原文转自: 作者:Blue_Eye https://www.jianshu.com/p/2b6658ad59b3
Linux性能分析概要
1. 性能指标
linux性能指标.png
性能问题的本质 ,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。找出应用或系统的瓶颈,并设法去避免或者缓解它们 ,从而更高效地利用系统资源处理更多的请求。这包含了一系列步骤,比如:
选择指标评估应用程序和系统的性能
为应用程序和系统设置性能目标
进行性能基准测试
性能分析定位瓶颈
优化系统和应用程序
性能监控和告警
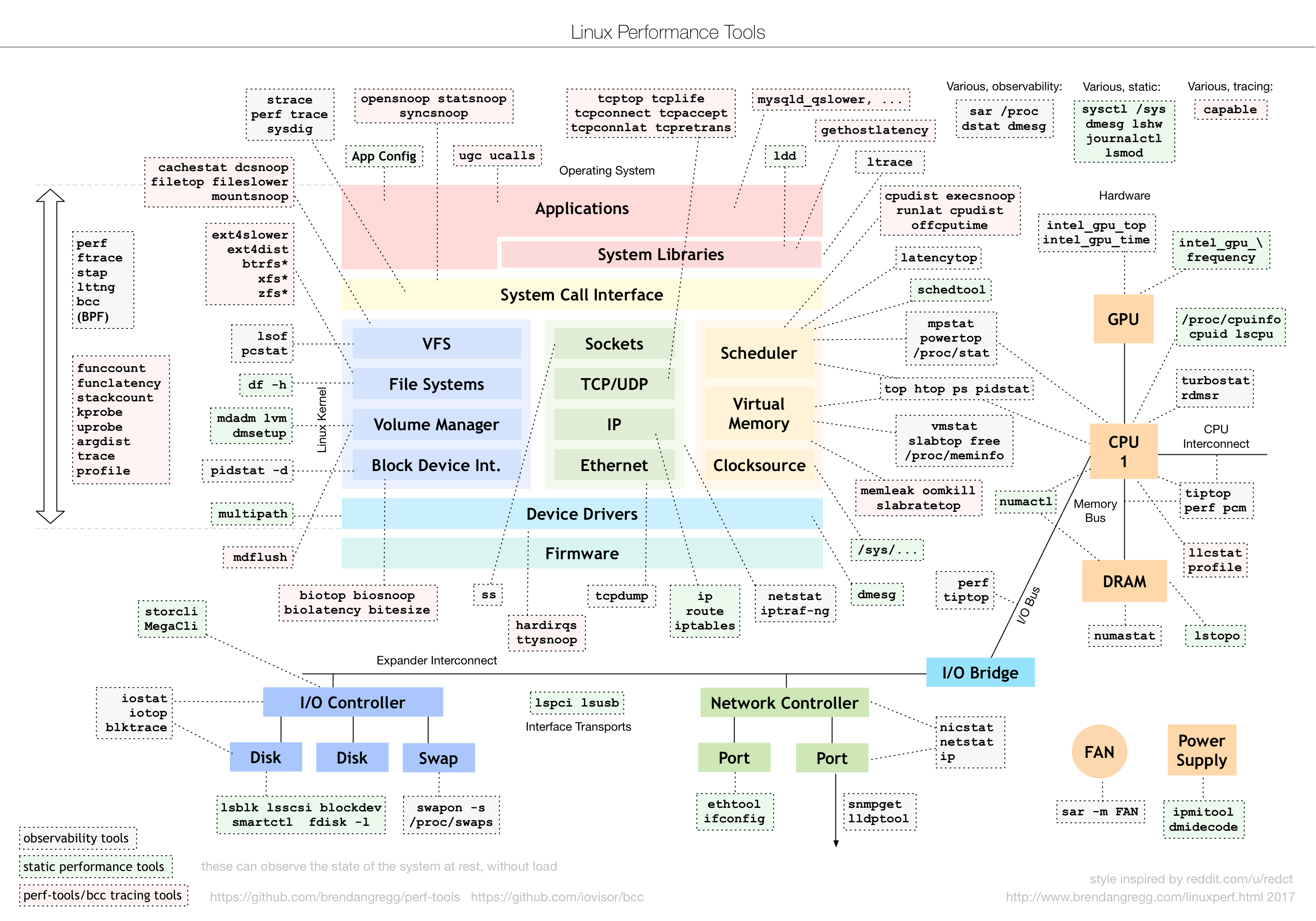
2. linux性能工具图谱
linux性能工具图谱.png
3. linux性能优化思维导图
linux性能优化思维导图.png
平均负载
1. 什么是平均负载?
平均负载:单位时间内,系统处于可运行状态 和不可中断状态 的平均进程数,也就是平均活跃进程数 , 它和 CPU 使用率并没有直接关系。
可运行状态的进程 : 正在使用 CPU 或者正在等待 CPU 的进程,也就是我们常用 ps 命令看到的处于 R 状态(Running 或 Runnable) 的进程。不可中断状态的进程 : 正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的 I/O 响应, 也就是我们在 ps 命令中看到的 D
状态(Uninterruptible Sleep, 也称为 Disk Sleep) 的进程。
2. 平均负载为多少时合理
平均负载最理想的情况是等于 CPU 个数。
$ grep 'model name' / proc/ cpuinfo | wc - l
2
uptime 给了我们三个不同时间间隔的平均值,给我们提供了分析系统负载趋势 的数据来源,让我们更全面、更立体地理解目前的负载情况。
1 分钟、5 分钟、15 分钟 的三个值基本相同,或者相差不大,说明系统负载很平稳。
如果1 分钟的值远小于15 分钟 的值,说明系统最近 1分钟的负载在减少,而过去15 分钟内却有很大的负载
如果1 分钟 的值远大于 15 分钟的值,就说明最近 1 分钟的负载在增加。一旦 1 分钟的平均负载接近或超过了 CPU
的个数,就意味着系统正在发生过载的问题。
3. 平均负载与CPU使用率
平均负载不仅包括了正在使用 CPU 的进程,还包括了 等待CPU 和等待 I/O 的进程。
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
4. 检查平均负载的工具
uptime: 当前时间、系统运行时间、正在登录用户数、过去1分钟、5分钟、15分钟的平均负载
$ uptime
00 : 19 : 43 up 2 min, 1 user, load average: 3.15 , 1.54 , 0.60
$ watch - d uptime
Every 2.0 s: uptime Wed Dec 26 00 : 21 : 14 2018
00 : 21 : 14 up 3 min, 1 user, load average: 0.87 , 1.23 , 0.58
$ mpstat - P ALL 5
Linux 4.15 .0 - 42 - generic ( c5220056- VirtualBox ) 12 / 26 / 2018 _x86_64_ ( 2 CPU )
12 : 22 : 14 AM CPU % usr % nice % sys % iowait % irq % soft % steal % guest % gnice % idle12 : 22 : 19 AM all 4.55 0.00 3.31 0.00 0.00 0.21 0.00 0.00 0.00 91.93 12 : 22 : 19 AM 0 4.32 0.00 3.50 0.00 0.00 0.00 0.00 0.00 0.00 92.18 12 : 22 : 19 AM 1 4.80 0.00 2.92 0.00 0.00 0.42 0.00 0.00 0.00 91.86
# 间隔 5 秒后输出一组数据- u 5 1 4.15 .0 - 42 - generic ( c5220056- VirtualBox) 12 / 26 / 2018 x86_64 ( 2 CPU)
12 : 24 : 54 AM UID PID % usr % system % guest % CPU CPU Command12 : 24 : 59 AM 0 1392 0.00 0.20 0.00 0.20 1 kworker/ u4: 25 12 : 24 : 59 AM 0 5863 0.00 0.20 0.00 0.20 0 dockerd12 : 24 : 59 AM 0 6097 0.00 0.20 0.00 0.20 1 docker- containe12 : 24 : 59 AM 0 7341 1.20 2.20 0.00 3.39 1 Xorg12 : 24 : 59 AM 1000 8425 7.78 0.60 0.00 8.38 1 compiz12 : 24 : 59 AM 1000 8500 0.20 0.00 0.00 0.20 1 vmtoolsd12 : 24 : 59 AM 1000 8808 0.80 0.20 0.00 1.00 0 gnome- terminal- 12 : 24 : 59 AM 1000 9563 0.00 0.40 0.00 0.40 0 pidstat
Average: UID PID % usr % system % guest % CPU CPU Command: 0 1392 0.00 0.20 0.00 0.20 - kworker/ u4: 25 : 0 5863 0.00 0.20 0.00 0.20 - dockerd: 0 6097 0.00 0.20 0.00 0.20 - docker- containe: 0 7341 1.20 2.20 0.00 3.39 - Xorg: 1000 8425 7.78 0.60 0.00 8.38 - compiz: 1000 8500 0.20 0.00 0.00 0.20 - vmtoolsd: 1000 8808 0.80 0.20 0.00 1.00 - gnome- terminal- : 1000 9563 0.00 0.40 0.00 0.40 - pidstat
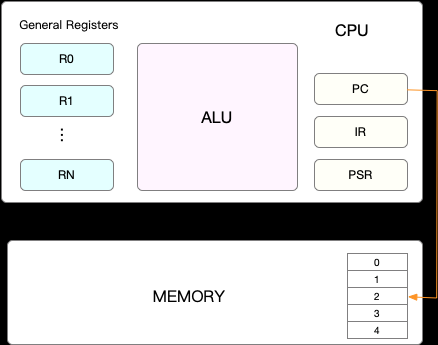
CPU 的上下文切换 在每个任务运行前, CPU 都需要知道任务从哪里加载、又从哪里开始运行、也就是说,需要系统事先给他设置好 CPU 寄存器和程序计数器 (Program Counter, PC)CPU 寄存器 :是 CPU 内置的容量小、但速度极快的内存。程序计数器 :是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。CPU 上下文 。
CPU 上下文.png
上下文切换 :就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
进程上下文切换 、线程上下文切换 以及中断上下文切换 。
1. 进程上下文切换 Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间
进程上下文切换和系统调用的区别 包括了虚拟内存、栈、全局变量等用户空间的资源 ,还包括了内核堆栈、寄存器等内核空间的状态 。
进程上下文切换,是指从一个进程切换到另一个进程进行。 系统调用过程中一直是同一个进程在运行。 因此,进程的上下文切换比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一个进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
进程上下文切换.png
什么时候会切换进程上文
进程执行终止,它之前使用的 CPU 会释放出来,这时再从就绪队列里,拿一个新的进程过来运行。 当某个进程的时间片耗尽了,就会被系统挂起,切换到其他正在等待 CPU 的进程进行 进程在系统资源不足(比如内存不足)时,等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断程序服务。 2. 线程上下文切换 线程和进程的区别
线程是调度的基本单位,而进程则是资源拥有的基本单位。 当进程只有一个线程时,可以认为进程就等于线程。 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。 线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。 线程的上下文切换两种情况
前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样的。 前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。 3. 中断上下文切换 中断处理会打断进程的正常调度和执行。在打断其他进程时,需要将进程当前的状态保存下来,中断结束后,进程仍然可以从原来的状态恢复运行。
进程上下文切换和中断上下文切换的区别
中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必须的状态,包括 CPU 对同一个 CPU 来说,中断处理比进程拥有更高的优先级。 进程上下文切换和中断上文切换的相同之处
都需要消耗CPU,切换次数过多会耗费大量 CPU,甚至严重降低系统的整体性能。 4. CPU 上下文切换小结 CPU 上下文切换,是保证 Linux 系统正常工作的核心功能之一,一般情况下不需要我们特别关注。 但过多的上下文切换,会把 CPU 时间消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,从而缩短进程真正运行的时间,导致系统的整体性能大幅下降。 如何查看系统的上下文切换情况 vmstat:常用的系统性能分析工具,主要用来分析系统的内存使用情况,也常用来分析 CPU 上下文切换和中断次数。cs (context switch):每秒上下文切换的次数。in (interrupt):每秒中断的次数。r (Running or Runnable) :就绪队列的长度,也就是正在运行和等待 CPU 的进程数。b (Blocked):处在不可中断睡眠状态的进程数。# 每隔 5 秒输出 1 组数据5 -- -- -- -- -- - memory-- -- -- -- -- -- - swap-- -- -- - io-- -- - system-- -- -- -- cpu-- -- - in cs us sy id wa st0 0 0 5014224 290736 2060812 0 0 33 37 100 327 6 1 92 0 0 1 0 0 5014204 290736 2060844 0 0 0 0 321 926 4 1 95 0 0 注:vmstat 只给出了系统总体的上下文切换情况
pidstat -w:查看每个进程的上下文切换情况cswch:每秒自愿上下文切换(voluntary context switches) 的次数。nvcswch:每秒非自愿上下文切换(non voluntary context switches) 的次数。自愿上下文切换:进程无法获取所需资源,导致的上下文切换。比如, I/O、内存等系统资源不足时。 非自愿上下文切换:进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如,大量进程都在争抢 CPU 时。 # 每隔 5 秒输出 1 组数据- w 5 4.15 .0 - 42 - generic ( c5220056- VirtualBox) 12 / 26 / 2018 x86_64 ( 2 CPU)
05 : 47 : 58 AM UID PID cswch/ s nvcswch/ s Command05 : 48 : 03 AM 0 7 0.20 0.00 ksoftirqd/ 0 05 : 48 : 03 AM 0 8 15.57 0.00 rcu_sched05 : 48 : 03 AM 0 11 0.20 0.00 watchdog/ 0 05 : 48 : 03 AM 0 14 0.20 0.00 watchdog/ 1
注:pidstat默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标。
/proc/interrupts:查看中断发生的类型- d cat / proc/ interrupts根据上下文切换的类型做具体分析
自愿上下文切换变多,说明进程都在等待资源,有可能发生 I/O 等其他问题 非自愿上下文切换变多,说明进程都在被强制调度,也就是都在争抢CPU,说明CPU的确成了瓶颈 中断次数变多,说明 CPU 被中断处理程序占用,还需要通过查看 /proc/interrupts 文件来分析具体的中断类型。 CPU 使用率 查看/proc/stat,提供的是系统的 CPU 和任务统计信息。
第一行没有编号的 cpu 表示的是所有 CPU 的累加 其他列则表示不同场景下 CPU 的累加节拍数,单位是USER_HZ, 也就是 10 ms(1/100秒) $ cat /proc/stat |grep ^cpuCPU使用率相关的重要指标
user(us),代表用户态 CPU 时间。nice(ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。nice 可取值范围是 -20system (sys),代表内核态 CPU 时间。idle(us),代表空闲时间。注意,这里它不包括等待 I/O 的时间(iowait)。iowait(wa),代表等待 I/O 的 CPU 时间。irq(hi),代表处理硬中断的 CPU 时间softirq(si),代表处理软中断的CPU 时间。steal(st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。guest(guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间 giest_nice(gnice),代表以低优先级运行虚拟机的时间。CPU使用率的计算
CPU使用率的计算公式.png
查看 CPU 使用率
top:显示系统总体的CPU 和内存使用情况,以及各个进程的资源使用情况。ps:只显示了每个进程的资源使用情况。top 的输出:
# 默认每 3 秒刷新一次- 14 : 15 : 36 up 1 : 05 , 1 user, load average: 0.27 , 0.22 , 0.15 : 248 total, 1 running, 179 sleeping, 0 stopped, 0 zombie% Cpu ( s) : 1.2 us, 0.7 sy, 0.0 ni, 98.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st: 8168764 total, 6196696 free, 810812 used, 1161256 buff/ cache: 2095100 total, 2095100 free, 0 used. 7016500 avail Mem
PID USER PR NI VIRT RES SHR S % CPU % MEM TIME+ COMMAND8455 c5220056 20 0 1395968 229828 81832 S 3.0 2.8 4 : 44.39 compiz6739 root 20 0 472636 106196 35576 S 1.7 1.3 0 : 30.13 Xorg8751 c5220056 20 0 595952 35720 28220 S 0.7 0.4 0 : 01.41 gnome- terminal- 6033 root 20 0 568528 68736 39208 S 0.3 0.8 0 : 11.10 dockerd10547 c5220056 20 0 49020 3868 3132 R 0.3 0.0 0 : 00.02 top1 root 20 0 185428 6020 3968 S 0.0 0.1 0 : 04.82 systemd2 root 20 0 0 0 0 S 0.0 0.0 0 : 00.03 kthreadd4 root 0 - 20 0 0 0 I 0.0 0.0 0 : 00.00 kworker/ 0 : 0 H6 root 0 - 20 0 0 0 I 0.0 0.0 0 : 00.00 mm_percpu_wq7 root 20 0 0 0 0 S 0.0 0.0 0 : 00.31 ksoftirqd/ 0 8 root 20 0 0 0 0 I 0.0 0.0 0 : 01.22 rcu_sched9 root 20 0 0 0 0 I 0.0 0.0 0 : 00.00 rcu_bh10 root rt 0 0 0 0 S 0.0 0.0 0 : 00.03 migration/ 0 11 root rt 0 0 0 0 S 0.0 0.0 0 : 00.01 watchdog/ 0 12 root 20 0 0 0 0 S 0.0 0.0 0 : 00.00 cpuhp/ 0 . . .
# 每隔 1 秒输出一组数据,共输出 2 组1 2 4.15 .0 - 43 - generic ( c5220056- VirtualBox) 12 / 27 / 2018 x86_64 ( 2 CPU)
02 : 17 : 31 PM UID PID % usr % system % guest % CPU CPU Command02 : 17 : 32 PM 0 6739 0.99 1.98 0.00 2.97 0 Xorg02 : 17 : 32 PM 1000 8455 8.91 0.00 0.00 8.91 1 compiz02 : 17 : 32 PM 1000 8751 0.00 0.99 0.00 0.99 1 gnome- terminal- 02 : 17 : 32 PM 1000 10558 0.00 0.99 0.00 0.99 1 pidstat
02 : 17 : 32 PM UID PID % usr % system % guest % CPU CPU Command02 : 17 : 33 PM 0 6739 0.00 4.00 0.00 4.00 1 Xorg02 : 17 : 33 PM 1000 8455 11.00 2.00 0.00 13.00 0 compiz02 : 17 : 33 PM 1000 8751 2.00 0.00 0.00 2.00 1 gnome- terminal- 02 : 17 : 33 PM 1000 10558 0.00 1.00 0.00 1.00 1 pidstat
Average: UID PID % usr % system % guest % CPU CPU Command: 0 6739 0.50 2.99 0.00 3.48 - Xorg: 1000 8455 9.95 1.00 0.00 10.95 - compiz: 1000 8751 1.00 0.50 0.00 1.49 - gnome- terminal- : 1000 10558 0.00 1.00 0.00 1.00 - pidstat
查看占用CPU的是代码里的哪个函数
perf top 实时展示系统性能Overhead:是该符号的性能事件在所有采样中的比例,用百分比来表示。Shared:该函数或指令所在的动态共享对象(Dynamic Shared Object),如内核、进程名、动态链接库名、内核模块名等。Object:动态共享对象的类型。比如[.] 表示用户空间的可执行程序、或者动态链接库,而[k]则表示内核空间。Symbol:函数名。当函数名未知时,用十六进制的地址来表示。 Samples: 2 K of event 'cycles:ppp' , Event count ( approx. ) : 1330995812 9.20 % [ kernel] [ k] module_get_kallsym3.96 % [ kernel] [ k] vsnprintf2.73 % [ kernel] [ k] format_decode2.73 % perf [ . ] 0x00000000001ea373 1.89 % [ kernel] [ k] number 1.88 % [ kernel] [ k] kallsyms_expand_symbol. constprop. 1 1.69 % perf [ . ] 0x00000000001f6368 1.69 % [ kernel] [ k] memcpy_erms1.43 % perf [ . ] 0x00000000001f77d0 1.34 % libc- 2.27 . so [ . ] __libc_calloc1.24 % [ kernel] [ k] string perf recordperf reportperf record保存的采样信息 Samples: 3 K of event 'cycles:ppp' , Event count ( approx. ) : 1778811422 28.61 % swapper [ kernel. kallsyms] [ k] intel_idle4.44 % Xorg [ kernel. kallsyms] [ k] pci_conf1_read2.35 % kworker/ 1 : 2 [ kernel. kallsyms] [ k] _nv029827rm2.05 % Xorg [ kernel. kallsyms] [ k] _nv029827rm1.76 % deepin- wm [ kernel. kallsyms] [ k] pci_conf1_read1.61 % deepin- wm [ kernel. kallsyms] [ k] _nv029827rm1.09 % irq/ 150 - nvidia [ kernel. kallsyms] [ k] _nv029827rm1.08 % deepin- wm [ kernel. kallsyms] [ k] syscall_return_via_sysret0.91 % swapper [ unknown] [ k] 0000000000000000 0.71 % Xorg [ kernel. kallsyms] [ k] _nv018294rm0.41 % swapper [ kernel. kallsyms] [ k] update_load_avg0.33 % Xorg [ vdso] [ . ] 0x0000000000000977 Samples: 36 K of event 'cycles:ppp' , Event count ( approx. ) : 7290912532 - 15.23 % 1.57 % [ unknown] [ k] 0000000000000000 - 7.58 % 0 + 12.19 % 0.14 % [ kernel] [ k] entry_SYSCALL_64_after_hwframe- 12.01 % 0.28 % [ kernel] [ k] do_syscall_64- 3.03 % do_syscall_64- 8.65 % 0.16 % [ kernel] [ k] do_idle- 1.75 % do_idle+ 4.22 % 0.02 % [ kernel] [ k] call_cpuidle+ 4.09 % 0.22 % [ kernel] [ k] cpuidle_enter_state+ 4.01 % 0.02 % [ kernel] 进程 PID 在变的原因
第一个原因,进程在不停的崩溃重启,比如因为段错误、配置错误等等,这时,进程在退出后可能又被监控系统自动重启了 第二个原因,这些进程都是短时进程,也就是在其他应用内部通过exec调用的外面命令。这些命令一般都只运行很短的时间就会结束,你很难用 top 这种间隔时间比较长的工具发现。 查找一个进程的父进程
$ pstree | grep stress| - docker- containe- + - php- fpm- + - php- fpm-- - sh-- - stress| | - 3 * [ php- fpm-- - sh-- - stress-- - stress] 小结
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的CPU,所以应该着重排查进程的性能问题。 系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。 I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了I/O问题。 软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的CPU,所以应该着重排查内核中的中断服务程序。 碰到常规问题无法解释的 CPU 使用率情况时,首先要想到有肯呢个是短时应用导致的问题,比如第一,应用里直接调用了其他二进制程序,这些程序通常运行时间比较短,通过 top 等工具也不容易发现。 第二,应用本身在不停地崩溃重启,而启动过程的资源初始化,很可能会占用相当多的 CPU。 不可中断进程和僵尸进程 进程状态
R :Running或Runnable的缩写,表示进程在 CPU 的就绪队列中,正在运行或者正在等待运行。D:Disk Sleep 的缩写,也就是不可中断状态睡眠(Uninterruptible Sleep),一般表示进程正在跟硬件交互,并且交互过程不允许被其他进程中断打断。Z:Zombie的缩写,表示僵尸进程,也就是进程实际上已经结束了,但是父进程还没有回收它的资源(比如进程的描述符、PID等)。S:Interruptible Sleep的缩写,也就是可中断状态睡眠,表示进程因为等待某个事件而被系统挂起。I:Idle的缩写,也就是空闲状态,用在不可中断睡眠的内核线程上。T/t:Stopped 或 Traced的缩写,表示进程处于暂停或者跟踪状态。X:Dead的缩写,表示进程已经消亡,所以你不会在 top 或者 ps 命令中看到它。正常情况下,当一个进程创建了子进程后,它应该通过系统调用 wait() 或者 waitpid()等待子进程结束,回收子进程的资源;而子进程在结束时,会向它的父进程发送 SIGCHLDSIGCHLD 信号的处理函数,异步回收资源。init进程回收后也会消亡。
进程组和会话
进程组:表示一组相互关联的进程,比如每个子进程都是父进程所在组的成员。 会话:指共享一个控制中断的一个或多个进程组。 找到僵尸进程父进程
pstree - aps 10183 , 1 splash, 5962 - H fd: / / - containe, 6151 -- config / var / run/ docker/ containerd/ containerd. toml- containe, 10026 - namespace moby - workdir... , 10055 └─ ( app, 10183 ) 小结
不可中断状态,表示进程正在跟硬件交互,为了保护进程数据和硬件的一致性,系统不允许其他进程或中断打断这个进程。进程长时间处于不可中断状态,通常表示系统有 I/O 性能问题。 僵尸进程表示进程已经退出,但它的父进程还没有回收子进程占用的资源。短暂的僵尸状态我们通常不必理会,但进程长时间处于僵尸状态,就应该注意了,可能有应用程序没有正常处理子进程的退出。 iowait 高不一定代表 I/O 有性能瓶颈。当系统中只有 I/O 类型的进程在运行时,iowait 也会很高,但实际上,磁盘的读写远没有达到性能瓶颈的程度。 碰到 iowait 升高时,需要先用 dstat、pidstat 等工具,确认是不是磁盘 I/O 的问题,然后再找是哪些进程导致了 I/O。等待 I/O 的进程一般是不可中断状态,所以用 ps Linux 软中断 中断是一种异步的事件处理机制,可以提高系统的并发处理能力 。中断处理程序会打断其他进程的运行,为了减少对正常进程运行调度的影响,中断处理程序就需要尽可能快地运行。
Linux 将中断处理过程分成了两个阶段,也就是上半部和下半部 。
上半部用来快速处理中断 ,它在中断禁止模式下运行,主要处理跟硬件紧密相关的或时间敏感的工作。下半部用来延时处理上半部未完成的工作,通常以内核线程的方式运行。 查看软中断和内核线程 proc文件系统是一种内核空间和用户空间进行通信的机制,可以用来查看内核的数据结构,或者用来动态修改内核的配置。
/proc/softirqs提供了软中断的运行情况。/proc/interrupts提供了硬中断的运行情况。在查看/proc/softirqs时,要特别注意:
# cat /proc/softirqs注意软中断的类型,也就是第一列内容。 注意同一种软中断在不同 CPU 上的分步情况,也就是同一行内容。 软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核先后才能,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。 查看线程运行状况
# ps aux|grep softirq检查网络接收的软中断
sar:用来查看系统的网络收发情况。不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数),还可以观察网络收发的PPS,即每秒收发的网络帧数。- n DEV 1 15 : 03 : 46 IFACE rxpck/ s txpck/ s rxkB/ s txkB/ s rxcmp/ s txcmp/ s rxmcst/ s % ifutil15 : 03 : 47 eth0 12607.00 6304.00 664.86 358.11 0.00 0.00 0.00 0.01 15 : 03 : 47 docker0 6302.00 12604.00 270.79 664.66 0.00 0.00 0.00 0.00 15 : 03 : 47 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 15 : 03 : 47 veth9f6bbcd 6302.00 12604.00 356.95 664.66 0.00 0.00 0.00 0.05 第一列:表示报告的时间rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数,也就是PPS。rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数,也就是 BPS
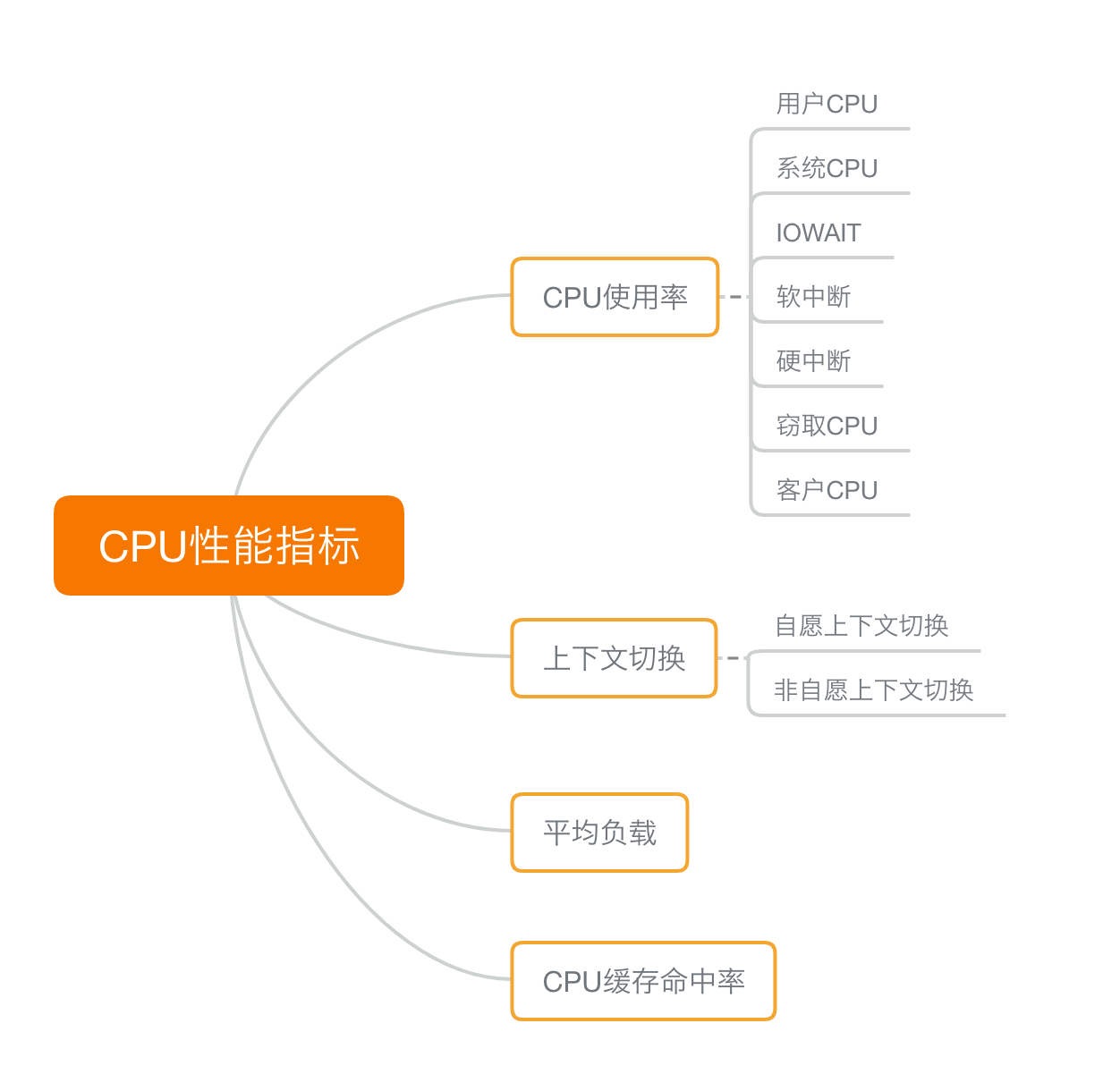
- i eth0 - n tcp port 80 15 : 11 : 32.678966 IP 192.168 .0 .2 .18238 > 192.168 .0 .30 .80 : Flags [ S ] , seq 458303614 , win 512 , length 0 . . . 如何快速分析出系统 CPU 的瓶颈 CPU 性能指标 1. CPU 使用率
用户 CPU 使用率,包括用户态 CPU 使用率(user) 和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。 系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。 等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。 软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。 除了上面这些,还有在虚拟环境中会用到的窃取 CPU 使用率(steal)和用户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。 2. 平均负载(Load Average)
3.进程上下文切换
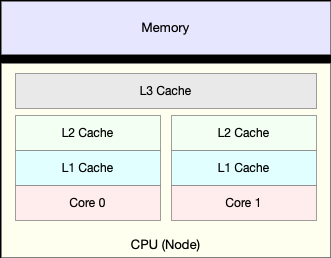
无法获取资源而导致的自愿上下文切换。 被系统强制调度导致的非自愿上下文切换。 4.CPU 缓存的命中率
CPU 缓存.png
CPU性能指标思维导图
CPU性能指标
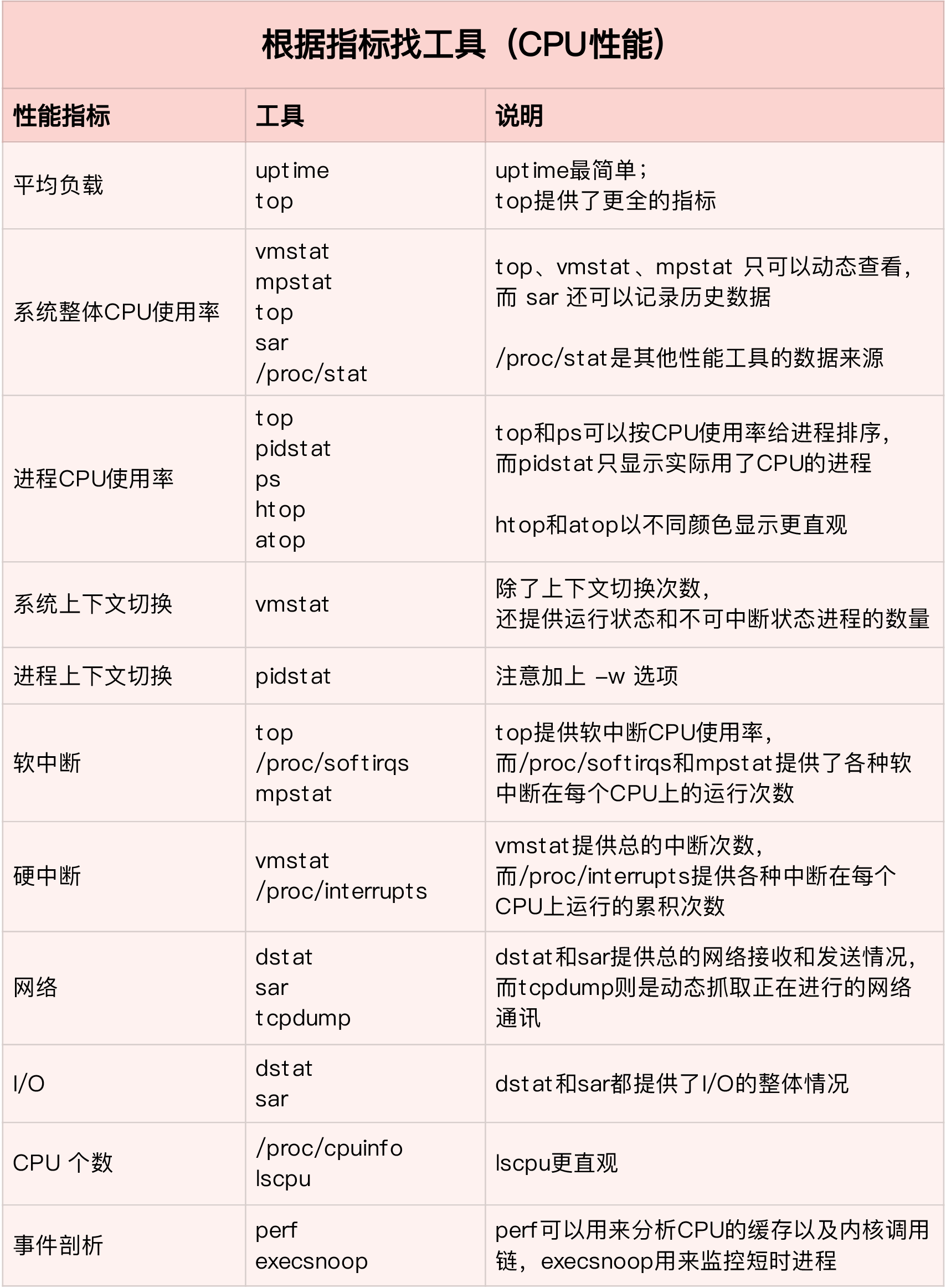
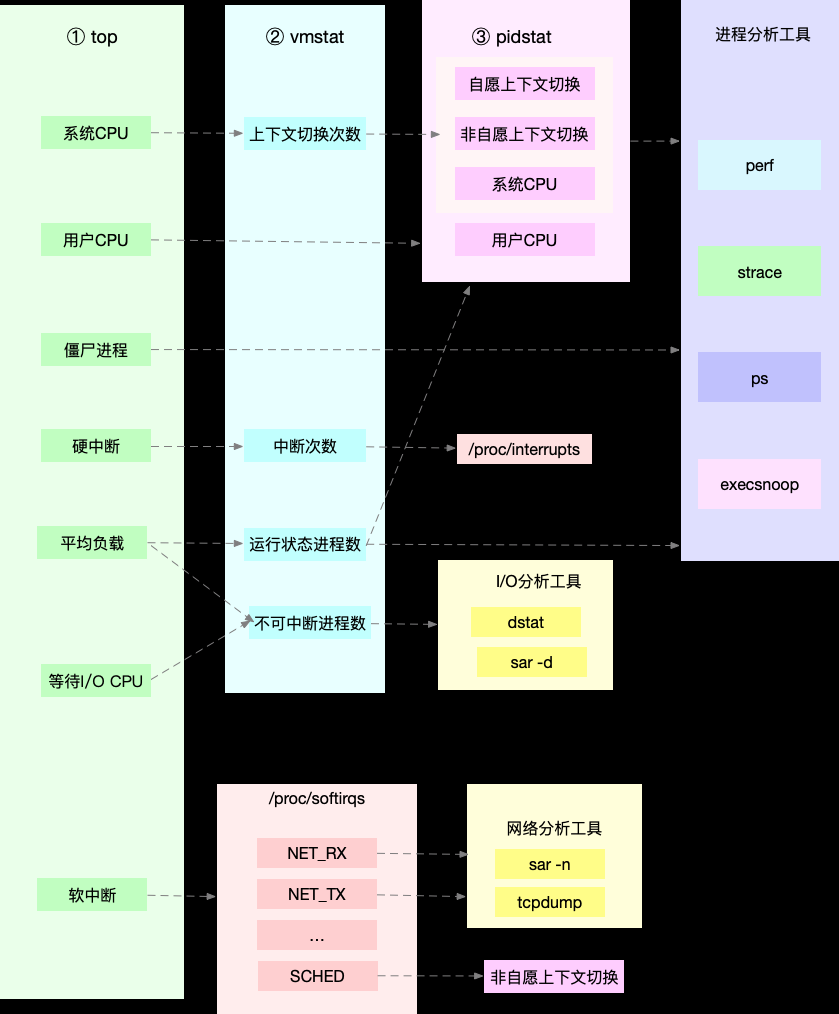
性能工具 第一个维度:从 CPU 的性能指标出发
根据指标找工具(CPU性能)
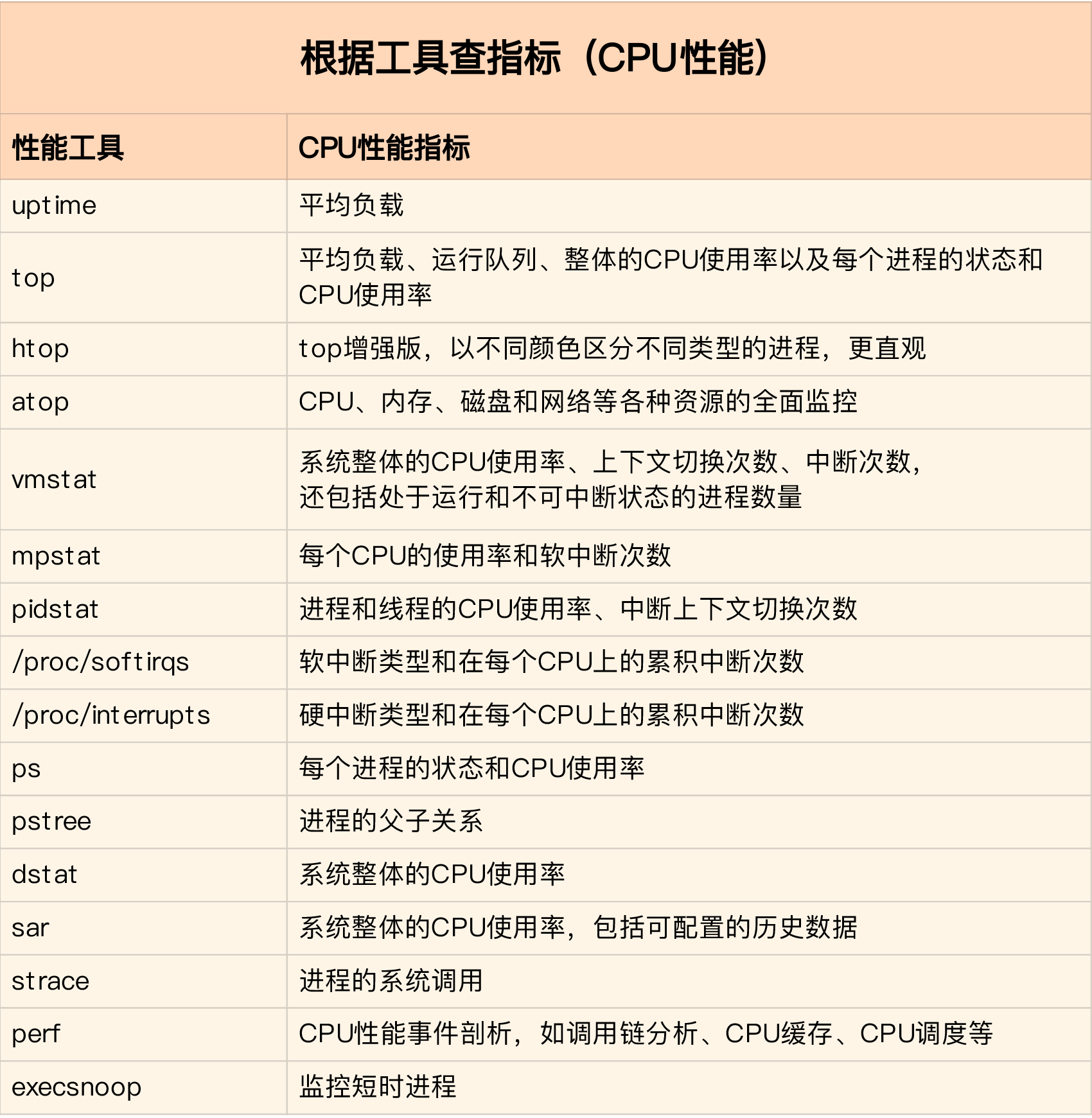
第二个维度:从工具出发
根据工具查指标(CPU性能)
快速分析 CPU 的性能瓶颈 想弄清楚性能指标的关联性,就要通晓每个性能指标的工作原理。top、vmstat、pidstat。
关系图
CPU 性能优化的几个思路 怎么评估性能优化的效果 三步走:
确定性能的量化指标 测试优化前的性能指标。 测试优化后的性能指标。 多个性能问题同时存在,要怎么选择? 并不是所有的性能问题都值得优化。
有多种优化方法时,要如何选择? 性能优化并非没有成本。性能优化通常会带来复杂度的提升,降低程序的可维护性,还可能在优化一个指标时,引发其他指标的异常。
CPU 优化 应用程序优化
常见的几种应用程序的性能优化方法:
编译器优化:很多编译器都会提供优化选项,适当开启它们,在编译阶段你就可以获得编译器的帮助,来提升性能。 算法优化:使用异步处理,可以避免程序因为等待某个资源而一直阻塞,从而提升程序的并发处理能力。 多线程代替多进程:线程的上下文切换并不切换进程地址空间,因此可以降低上下文切换的成本。 善用缓存:经常访问的数据或者计算过程中的不走,可以放在内存中缓存起来,这样在下次用时可以直接从内存中获取,加快程序的处理速度。 系统优化
常见的方法:
CPU 绑定:把进程绑定到一个或者多个 CPU 上,可以提高 CPU 缓存的命中率,减少跨 CPU 调度带来的上下文切换问题。 CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。这样,这些 CPU 就由指定的进程独占,换句话说,不允许其他进程再来使用这些 CPU。 优先级调整:使用 nice 调整进程的优先级,正值调低优先级,负值调高优先级。 为进程设置资源限制:使用 Linux cgroups来设置进程的 CPU 使用上线,可以防止由于某个应用自身的问题,而耗尽系统资源。 NUMA(Non-Uniform Memory Access)优化:支持 NUMA 的处理器会被划分为多个 node,每个 node 都有自己的本地内存空间。 NUMA 优化,其实就是让 CPU 尽可能只访问本地内存。 中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能消耗大量的 CPU。开启irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个CPU上。