这片博文会详细说明MySQL复制的过程以及复制的原理!
会详细说明以下几种复制模式:传统的MySQL复制,MySQL5.6的半同步辅助以及MySQL5.7的无损复制。
传统的MySQL异步复制
复制解决的基本问题是让一台服务器的数据与其他服务器的数据保持同步。一台主库的数据可以同步到多台备库上,备库本身也可以被设置成另外一台服务器的主库。主库和备库之间可以有多种不同的组合方式。
mysql支持两种方式的复制;基于行的复制和基于语句的复制。基于语句的复制在之前的版本中就已经存在,但是基于行的复制在mysql5.1之后,才开始支持!这两种方式都是通过在主库上记录二进制日志,在备库重放日志的方式来实现异步数据的复制! 这意味着,在同一时间点备库上的数据可能与主库存在不一致的,并且无法保证主备之间的延迟。
上面我们提到过复制是基于二进制日志进行的,那么复制究竟是如何工作的?总的来说,复制有三个步骤
- 在主库上把数据更改记录到二进制日志中(这些记录被称为二进制日志事件)
- 被库将主库上的二进制日志复制到自己的中继日志中。
- 备库读取中继中的事件,然后将其重放到备库上!
复制过程如图(图片来自网络,这个图很经典,几乎每片将mysql主从的都会有的)
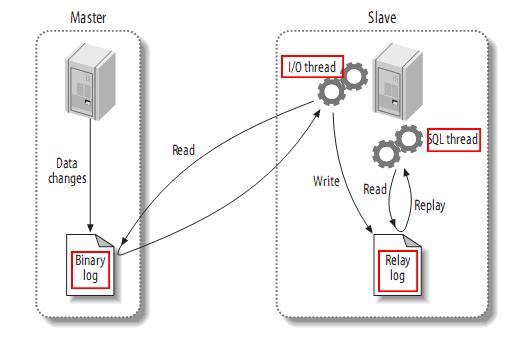
第一步:在主库上记录二进制日志。在每次准备提交事务完成数据更新前,主库将数据更新的事件按照事务提交的顺序写入二进制日志,写入二进制日志之后,主库会告诉存储引擎可以提交事务了!
第二步:备库将主库的二进制日志复制到本地的中继日志中。首先,备库会启动一个工作线程(I/O线程),I/O线程跟主库建立一个普通的客户端连接,然后在主库上启动一个特殊的二进制转储线程(dump 线程),dump线程会读取主库上二进制日志中的事件。它不会对事件尽心轮询,如果该线程追赶上了主库,它将进入休眠状态,直到主库发送信号量通知其有新的事件产生时才会被唤醒,备库I/O线程会将接收到的事件记录到中继日志中。
第三:备库的SQL线程会重放中继日志中的事件,从而实现主库的数据在从库的复制。
这种复制架构实现了获取事件和重放事件的解耦(生产者与消费者模型),允许这两个事件异步进行。也就是说I/O线程独立于SQL线程之外工作。但是由于这种架构限制了复制过程,其中最重要的就是在主库上并发运行的查询在备库上只能串行执行,因为只有一个SQL线程来重放中继日志中的事件。而这一点也是mysql复制的性能瓶颈所在,因此在mysql5.6和mysql5.7中都对此做了优化,后面我们会说到的!
#在mysql的复制过程中,基本上来说有三个主要线程!
master转储线程:当slave IO线程连接master时,master创建这个线程。负责从master的binlog文件读取记录,然后发送给slave。每个连接到master的slave都有一个转储线程
slave IO线程:负责连接master并请求所有master上的更新转储到中继日志,以便SQL线程进行进一步的处理。每个slave都有一个IO线程。一旦连接建立,这个线程就一直都在,
这样slave就能立即收到master的所有更新。
slave SQL线程:这个线程读取中继日志中的更新,然后在从库上应用这些更新。这个线程负载协调其他mysql线程,保证这些更新不与mysql服务器上的其他活动产生冲突。
下面我们搭建一个传统的异步复制
mysql的主从搭建很简单,只说一下搭建的步骤:
若是两个全新的服务器,没有任何数据:(全新的服务器,数据本身就是一致的状态)
l 第一步:分别开启二进制日志
l 第二步:修改两个服务器的server-id,两台服务器的id设置要不一样。
l 第三步:在作为master的服务器上创建用来做主从复制的用户。
l 第四步:在从上连接master服务器,然后在从上执行start slave。
mysql> select @@version; #我们测试用的数据库的版本 +-----------+ | @@version | +-----------+ | 5.7.23 | +-----------+ 1 row in set (0.00 sec) mysql> show databases; #这台数据库上有数据 +--------------------+ | Database | +--------------------+ | information_schema | | djtest | | employees | | hostinfo | | mysql | | mytest | | performance_schema | | sys | +--------------------+ 8 rows in set (0.00 sec)
第一步:把当前服务器服务器中所有的数据备份,然后在新建的从库上进行恢复,使两台服务器处于一致的状态!
[root@mgt01 ~]# mysqldump -uroot -p123456 --single-transaction --all-databases > all.sql mysqldump: [Warning] Using a password on the command line interface can be insecure. [root@mgt01 ~]# scp all.sql 192.168.1.121:/root/ root@192.168.1.121's password: all.sql 100% 161MB 32.3MB/s 00:05 [root@mgt01 ~]# #在从库执行恢复 [root@mgt02 ~]# mysql -uroot -p123456 < all.sql mysql: [Warning] Using a password on the command line interface can be insecure. [root@mgt02 ~]#
第二步:开启主库的而二进制日志,若是做级联复制从库也需要开启二进制日志(后面再说)
#在主库配置文件设置 log-bin= #二进制日志默认是在datadir指定的目录下面的 server-id=13 #在主从环境中,每台服务器的server-id要设置的不一样 #在从库配置文件设置 server-id=13
第三步:在主库上创建用来复制的账号:
mysql> grant all privileges on *.* to "repl"@"192.168.1.121" identified by "123456"; Query OK, 0 rows affected, 1 warning (0.00 sec) mysql> show warnings; +---------+------+------------------------------------------------------------------------------------------------------------------------------------+ | Level | Code | Message | +---------+------+------------------------------------------------------------------------------------------------------------------------------------+ | Warning | 1287 | Using GRANT for creating new user is deprecated and will be removed in future release. Create new user with CREATE USER statement. | +---------+------+------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> flush privileges; Query OK, 0 rows affected (0.00 sec) mysql>
第四步:从库连接主库
首先查看主库二进制的日志点:
mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mgt01-bin.000001 | 598 | | | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) mysql>
然后在从库上执行如下命令:
mysql> change master to master_host="192.168.1.120", master_user="repl",master_password="123456",master_log_file="mgt01-bin.000001",master_log_pos=598; Query OK, 0 rows affected, 2 warnings (0.08 sec)
#这里的两个警告,只是说明了一些传输安全信息
mysql> start slave; #开启复制
Query OK, 0 rows affected (0.00 sec)
mysql> show slave statusG #从上查看状态
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.120
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mgt01-bin.000001
Read_Master_Log_Pos: 598
Relay_Log_File: mgt02-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mgt01-bin.000001
Slave_IO_Running: Yes #表明IO线程和SQL线程已经工作了
Slave_SQL_Running: Yes
。。。。。。。。
测试如下:


#在主库做如下操作 mysql> insert into tb1 values(1, @@hostname, "test"); Query OK, 1 row affected (0.04 sec) mysql> select * from tb1; +------+-------+------+ | id | name | info | +------+-------+------+ | 1 | mgt01 | test | +------+-------+------+ 1 row in set (0.00 sec) #在从库查看数据 mysql> select * from tb1; +------+-------+------+ | id | name | info | +------+-------+------+ | 1 | mgt01 | test | +------+-------+------+ 1 row in set (0.00 sec) #若是基于语句的复制,这两个数据应该不一样的,但是现在是一样的,说明是基于行的复制! mysql> show variables like "binlog_format"; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+ 1 row in set (0.00 sec)
一个简易的主从架构已经完成!
下面我们会详细说明与MySQL主从复制相关的几个文件(二进制日志文件会单独列出来讲的)
中继日志是连接master和slave的信息,是复制的核心。
中继日志除了含有二进制日志和索引文件以外,中继日志还维护两个文件来跟踪复制的进度,即中继日志信息文件和master日志信息文件,这个两个文件名字由my.cnf的两个参数配置。
relay_log_info_file=filename;如果没有指定文件名,则默认为:relay-log.info。 master-info-file=filename:这个参数设置master日志信息文件。默认文件名为master.info。
查看一下maste.info信息如下:

master.info文件包含master的读位置,以及连接master和启动复制必须的所有信息。当slave的IO线程启动时,如果有master.info文件,则线程先从这个文件读取信息。
master.info文件中的信息优于my.cnf文件。也就是说,如果改变了配置文件中的信息,重启服务器,将会从master.info读取信息而不是配置文件。
因此不推荐在配置文件中使用change master to参数配置,而是直接使用命令。由于某种原因,需要把复制参数放到配置文件中,而且希望slave启动的时候读取这些
参数,则必须在编辑配置文件之前执行reset slave命令。
请谨慎执行reset slave命令!这个命令会删除master.info和relay-log.info文件,以及所有的中继日志文件!
查看relay-log.info的信息
[root@test2 mysql]# cat relay-log.info 7 ./test2-relay-bin.000002 #当前正在读取的中继日志 320 #当前正在读取的中级日志的position位置 test3-bin.000003 #这个在主从复制时change master命令指向的master的二进制日志的文件名和日志位置 1669 0 0 1
relay-log.info文件跟踪复制的进度,并由SQL线程负责更新。
如果某些文件不可用时,在slave启动的时候,能够根据配置文件和change master to命令参数重建这些文件。仅仅使用配置文件并执行change命令是不够的,只有执行了start slave命令, master.info文件和relay-log.info文件才会被创建。
也就是可以这样说:master.info对应的是I/O线程,而relay-log.info对应的是SQL线程!
控制slave复制的几个命令:
START / STOP SLAVE START / STOP slave io_thread START/ STOP slave sql_thread
slave_parallel_workers参数
上面提到过在MySQL5.6之前的异步复制中,只有一个IO线程,一个用于回放中继日志的SQL线程,SQL线程的回放效率成为性能的瓶颈!在MySQL5.6中引入了slave_parallel_workers参数,这个参数可以设置用于回放中继日志的线程数量。
但是MySQL5.6的多线程复制却是基于schema,也就是说只有在master上多个schema,那么这个多线程复制才会有作用,但是线上环境大多是一个schema中含有多张表,因此这个时候多线程将无法发挥应有的作用;MySQL5.7中引入了slave_parallel_type参数,这个参数可以设置为LOGICAL_CLOCK,基于逻辑的复制,才能真正发挥多线程的作用。
mysql> show variables like "slave_parallel_type"; +---------------------+----------+ | Variable_name | Value | +---------------------+----------+ | slave_parallel_type | DATABASE | #默认是基于schema +---------------------+----------+ 1 row in set (0.01 sec) mysql>
配置slave参数:
#并行复制参数配置
slave_parallel_workers=3 slave_parallel_type=LOGICAL_CLOCK
#设置了并行复制之后,可以看到有3个SQL线程在等待处理中继日志
mysql> show processlist; +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ | 1 | system user | | NULL | Connect | 68 | Waiting for master to send event | NULL | | 2 | system user | | NULL | Connect | 68 | Slave has read all relay log; waiting for more updates | NULL | | 3 | system user | | NULL | Connect | 68 | Waiting for an event from Coordinator | NULL | | 4 | system user | | NULL | Connect | 68 | Waiting for an event from Coordinator | NULL | | 5 | system user | | NULL | Connect | 68 | Waiting for an event from Coordinator | NULL | | 8 | root | localhost | NULL | Query | 0 | starting | show processlist | +----+-------------+-----------+------+---------+------+--------------------------------------------------------+------------------+ 6 rows in set (0.01 sec)
#在数据库目录下面也产生了对应个数的中继日志信息(线上环境建议为16或32)
[root@test2 mysql]# ls worker-relay-log.info.*
worker-relay-log.info.1 worker-relay-log.info.2 worker-relay-log.info.3
以上就是传统的异步复制
半同步复制和无损复制
半同步复制的原理是在复制继续运行之前,确保至少有一个slave将变更写到磁盘。也就是说,对每个链接来说,如果发生master崩溃,至多只有一个事务丢失。
半同步复制并不会阻止事务的提交,而是直到事务写入至少一个slave中继日志才向客户端发送响应。事务发送到slave之前是先提交到存储引擎,而在一个slave确定事务已经写入磁盘之后,才向客户端发送提交确认。
半同步复制,只有在任一个slave已经确定存储了上一个事务,然后向主发送确认回应,主才会继续向slave中传递事务信息。因此半同步复制,最多只会丢失一个事务。
配置半同步复制:
第一:首先配置好主从架构。
第二:安装插件,在mysql5.6及之后的版本已经融合入mysql中,可以直接安装。
第三:主和从都要开启复制,然后重启服务器。
#查看当前MySQL是否开启自动加载的功能! mysql> show variables like "have_dynamic_loading"; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | have_dynamic_loading | YES | +----------------------+-------+ 1 row in set (0.00 sec)
安装插件:
mysql> install plugin rpl_semi_sync_master soname "semisync_master.so"; ERROR 1125 (HY000): Function 'rpl_semi_sync_master' already exists mysql> install plugin rpl_semi_sync_slave soname "semisync_slave.so"; Query OK, 0 rows affected (0.03 sec)
然后开启半同步复制:
#在主和从上分别添加如下参数 在主上添加 rpl-semi-sync-master-enabled = 1 在从上添加 rpl-semi-sync-slave-enabled = 1
查看参数:
mysql> show variables like "%semi%"; +-------------------------------------------+------------+ | Variable_name | Value | +-------------------------------------------+------------+ | rpl_semi_sync_master_enabled | ON | | rpl_semi_sync_master_timeout | 10000 | | rpl_semi_sync_master_trace_level | 32 | | rpl_semi_sync_master_wait_for_slave_count | 1 | | rpl_semi_sync_master_wait_no_slave | ON | | rpl_semi_sync_master_wait_point | AFTER_COMMIT | | rpl_semi_sync_slave_enabled | OFF | | rpl_semi_sync_slave_trace_level | 32 | +-------------------------------------------+------------+ 8 rows in set (0.01 sec)
#参数说明
rpl_semi_sync_master_enabled: 主服务器开启半同步复制。
rpl_semi_sync_slave_enabled : 从服务器开启半同步复制。
rpl_semi_sync_master_timeout: 超过10s slave没有回应,半同步复制会变为异步复制
rpl_semi_sync_master_trace_level:开启半同步复制时的调试级别,默认是32.
rpl_semi_sync_master_wait_no_slave :master的每个事务是否都需要slave的接收确认!
rpl_semi_sync_master_wait_for_slave_count:
rpl_semi_sync_master_wait_point: 最后两个参数树MySQL5.7加入的,半同步复制升级为无损复制。后面再说明
半同步复制因阻塞变为异步复制:只会在第一个事务产生rpl_semi_sync_master_timeout时长的阻塞,变为半同步复制之后,事务就不会再阻塞。
root@employees 06:17:58>update employees set first_name="wang" where emp_no = 23485; #半同步复制 Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 root@employees 06:18:07>update employees set first_name="qian" where emp_no = 23485; #断开主从的连接,事务开始阻塞,这里设置了 rpl_semi_sync_master_timeou时长为50s,阻塞50s后插入 Query OK, 1 row affected (50.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 root@employees 06:21:22>update employees set first_name="zhao" where emp_no = 12986; #之后的事务不再阻塞 Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0
半同步复制具体特性:(摘自http://www.ywnds.com/?p=7023)
- 从库会在连接到主库时告诉主库,它是不是配置了半同步。
- 如果半同步复制在主库端是开启了的,并且至少有一个半同步复制的从库节点,那么此时主库的事务线程在提交后会被阻塞并等待。此时,等待的结果有两种可能,要么至少一个从库节点通知它已经收到了所有这个事务的Binlog事件,要么一直等待直到超过配置的某一个时间点为止。而此时,半同步复制将自动关闭,转换为异步复制。
- 从库节点只有在接收到某一个事务的所有Binlog,将其写入并Flush到Relay Log文件之后,才会通知对应主库上面的等待线程。
- 如果在等待过程中,等待时间已经超过了配置的超时时间,没有任何一个从节点通知当前事务,那么此时主库会自动转换为异步复制,当至少一个半同步从节点赶上来时,主库便会自动转换为半同步方式的复制。
- 半同步复制必须是在主库和从库两端都开启时才行,如果在主库上没打开,或者在主库上开启了而在从库上没有开启,主库都会使用异步方式复制。
通过上面几点特征,可以知道半同步的实质是,在主库被阻塞的过程中(等待从库反馈确认消息),主库处理线程不会返回去处理当前事务。当阻塞被激活之后,系统才会把控制权交给当前线程,然后继续处理当前事务余下的事情。处理完成之后,此时主库的事务已经提交,同时至少会有一个从库也已经收到了这个事务的Binlog,这样就尽可能地保证了主库和从库的数据一致性。
丢失一个事务:
上面我们提到过,半同步复制至多会丢失一个事务,也就是说当master已经提交了事务t1(事务t1已经在master上持久化了),这时候dump线程会推送二进制日志给slave,如果在这个推送的过程中master主机crash掉了,这时候我们若想让一台slave来做master时,因为事务t1没有在任何的一个slave上存在,也就是这时候事务t1丢失了!
事务的提交主要分为两个主要步骤: 1. 准备阶段(Storage Engine(InnoDB) Transaction Prepare Phase) 此时SQL已经成功执行,并生成xid信息及redo和undo的内存日志。然后调用prepare方法完成第一阶段,papare方法实际上什么也没做,将事务状态设为TRX_PREPARED,并将redo log刷磁盘。 2. 提交阶段(Storage Engine(InnoDB)Commit Phase) 2.1 记录协调者日志,即Binlog日志。 如果事务涉及的所有存储引擎的prepare都执行成功,则调用TC_LOG_BINLOG::log_xid方法将SQL语句写到binlog(write()将binary log内存日志数据写入文件系统缓存,fsync()将binary log文件系统缓存日志数据永久写入磁盘)。此时,事务已经铁定要提交了。否则,调用ha_rollback_trans方法回滚事务,而SQL语句实际上也不会写到binlog。 2.2 告诉引擎做commit。 最后,调用引擎的commit完成事务的提交。会清除undo信息,刷redo日志,将事务设为TRX_NOT_STARTED状态。
半同步复制就是在2.2之后推送了二进制日志到slave!
无损复制
为了防止这一个事务的丢失,MySQL5.7引入了无损复制!
现在我们已经知道,在半同步环境下,主库是在事务提交之后等待Slave ACK,所以才会有数据不一致问题。所以这个Slave ACK在什么时间去等待,也是一个很关键的问题了。因此MySQL针对半同步复制的问题,在5.7.2版本引入了Loss-less Semi-Synchronous,在调用binlog sync之后,engine层commit之前等待Slave ACK。这样只有在确认Slave收到事务Binlog后,事务才会提交。另外,在commit之前等待Slave ACK,同时可以堆积事务,利于Group Commit,有利于提升性能。
半同步复制与无损复制的主要区别在于半同步复制在InnoDB commit后等待Slave ACK(需要收到至少一个Slave节点回复的ACK),无损复制在binlog sync后与Slave确认。虽然都同样避免不了数据丢失的风险,但是由于ack确认的位置不同,这样就有一个大的区别在于其他事务是否看得见这个事务的修改操作,半同步复制由于在InnoDB commit后ack,此时事务已经提交,对其他事务可见,如果此时主库宕机并发生主从切换,那么用户在新主库找不到刚刚那个事务修改后的数据,就可以称得上数据丢失了,因为用户已经看见过。而无损复制由于在binlog sync后进行binlog发送和ack确认,此时由于事务并没有提交,对于其他事务来说不可见,所以就算发生主从切换,新主库虽然也没有刚刚那个事务修改后的数据,但用户并没有看见新数据,所以也就称不上数据丢失了。
需要注意的是无损复制,用户提交的事务写入了二进制日志,但是进行commit提交;也就是MySQL5.7在crash recovery时,主动抛弃了这条可能引起数据库不一致的事务!
两个参数介绍:
rpl_semi_sync_master_wait_for_slave_count:
rpl_semi_sync_master_wait_point:
rpl_semi_sync_master_wait_for_slave_count: MySQL5.7之后加入的,多少个slave确认之后,主才继续下一个二进制日志推送。
rpl_semi_sync_master_wait_point:这个值有两个取值,after-commit和after-sync; after-commit表示的半同步复制,after-sync表示的是无损复制!
半同步复制与无损复制的对比总结:
1. ACK的时间点不同
- 半同步复制在InnoDB层的Commit Log后等待ACK,主从切换会有数据丢失风险。
- 无损复制在MySQL Server层的Write binlog后等待ACK,主从切换不会有数据丢失风险,但是主从有不一致的风险。
2. 主从数据一致性
- 半同步复制意味着在Master节点上,这个刚刚提交的事务对数据库的修改,对其他事务是可见的。因此,如果在等待Slave ACK的时候crash了,那么会对其他事务出现幻读,数据丢失。
- 无损复制在write binlog完成后,就传输binlog,但还没有去写commit log,意味着当前这个事务对数据库的修改,其他事务也是不可见的。因此,不会出现幻读,数据丢失风险。
因此5.7引入了无损复制(after_sync)模式,带来的主要收益是解决after_commit导致的Master crash后数据丢失问题,因此在引入after_sync模式后,所有提交的数据已经都被复制,故障切换时数据一致性将得到提升。
中继日志的回放与写入
SQL线程
当slave的SQL线程从中继日志回放一个事件时,第一会把这个事件在数据库中进行回放,第二会把这个事件结束点二进制信息写入relay-log.info文件中,如果每回放一个事件,就写一次relay-log.info文件,因此磁盘的写入速度比较慢,因此在并发较高的情况下,slave就会产生和主的延迟,MySQL引入了一个参数sync_relay_log_info,这个参数默认值是10000,表示回放10000次时把日志点刷新入文件。
SQL线程回放了中继日志的1,2,3三个事件(这两个事件已经写入了从库),但是在2,3两个事件并没有写入relay_log_info_file文件,这时候如果slave服务器发生crash 重启,这时候slave会重新去抓取2,3两个事件,然后再执行就会发生1062错误。
造成这样主要是因为,回放是写入数据库,而写日志点则是写入file文件的,这两个无法做到一致性。
如果把sync_relay_log_info设置为1时候,还是会有最后一个event重复执行的可能,并且会造成性能下降!
因此从mysql5.6开始:relay_log_info_repository可以设置为TABLE,把中继日志的回放,和中继日志信息的写入放入表中,这样可以把这两个操作设置变成原子性的,就可以避免这种情况的发生!线上环境建议设置为TABLE。
mysql> show variables like "%relay%_log_info%"; +---------------------------+----------------+ | Variable_name | Value | +---------------------------+----------------+ | relay_log_info_file | relay-log.info | | relay_log_info_repository | FILE | #建议设置为table。 | sync_relay_log_info | 10000 | +---------------------------+----------------+ 3 rows in set (0.00 sec)
I/O线程
I/O线程会写入master.info和relay-log-info,若是每拉一个event就写一次,效率会很低,MySQL5.6引入了如下参数!
mysql> show variables like "%master_info%"; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | master_info_repository | FILE | #这个建议设置为table,这样的性能会比file性能高大概2倍左右 | sync_master_info | 10000 | #每拉10000次event写入文件一次 +------------------------+-------+ 2 rows in set (0.00 sec)
master配置: binlog-do-db= binlog-ignore-db= max_binlog_szie=2048M binlog_format=ROW transaction-isolation=READ-COMMITTED expire_logs_days=7 server-id=111 binlog_cache_size= sysnc_binlog=1 # must set to 1, default is 0 innodb_flush_log_at_trx_commit=1 innodb_support_xa = 1 slave配置 log_slave_upates replicate-do-db replicate-ignore-db replicate-do-table replicate-ignore-table server-id master_info_ repository = TABLE relay_log_recovery = 1 #I/O thread crash safe relay_log_info_repository = TABLE # SQL thread crash safe read_only = 1 super_read_only = on #mysql5.7 加入的 relay_log_recovery=1
跳过错误
上面我们搭好了主从的架构!
在主上做如下操作:
mysql> use mytest; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> create table tb1(a int auto_increment primary key); #创建一个自增长的列 Query OK, 0 rows affected (0.04 sec) mysql> insert into tb1 select null; Query OK, 1 row affected (0.02 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into tb1 select null; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into tb1 select null; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into tb1 select null; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into tb1 select null; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into tb1 select null; Query OK, 1 row affected (0.00 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> select * from tb1; +---+ | a | +---+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | +---+ 6 rows in set (0.00 sec)
查看从上的数据
mysql> select * from tb1; #数据已经同步到从上了 +---+ | a | +---+ | 1 | | 2 | | 3 | | 4 | | 5 | | 6 | +---+ 6 rows in set (0.00 sec)
#主从架构中只有在主上写入数据,从上只读数据,在这里我们在从上插入没有。没有设置read_only参数 mysql> insert into tb1 select null; #因为是自增的,所以插入之的数据为7! Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql>
然后我们在主上,再插入一条数据7,
mysql> insert into tb1 select null; #因为自增的,所以实际插入的值为7! Query OK, 1 row affected (0.02 sec) Records: 1 Duplicates: 0 Warnings: 0 #自增主键,在slave上已经插入了一个数值7,这时候主上又同步一个数据7,所以报错,1062错误!
mysql> show slave statusG *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 10.0.102.214 Master_User: repl Master_Port: 3306 Connect_Retry: 60 Master_Log_File: test3-bin.000004 Read_Master_Log_Pos: 9277 Relay_Log_File: test2-relay-bin.000009 Relay_Log_Pos: 4874 Relay_Master_Log_File: test3-bin.000004 Slave_IO_Running: Yes Slave_SQL_Running: No Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 1062 Last_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at master log test3-bin.000004, end_log_pos 9246. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any. Skip_Counter: 0 Exec_Master_Log_Pos: 9019 Relay_Log_Space: 9863 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: NULL Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 1062 Last_SQL_Error: Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at master log test3-bin.000004, end_log_pos 9246. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any. Replicate_Ignore_Server_Ids: Master_Server_Id: 5 Master_UUID: 4687e05d-f37f-11e8-8fc7-fa336351fc00 Master_Info_File: /data/mysql/master.info SQL_Delay: 0 SQL_Remaining_Delay: NULL Slave_SQL_Running_State: Master_Retry_Count: 86400 Master_Bind: Last_IO_Error_Timestamp: Last_SQL_Error_Timestamp: 181202 18:09:40 Master_SSL_Crl: Master_SSL_Crlpath: Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0 Replicate_Rewrite_DB: Channel_Name: Master_TLS_Version: 1 row in set (0.00 sec)
这时候因为我们知道错误的原因,是因为主键重复,解决办法,我们可以让slave机器,忽略这次二进制日志的写入!
mysql> show variables like "%skip%"; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | skip_external_locking | ON | | skip_name_resolve | OFF | | skip_networking | OFF | | skip_show_database | OFF | | slave_skip_errors | OFF | #slave忽略的错误 | sql_slave_skip_counter | 0 | #slave忽略的次数 +------------------------+-------+ 6 rows in set (0.01 sec) mysql> set sql_slave_skip_counter=1; #设置为1,因为是全局变量需要加global! ERROR 1229 (HY000): Variable 'sql_slave_skip_counter' is a GLOBAL variable and should be set with SET GLOBAL mysql> set global sql_slave_skip_counter=1; Query OK, 0 rows affected (0.00 sec) mysql> start slave sql_thread; #重新启动sql线程
Query OK, 0 rows affected (0.01 sec)
mysql> show slave statusG #复制已经恢复正常
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.102.214
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: test3-bin.000004
Read_Master_Log_Pos: 9277
Relay_Log_File: test2-relay-bin.000009
Relay_Log_Pos: 5132
Relay_Master_Log_File: test3-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
.......