本文出处:http://www.cnblogs.com/wy123/p/6908377.html
NTILE函数可以按照指定的排序规则,对数据按照指定的组数(M个对象,按照某种排序分N个组)进行分组,可以展现出某一条数据被分配在哪个组中.
不仅可以单单利用这个特性,还可以借助该特实现更加有意思的功能.
NTILE的基本使用
NTILE的作用是对数据进行整体上的分组,比如有60个学生,按照成绩分成“上中下”三个级别,可以看出那些人位于哪个级别,用NTILE函数就可以实现。
比如这里的简单的示例,有六个学生,按照成绩,分成三组,可以看到,每个人位于哪一组中(或者说哪个人位于哪个层次)
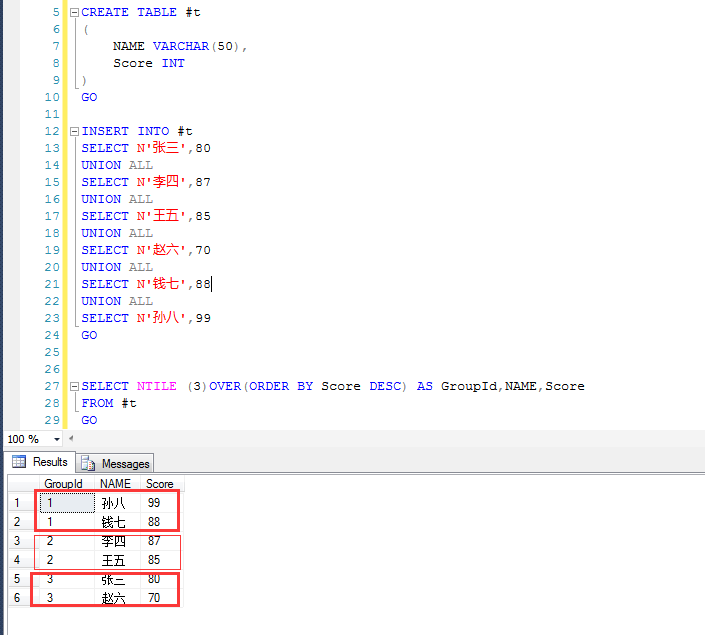
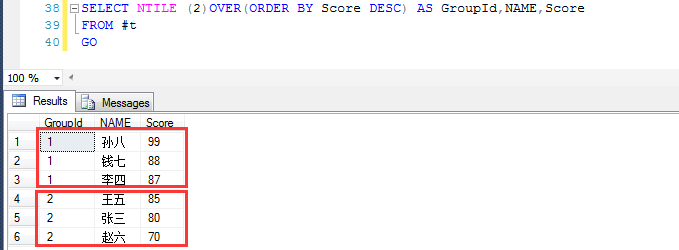
当然也可以分成两组,分组和排序方式由NTILE (N)OVER(ORDER BY *** ASC | DESC) 决定
在NTILE的分组功能上扩展
当然这个应用还可以扩展,借助其扩展功能,可以完成很多个性化的需求。
最近遇到一个需求,要处理一批历史数据,目的是根据其Id,经过一系列的逻辑运算(存储过程实现),计算生成这个Id的某些属性,
正常情况下是循环表中的每一行数据,分别传入存储过程进行处理。
/*
DECLARE @id INT = 0
DECLARE @achived bit = 1
while @achived>0
begin
select top 1 @id = id from business_table order by id
insert into deal_result
exec deal_procrdure @id
delete from t where business_table = @id
if exists (select 1 from t)
set @achived = 1
else
set @achived = 0
end
*/
但是考虑到business_table的数据量太大,单个Session运算起来可能要花费太久的时间,
因此要考虑使用多个Session,每个Session分别计算一部分数据,这样就可以加快数据的生成效率。
比如有1000W行数据,使用10个Session,每个Session计算100W行,这样比一个Session计算1000W行数据,理论上要快10倍
那么这里就涉及到一个分组的问题,鉴于数据的特点,其Id是唯一的但不连续的,
比如要分成10组,如何通过Id的范围,确保每组的数据量基本上相同?
一开始是采用比较笨的方法,利用top,比如前100W行数据,可以这样
select max(id) from
(
select top 100W from t
)t
通过这样,如果最大的id为Id1,那么前100W行的数据范围为0~Id1。
对于第二个100W行的数据,可以计算前200W行的max(id)
select max(id) from
(
select top 200W from t
)t
如果最大的id为Id2,那么第二个100W行的数据范围为Id1~Id2。
然后依次类推,是有点笨……
类似需求可以通过上面提到的NTILE分析函数实现
先上个实例代码,模拟上文提到的Business_table Id唯一但是不连续的情况
DECLARE @i INT = 0 WHILE @i<200000 BEGIN INSERT INTO TestNtile VALUES (@i,NEWID()) set @i=@i+1 END GO --随机删除部分数据,模拟Id不是连续的 ;WITH del AS ( select top 100 * from TestNtile order by NEWID() ) DELETE FROM del GO --通过NTILE分成十个组,取每个组的最大值 SELECT GroupId,MAX(Id) AS Id FROM ( select NTILE (10)over(order by Id) as GroupId,Id from TestNtile )t GROUP BY GroupId GO
原理正如备注中的写的,利用NTILE函数,对数据整体上分成10组,取每个组的最大值,就可以确定每个组的Id的区间范围了。
参考下图,将测试数据分成10组,分别取得每个组的最大Id值,就可以确定每个组的Id的范围了。
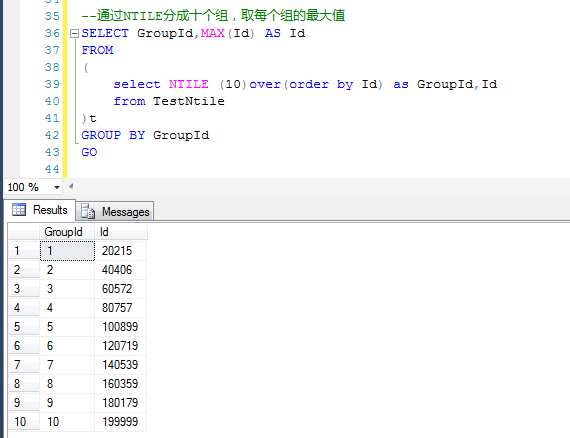
这样就很容易确定,第一组的Id的范围是0~20215,第二组的范围是20216~40406,第三组的范围是40406~60572……
计算出来范围之后,可以通过启动多个Session来循环计算,或者是交给应用程序的多个线程,让每个线程分别处理每一个范围内的Id
很基础的问题,就不总结了。