最近发现一个分页查询存储过程中的的一个SQL语句,当聚集索引列的排序方式不同的时候,效率差别达到数十倍,让我感到非常吃惊
由此引发出来分页查询的情况下对大表做Clustered Scan的时候,
不同情况下会选择FORWARD 或者 BACKWARD差别,以及建立聚集索引时,选择索引列的排序方式的一些思考
废话不多,上代码
先建立一张测试表,在Col1上建立聚集索引,写入100W条数据
create table ClusteredIndexScanDirection ( Col1 int identity(1,1), Col2 varchar(50), Col3 varchar(50), Col4 Datetime ) create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC) DECLARE @date datetime,@i int=0 set @date=GETDATE() while @i<1000000 begin insert into ClusteredIndexScanDirection values (NEWID(),NEWID(),DATEADD(MI,@i,GETDATE()-200)) set @i=@i+1 end
先直观地看一下聚集索引扫描时候的FORWARD 和 BACKWARD
BACKWARD
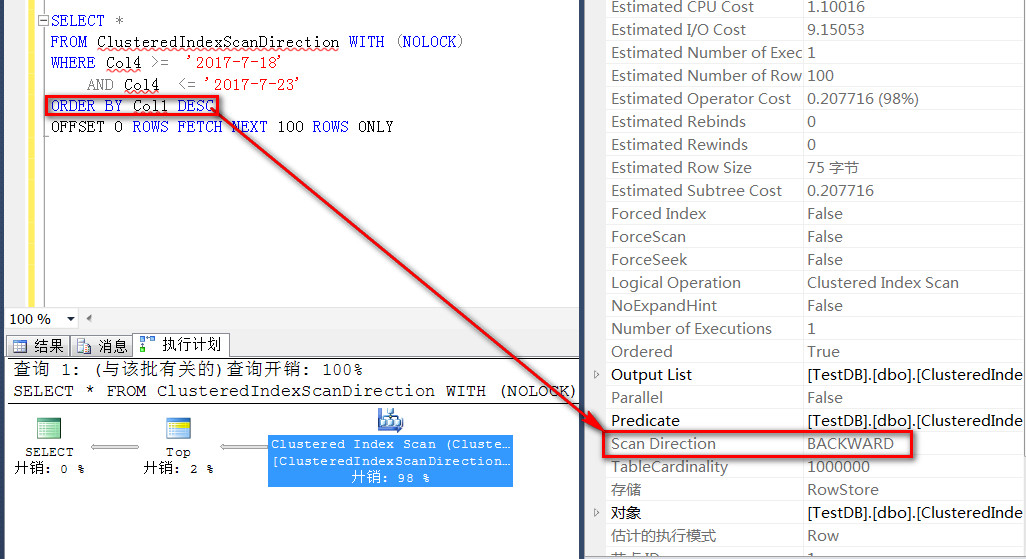
执行如下分页查询,当按照Col4符合2017-7-18和2017-7-23,并且Col1 倒序排序的时候
从执行计划看,Clustered Index Scan的Scan Direction的方式是BACKWARD
FORWARD
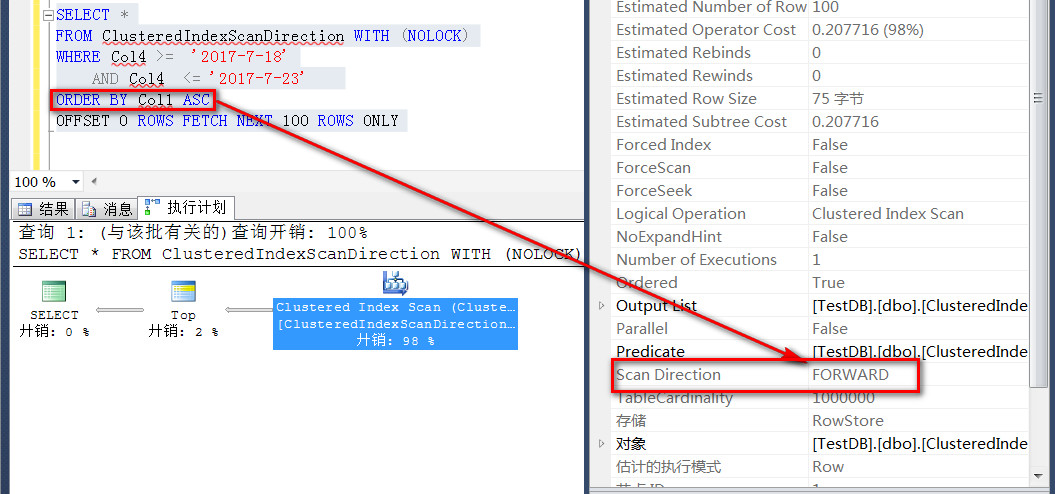
执行如下分页查询,当按照Col4符合2017-7-18和2017-7-23,并且Col1 正序排序的时候
从执行计划看,Clustered Index Scan的Scan Direction的方式是FORWARD
查询条件一样,分页情况下,排序方式不一样,性能上有么有差别?肯定有,太明显了,如果没有,本文也就没有什么意义了
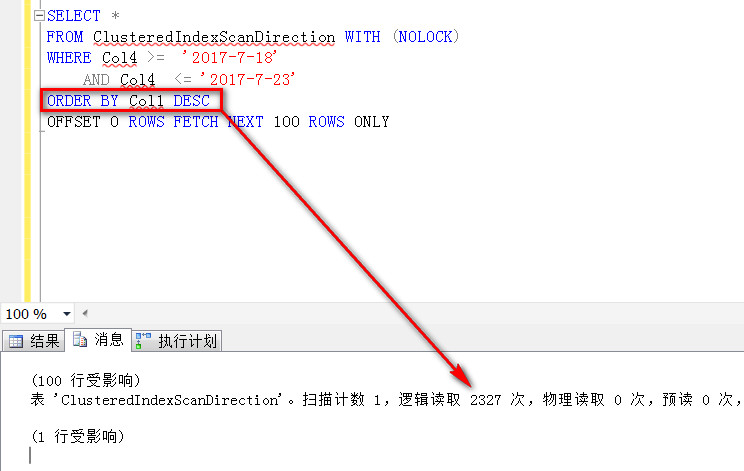
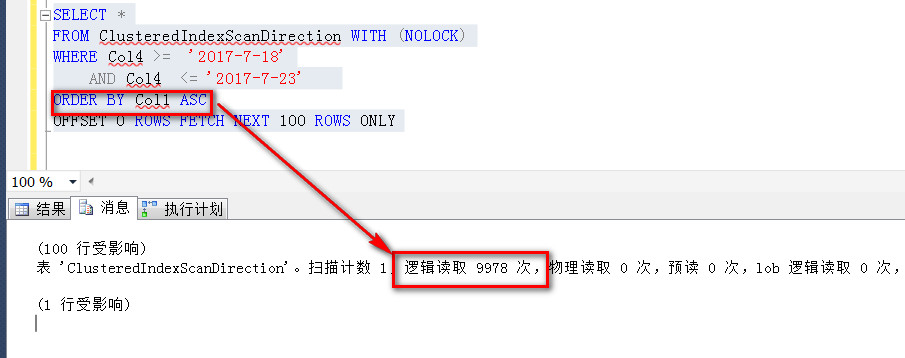
如图是上述两种查询方式在我本机的测试结果,同样是前100条数据,因为排序方式不同,其代价也是不同的
逻辑读,一个是2327,一个是9978次,差别不小吧,在实际场景中,这个差别是非常非常大的,大到足以超乎你想想
对FORWARD和BACKWARD有一个直观的感受之后,来说说这两者的区别
如果了解B树索引结构的话,应该知道聚集索引是以类似于B树结构的方式来组织的,既然是B树结构,
那么下面这个图就不难理解了,
在索引列按照某事方式排序的情况下,比如
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC)
或者是
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 DESC)
下面这张图分别是FORWARD和BACKWARD两种Scan direction的实现方式
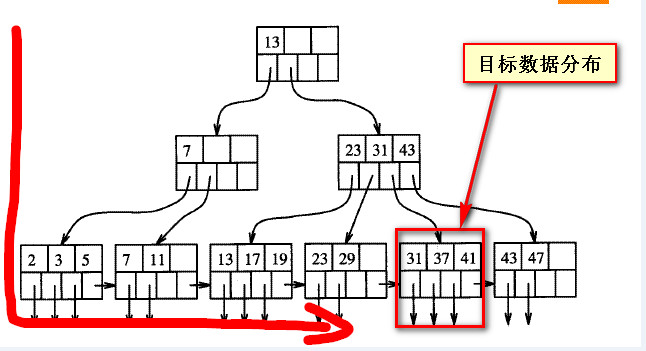
FORWARD
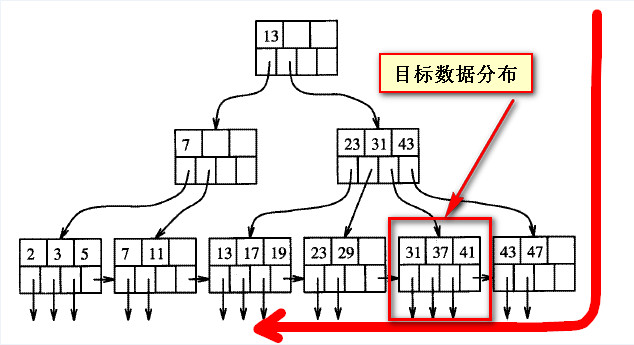
BACKWARD
Sql Server究竟选中哪种方式,是FORWARD还是BACKWARD,是依赖于你的索引情况和查询结果集排序情况的
以我上面的查询为例
如果是按照查询结果正序排序的方式查询
SELECT * FROM ClusteredIndexScanDirection WITH (NOLOCK) WHERE Col4 >= '2017-7-18' AND Col4 <= '2017-7-23' ORDER BY 1 ASC OFFSET 0 ROWS FETCH NEXT 100 ROWS ONLY
也就是要求查询结果的排序方式与聚集索引的排序方式一致,聚集索引是ASC的,Sql Server就会采用FORWARD的方式,
也即是从左到右的Scan方式,找到满足1000条的数据后返回,查询终止
如果是按照查询结果的倒序排序的方式查询
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2017-7-18'
AND Col4 <= '2017-7-23'
ORDER BY 1 DESC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
也就是要求查询结果的排序方式与聚集索引的排序方式不一致,聚集索引是ASC的,Sql Server就会采用BACKWARD的方式,
也即是从右到左的Scan方式,找到满足100条的数据后返回,查询终止
现在就存在一个问题,如果聚集索引是按照ASC正序排列的,也就是说在聚集索引排序一定的情况下,
聚集索引列和查询条件(CreateDate)上的时候都是递增的,也就是说,查询目标数据分布在B树的右边,
(当然这么说不严谨,物理存储中并没有左右的概念,这些都是逻辑上的,并不是完全物理上的概念),
实际业务中,差不多的意思就是查询最近N天的数据
如果查询结果是按照聚集索引正序排序,
Sql Server 采用FORWARD的方式,也即从左至右,那么这个查询就要经历B树种从左到右很大一部分数据扫描之后,才能找到所需要的数据
如果查询结果是按照聚集索引倒叙排序,
Sql Server 采用BACKWARD的方式,也即从右至左,那么这个查询直接从最右边开始Scan,很快就能找到符合条件的100条数据。
聚集索引是ASC或者DESC的方式,也会影响到这个查询,这些概念都是相对的,当然实际场景中,索引情况和查询条件可能更复杂,
可见,一个查询的实现,是通过FORWARD还是BACKWARD,跟聚集索引的排序方式和查询结果的排序方式,以及查询条件都有关。
Sql Server 选择FORWARD或者BACKWARD,本身都没有错,如果出现不同排序方式下性能差别非常大的时候,
就要注意到是不是,聚集索引的方式与查询排序方式之间存在类似上述的问题。
不管是FORWARD或者BACKWARD,避免让Scan整个表的大部分数据才找到符合条件的数据
当然实际情况也比例子中复杂很多,还是那句话,具体情况具体分析。
比如业务系统查询数据时,排序方式是固定的(比如你网购的订单信息,总是按照时间倒叙排列的),当然也不排除其他情况
这就要求我们在创建聚集索引的时候,要考虑到查询的方式以及排序的方式,慎重地作出选择。
总结:
SQLServer在对查询结果排序的查询中,如果扫描的方向与查询结果不一致,需要再次在内存中排序,
因此,大多数情况下,会根据查询结果的排序来执行FORWARD或者BACKWARD操作(当然也不一定百分百)。
本文通过聚集索引Scan的两种方式,FORWARD和BACKWARD,粗浅第分析了表上的聚集索引的排序对查询时的影响,
当然非聚集索引上也会出现FORWARD和BACKWARD扫描的请,
我们在选择聚集索引排序方式的时候,可以考虑到是不是因为FORWARD和BACKWARD的因素,以便进一步的排查确认。
补充:
好吧,算我没说清楚,这里是按照聚集索引排序,按照非索引字段查询,而不是直接按照聚集索引字段查询!!!
我的例子已经写的很清楚了
如果聚集索引建立在一个字段上,也即单字段作为聚集索引,在非聚集索引字段上查询,暂不论这个字段上有没有索引
如果查询结果的跟聚集索引的排序方式是相同的,那么就是FORWARD
如果查询结果的跟聚集索引的排序方式是相反的,那么就是BACKWARD
不管是FORWARD还是BACKWARD,究竟要扫描多大范围才能找到符合条件的数据,
取决于上面说的非聚集索引字段列的数据分布,岂能说“ 正序和倒序无差别”?
其实我更想表达的是,因为结果集的排序,会导致在做聚集索引Scan的时候选择FORWARD或者BACKWARD
FORWARD还是BACKWARD会对查询的效率有较大的影响,
实际应用中太复杂了,当然修改聚集索引的排序方式可以从一定程度上缓解这种问题,我当然测试过,不然也不会乱说
也有其他方法也可以实现,比如暴力地去修改聚集索引列,或者建立复合聚集索引,办法也不仅限于此
如果还有不明白的,可以试试下面这个脚本,可以直接在你机器上执行,看看最后两个查询的IO代价
当然这个例子也比较极端
create table ClusteredIndexScanDirection
(
Col1 int identity(1,1),
Col2 varchar(50),
Col3 varchar(50),
Col4 Datetime
)
create unique clustered index idx_Col1 on ClusteredIndexScanDirection(Col1 ASC)
DECLARE @date datetime,@i int=0
set @date=GETDATE()
while @i<1000000
begin
insert into ClusteredIndexScanDirection values (NEWID(),NEWID(),DATEADD(MI,@i,GETDATE()))
set @i=@i+1
end
set statistics io on
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2016-6-1'
AND Col4 <= '2016-6-15'
ORDER BY Col1 ASC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
SELECT *
FROM ClusteredIndexScanDirection WITH (NOLOCK)
WHERE Col4 >= '2016-6-1'
AND Col4 <= '2016-6-15'
ORDER BY Col1 DESC
OFFSET 0 ROWS FETCH NEXT 1000 ROWS ONLY
20160606再次后记:
A表上的索引大概是这样的:create index idx_date on A(BusinessDate )
这两个大表join,因为结果集的排序与其中一个主表(也是最大的表)的聚集索引一致
一致的话,他就是Forward方式的了,
但是,在逻辑上,最近的数据分布在B树的右边,那就是几乎要遍历整个表才能查询出来符合条件数据
为了避免这个问题,那就先对A表进行查询,将结果放入临时表
select * into #A from A where A.BusinessDate>'2016-6-1' and A.BusinessDate<'2016-6-6'
然后再在#A上建立相关索引,在跟其他表join,绕开直接join时走index Forward的方式进行查询
当然实际问题没这么简单,原始查询20多秒,采用这种方式优化后2s,差不多有十几倍的提高,效果还是比较明显的。