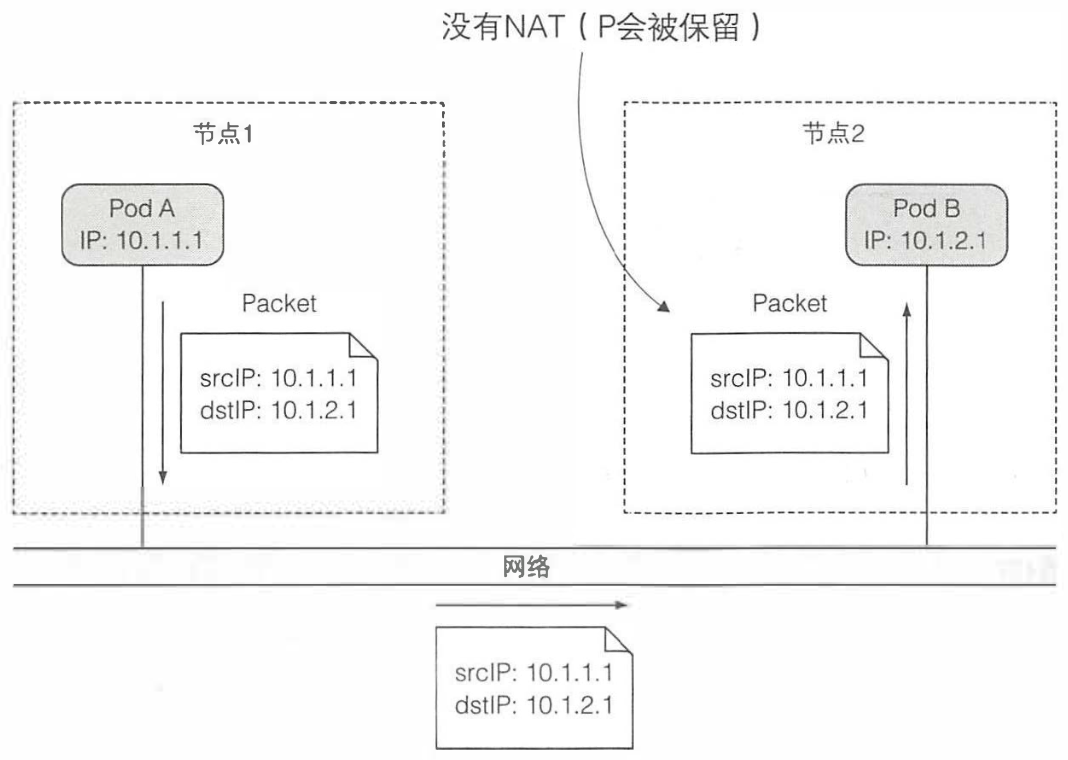
- pod到pod之间通信没有使用NAT网络
- 同样的pod到主机上面的网络也是没有过NAT的
- 但是pod与外部服务通信的时候,就会使用NAT地址转换,由于pod使用的是似有地址,所有会转化为主机的地址
深入了解网络工作原理
每个pod里面都会有个pause容器,每个pod里面的网络接口以及都会被存储在这个基础容器里面
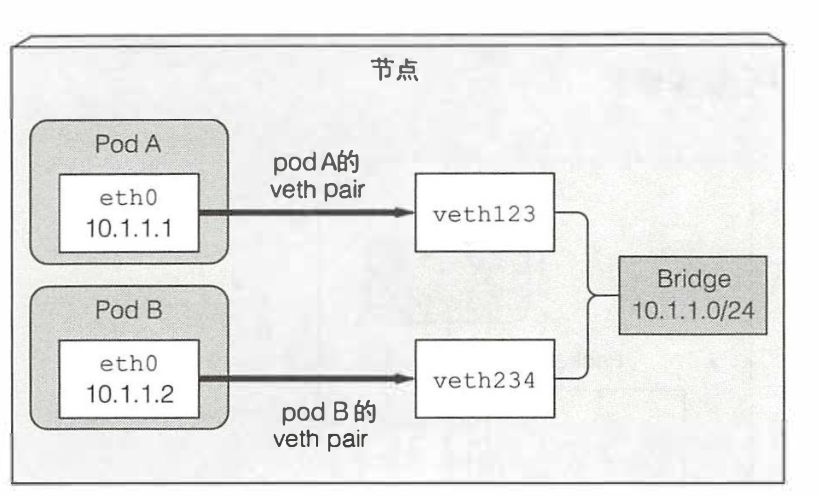
同一节点上pod之间如何通信
-
- 每个节点上面都有都会有一个网络插件的网桥
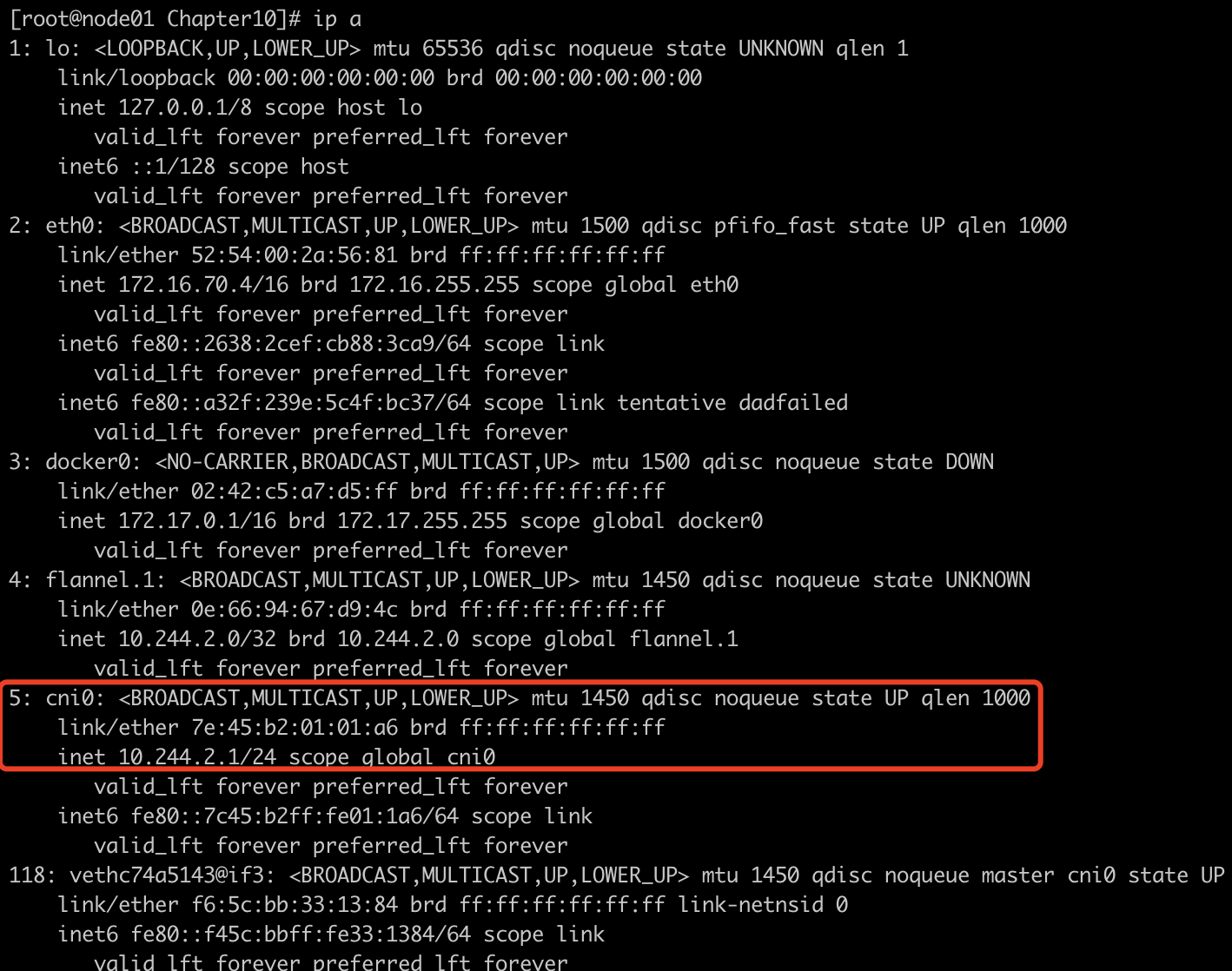
-
每个pod都有一个网卡对,一端在pod内部被改名为eth0,一端以vethxxx的形式到节点上
-
同节点上面pod通信步骤是,podA的应用经由podA的网卡的eth0到节点端的一侧,之后到达网桥,再从网桥到达另一pod的node端,最后到另一个pod的容器的eth0进入容器应用
不同的节点上面的node通信架构如图所示

不同节点之间的pod通信需要一个三层网络,一般借助网络插件,将不同节点之间的网络打通,之后的流程就是单个节点之间的通信