本文出处:http://www.cnblogs.com/wy123/p/6189100.html
标题有点拗口,来源于一个开发人员遇到的实际问题
先抛出问题:一个查询没有明确指定排序方式,那么,第二次执行这个同样的查询的时候,查询结果会不会与第一次的查询结果排序方式完全一样?
答案是不确定的,两个完全一样的查询,结果也完全一样,两次(多次)查询结果的排序方式有可能一致,有可能不一致。
如果不一致,又是什么原因导致同样的查询默认排序方式不一致?
以下简单分析几种情况,说明为什么查询同样的查询会出现默认排序结果不一样的情况。当然对于该问题,包含但不限于以下几种情况。
场景1:并行查询导致默认结果集的排序是随机的
按照惯例,先造一个表供测试
create table TestDefaultOrder1 ( id int identity(1,1) primary key, col2 varchar(50), col3 varchar(50), col4 varchar(50), col5 varchar(50), col6 varchar(50), col7 varchar(50), col8 varchar(50), CreateDate Datetime ) go declare @i int =0 begin tran while @i<500000 begin insert into TestDefaultOrder1 values (NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),NEWID(),GETDATE()-RAND()*500) set @i=@i+1 end commit
测试场景:
这里先不考虑索引之类的性能问题,
如图是一个测试结果的示例,可以看到,两个查询的条件是完全一样的,都没有显式指定排序列,默认结果的排序是完全不一样的
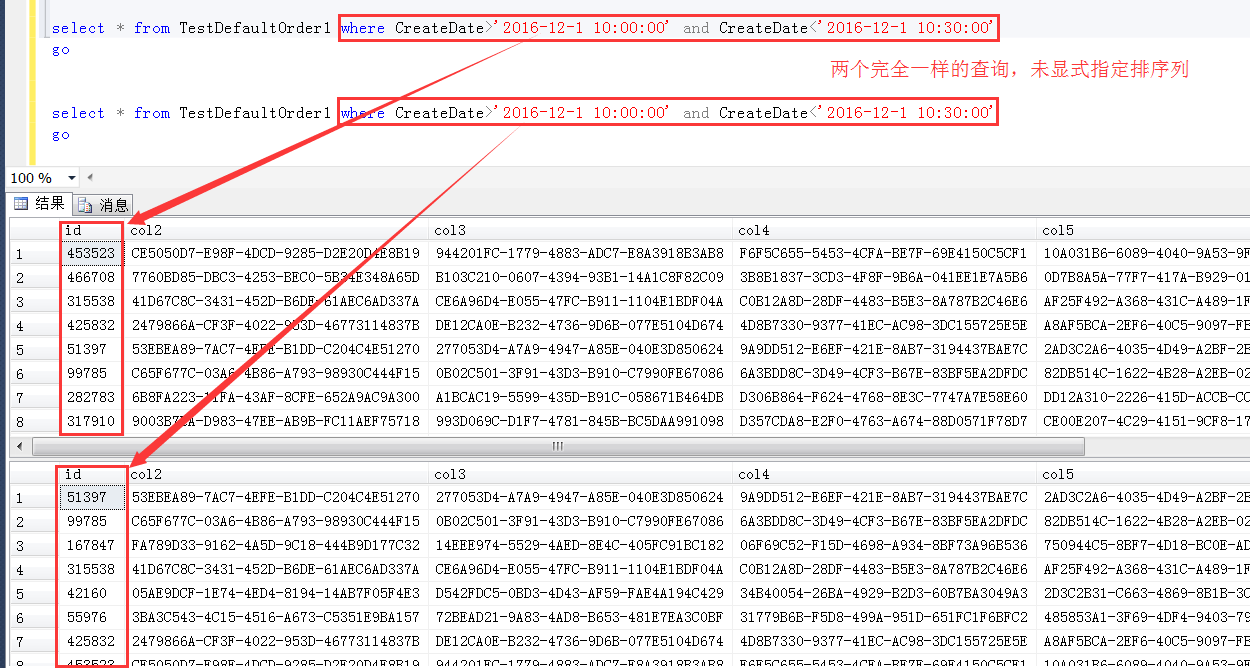
甚至可以用同样的条件做三次查询(可以更多次),结果依然都是完全不一致的

原因分析:
为什么一样的查询,每次查询结果的排序都不一样,正如上面所说,这种情况下是并行查询导致的。
查询引擎采用什么样的执行计划是基于代价考虑的,如果一旦发现一个查询的执行代价超过一定的阈值,就有可能采用并行的方式来处理,
如果采用了并行查询的方式,就会采用多个线程来分解整个查询任务,而每一个线程分配的任务量是无法固定的,同时,合并每个线程的结果顺序也是不固定的
这就导致了最终的查询结果的顺序是不固定的。
截图即为并行查询的每个线程分配的任务量示例。
如图,当前这个查询,第一个线程返回的行数是2,但是无法保证第二次查询的第一个线程返回的行数也是2,
即便是第二次返回的行数是2,也无法保证返回的2行与第一次返回的两行数据一样的
同时,在合并各个线程的结果集的时候,依据线程返回的时间来的,理论上讲也是不确定的,多个不确定因素在一起,就造成了最终的结果集排序(可以认为)是随机的。

有人说,只要执行计划一样,查询默认排序就一样,其实也是不对的,因为即便是执行计划一样,只要SQLServer开启了并行查询,默认排序都是无法保证一直的
场景2:物理存储导致默认结果的随机性
同样,先造一个测试数据的case,如下,创建一个堆表,
create table TestDefaultOrder2 ( id int identity(1,1), col2 char(5000) ) go declare @i int =0 begin tran while @i<50 begin insert into TestDefaultOrder2 values (NEWID()) set @i=@i+1 end commit
测试场景:
这个场景排除了上述并行查询的影响,因为只有50条数据,根本不会启用并行查询
如截图,两次查询之间执行了一次表的重建动作,同样是数据本身没有发生任何变化,两次查询的默认顺序完全不一样
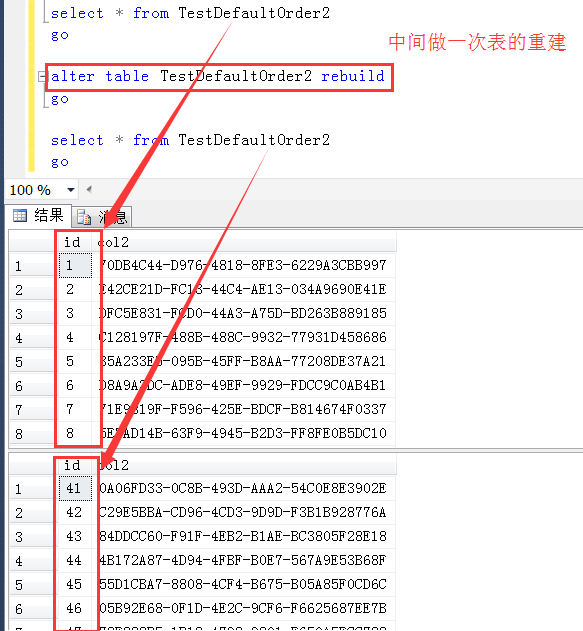
甚至在重建一次,查询结果仍然与上面两次还是都不一样的。
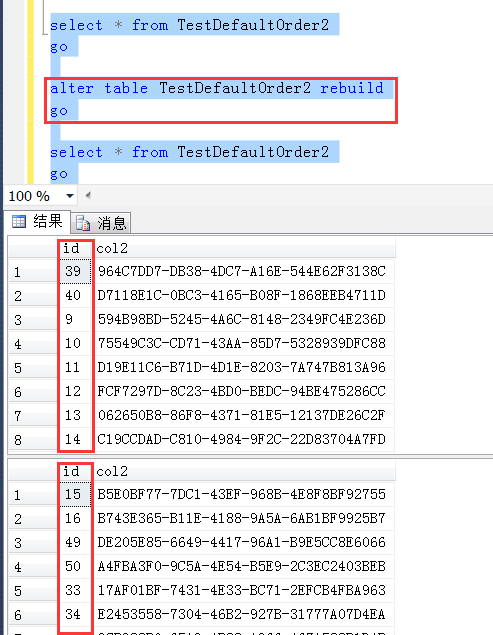
原因分析:
堆表的特点决定了堆内的数据行和数据页没有任何固定的顺序,整个堆内的数据在物理存储发生了变化之后,
在对查询(对堆表扫描)的过程中得不到一个与物理存储变化之前完全一样的顺序。
除了上述的重建表会导致查询的默认顺序不一致,其他影响物理空间的操作,都会影响堆表数据页面的物理存储位置,
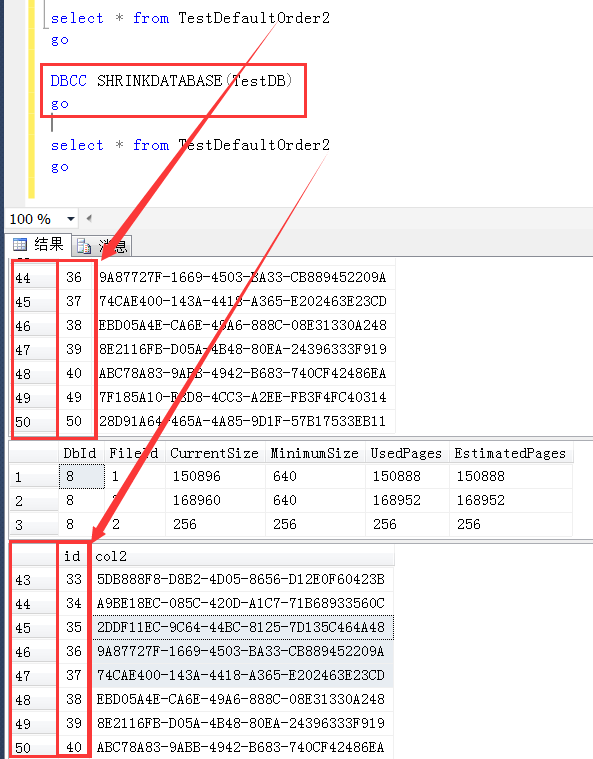
比如这里再执行一次数据库的收缩,收缩之后的查询与收缩之前的查询顺序依旧是不一样的,我可没有动你表和你表中的任何一条数据,但你不能阻止我正常的数据库维护操作。
总之,一旦影响到物理存储位置,堆表的默认扫描结果顺序都有可能不一样。
以上仅仅通过单表查询来说明,如果未显式指定排序方式,即便是同样的查询条件,查询结果的顺序是无法保证每次都一致的,
如果是多表关联,或者是考虑到索引,数据库维护等操作,情况将变得更加复杂,比如这个也比较有意思:http://www.cnblogs.com/wy123/p/5425946.html
比较特殊的是:没有显式指定排序方式,
1,某段一个时间段内,查询结果可能是按照预期结果排序的,某个时间段内就不是了(物理存储改变的影响);
2,某些查询条件下是按照预期结果排序的,改变一下查询条件,排序结果就变得面目全非了(执行计划改变的影响)。
总之一句话:没有显式执行排序方式,不要期待查询结果每次都是预期的排序方式,甚至每次都不一样。
总结:
本文通过两个简单的示例,
从执行计划和物理存储两个方面,说明了“如果查询SQL没有显式指定排序方式,查询结果的顺序是无法保证总是按照你的预期来的”。
当然也不能局限于这两种情况,极有可能还有很多原因是我没有想到的。
然而话不能说死,某些条件下没有显式指定排序方式,一定条件下(多次查询)可能会得到预期的排序结果,但是这种期待往往是不可靠的。
“昨天系统查询结果的排序还是好好的,今天怎么变了?”
“为啥我用A条件查询是按照时间排序的,按照B条件查询就不是了?”
如果没有显式指定排序方式,不要问我数据库是不是有问题(或者说SQL Server这个数据库“不行”,或者说DBA说是内部原因是忽悠人的)。
所以同学,如果期望查询结果排序,不管默认是不是你预期的排序方式,都请显式指定排序方式。