与MySQL主从复制,从节点可以分担部分读压力不一样,甚至可以增加slave或者slave的slave来分担读压力,Redis集群中的从节点,默认是不分担读请求的,从节点只作为主节点的备份,仅负责故障转移。
如果是主节点读写压力过大,可以通过增加集群节点数量的方式来分担压力。
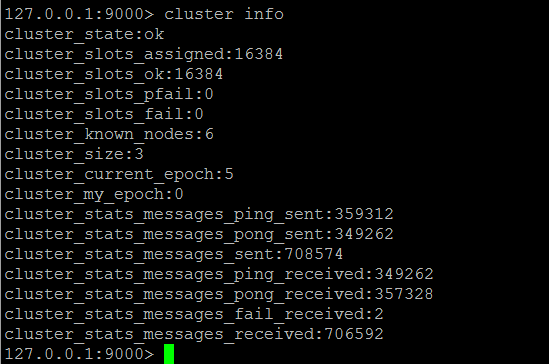
以下简单测试Redis集群读写时候的节点相应情况,节点集群关系如下,三个主节点组成集群,分别对应三个从节点



往集群中写入10W条“字符串类型”的测试数据
#!/usr/bin/env python3 import time from time import ctime,sleep from rediscluster import StrictRedisCluster startup_nodes = [ {"host":"127.0.0.1", "port":9000}, {"host":"127.0.0.1", "port":9001}, {"host":"127.0.0.1", "port":9002}, {"host":"127.0.0.1", "port":9003}, {"host":"127.0.0.1", "port":9004}, {"host":"127.0.0.1", "port":9005} ] redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) for i in range(0, 100000): try: redis_conn.set('name'+str(i),str(i) except: print("connect to redis cluster error") #time.sleep(2)
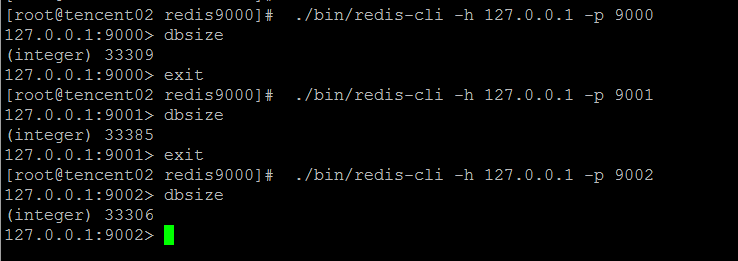
10W个key值基本上均匀地落在三个节点上
连续读数据测试,同时观察某一个主从节点的负载
#!/usr/bin/env python3 import time from time import ctime,sleep from rediscluster import StrictRedisCluster startup_nodes = [ {"host":"127.0.0.1", "port":9000}, {"host":"127.0.0.1", "port":9001}, {"host":"127.0.0.1", "port":9002}, {"host":"127.0.0.1", "port":9003}, {"host":"127.0.0.1", "port":9004}, {"host":"127.0.0.1", "port":9005} ] redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True) for i in range(0, 100000): try: redis_conn.get('name'+str(i)) except: print("connect to redis cluster error") time.sleep(2)
这里以9000和9003集群中的一对主从节点为例,当查询发起时,同时观察这两个节点的负载,
可以发现主节点9000负责处理定位到当前节点的请求,与此同时,而对应的从节点9003则没有处理请求信息。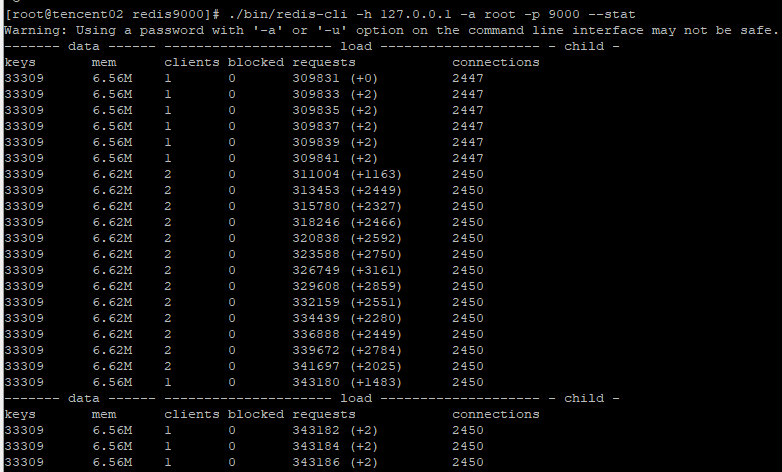
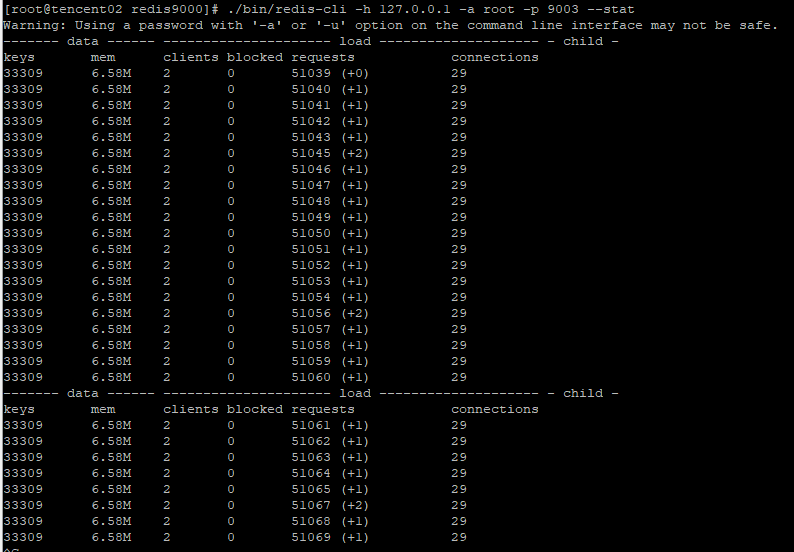
Redis集群中,默认情况下,查询是根据key值的slot信息找到其对应的主节点,然后进行查询,而不会在从节点上发起查询

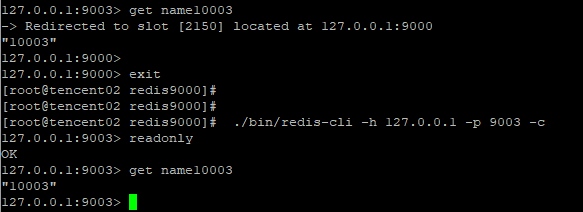
使用readonly命令打开客户端连接只读状态,则从节点可以接受读请求(当然在slave节点上读,因为复制延迟造成的问题另说)
根据https://redis-py-cluster.readthedocs.io/en/master/readonly-mode.html中的说明,
You can overcome this limitation [for scaling read with READONLY mode](http://redis.io/topics/cluster-spec#scaling-reads-using-slave-nodes).
redis-py-cluster also implements this mode. You can access slave by passing readonly_mode=True to StrictRedisCluster (or RedisCluster) constructor.
通过以readonly_mode=True的方式连接至集群,重复一下测试,发现从节点依然没有处理读请求
#!/usr/bin/env python3 import time from time import ctime,sleep from rediscluster import StrictRedisCluster startup_nodes = [ {"host":"127.0.0.1", "port":9000}, {"host":"127.0.0.1", "port":9001}, {"host":"127.0.0.1", "port":9002}, {"host":"127.0.0.1", "port":9003}, {"host":"127.0.0.1", "port":9004}, {"host":"127.0.0.1", "port":9005} ] redis_conn= StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True, readonly_mode=True) for i in range(0, 100000): try: print(redis_conn.get('name'+str(i))) except: print("connect to redis cluster error") time.sleep(2000)
Redis版本为 5.0.4
![]()
不知道为什么slave节点没有请求读处理,观察Redis请求处理的stat状态,依旧重定向到了master节点,不知道是否与单机多实例有关
如果每个实例独立部署在一台机器上,readonly_mode=True的访问模式,slave节点就可以处理读请求?
ps:测试环境是在腾讯云服务器EC2上安装的Redis,如果要在本地访问,需要bind的IP为内网的IP,然后本地用公网IP访问,而不是直接bind公网IP,为此折腾了一阵子。