本文之外可参考另外一篇文章作为补充:http://www.cnblogs.com/wy123/p/6189100.html
在sql server 中,如果一张表存在聚集索引的时候,
大多数情况下,如果进行select * from TableName查询,默认的返回顺序是按照聚集所在列的顺序返回的
但是,在一张表存在聚集索引的时候,并不一定所有的情况都是按照聚集索引列的顺序排列的,
下面开始测试
create table TestDefaultOrder ( Id int identity(1,1) primary key,--主键上默认会建立聚集索引 Col2 char(5), COL3 char(5) ) --写入100000条测试数据 insert into TestDefaultOrder values (SUBSTRING(cast(NEWID() as varchar(50)),1,5),SUBSTRING(cast(NEWID() as varchar(50)),1,5)) go 100000
如下查询完全没有问题,正如你所预料的,按照聚集索引所在的列(Id)排序的,完全没有问题,下面开始切入正题
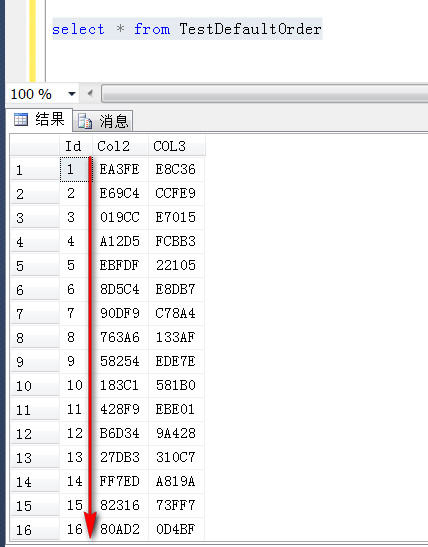
--创建一张同样的对照表 create table TestDefaultOrder_Contrast ( Id int identity(1,1) primary key,--主键上默认会建立聚集索引 Col2 char(5), COL3 char(5) ) --将TestDefaultOrder表中的数据写入进去,目前,两张表的数据和索引结构一模一样 insert into TestDefaultOrder_Contrast (Col2,Col3) select Col2,Col3 from TestDefaultOrder --仅仅在对照表上创建一个非聚集索引,这是唯一的不同点 Create Index idx2 on TestDefaultOrder_Contrast(Col2,Col3)
接下来的查询,或许会有一点一点出乎你的意料,
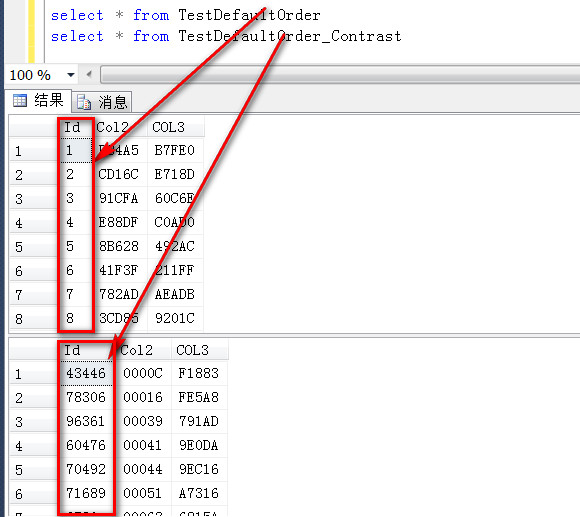
上面说了,两张表的数据是一模一样的,聚集索引结构也是一样的,只是对照表多个一个非聚集索引
发现对照表的结果返回顺序,根本是按照聚集索引的排序返回的
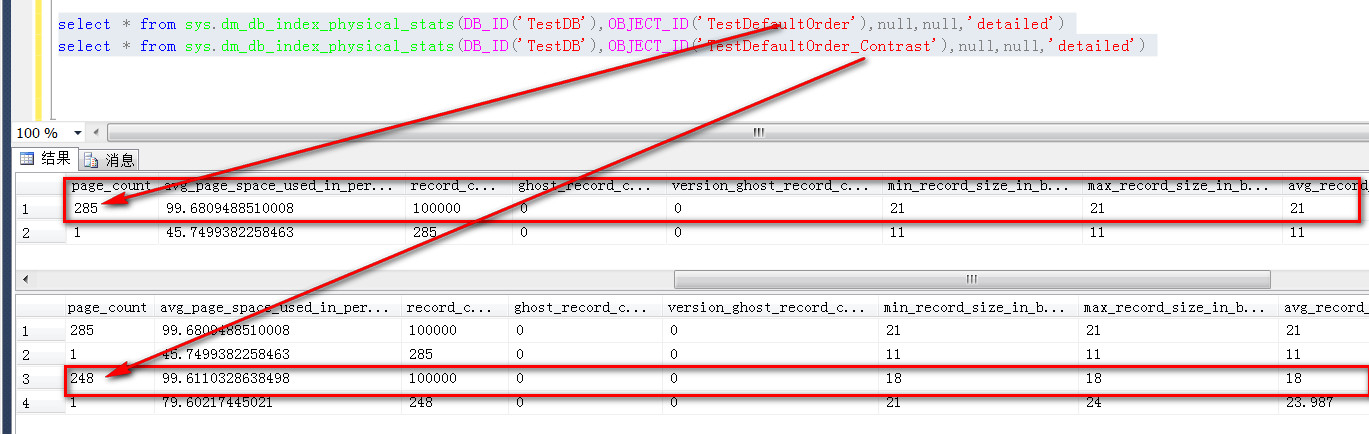
那么原因在哪里呢?我们要从不同类似索引占用的空间情况进行分析,通过dm_db_index_physical_stats发现,在数据数据完全一致的情况下,
因为TestDefaultOrder_Contrast这个表上的非聚集索引,占用的空间更少(248个page,而TestDefaultOrder的聚集索引是285个page),
正因为此,sqlserver在进行全表扫描的时候,会选择一个代价更小的索引(进行扫描),
因为TestDefaultOrder表上只有一个聚集索引,按照聚集索引扫描进行查询,返回的结果的顺序是按照聚集索引列排序的
但是TestDefaultOrder_Contrast就不同了,因为在非聚集索引idx2 上,包含了全部的数据(Col2,Col3以及指向聚集索引键值的Id),
但idx2这个索引是占用的空间更小,所以对于TestDefaultOrder_Contrast的查询,是按照idx2这个非聚集索引进行扫描的
因为,在TestDefaultOrder_Contrast这个表上,
直接select * TestDefaultOrder_Contrast进行查询的话,
跟对表TestDefaultOrder进行 select * TestDefaultOrder查询
是用两种完全不同的方式进行的,出来的结果自然也就不同了

而事实上,sqlserver在对TestDefaultOrder_Contrast进行查询的时候,通过走idx2这个索引扫描,代价确实要比TestDefaultOrder的聚集索引扫描,代价要小

如果有兴趣的话,再次分析为什么存储同样的数据(TestDefaultOrder上的聚集索引和TestDefaultOrder_Contrast的非聚集索引idx2),
TestDefaultOrder表上的聚集索引,要比TestDefaultOrder_Contrast上的idx2(Create Index idx2 on TestDefaultOrder_Contrast(Col2,Col3))占用的空间大呢
这里的原因在于,一个表上的聚集索引(于非聚集索引相比),除了要存储数据,要维护的信息更多的元数据信息,占用的空间自然就较多一点
而sqlserver在进行查询的时候,总是会选择一个代价相对较低的方式。
总结:千万不要以为,只要表上建立了聚集索引,在查询的时候,返回结果的默认的排序方式,是按照聚集索引来的
后记:为什么要研究这个问题?
因为之前遇到过,某些查询没有显式指定排序列,但是借助表上聚集索引,返回结果的时候,会得一个想要的顺序。
这种情况其实会潜在一种问题,如果发生类似上面这种情况,想要对查询结果按照聚集索引的顺序排序,而又不显式制定排序列,查询结果的显示顺序,可就不一定了。