大家好,我是云祁!今天和大家聊聊数据仓库中维度表设计的那些事。
维度表是维度建模的灵魂所在,在维度表设计中碰到的问题(比如维度变化、维度层次、维度一致性、维度整合和拆分等)都会直接关系到维度建模的好坏,因此良好的维表设计就显得至关重要,今天就让我们就一起来探究下关于维表设计的相关概念和一些技术。
维度变化
维度表的数据通常来自于前台业务系统,比如商品维度表可能来自于 ERP 或者超市 POS 系统的商品表,但商品是会发生变化的,比如商品所属的类目 、商品标签价格、商品描述等,这些变化有可能是之前有错误需要订正所致的,或者是实际的业务情况变化。
不管哪种情况,维度设计过程中,确定源头数据变化在维度表中如何表示非常重要。因此在维度建模中,这一现象称为缓慢变化的维度,简称 缓慢变化维(slowly changing dimension, SCD)。
根据变化内容的不同,下游的分析可能要求用不同的办法来处理
比如对于商品的描述信息,也许业务人员对此并不敏感,或者认为无关紧要,这种情况可以直接覆盖 。
但是对于商品所属的类目发生变化,则需要认真考虑, 因为这涉及归类这个商品的销售活动到哪个类目一一是全部归到新类目,还是全部归到旧类目?变化前归到旧类目,还是变化后归到新类目?这实际上也涉及了下面要分享的缓慢变化维的几种处理办法。
1. 重写维度值
当一个维度值属性发生变化时,重写维度值方法直接用新值覆盖旧值。
该技术适用于维度建模中不需要保留此维度属性历史变化的情况,常用于错误订正或者维度属性改变无关紧要的场景,比如用户的生日之前发生输入错误,不需要保留之前的生日历史数据。
那么采用重写维度值的方法,就将会改变此维度属性的所有历史度量。
比如,分析师希望分析星座和销售的关系,之前用户的生日属于白羊座,但是修改后的生日属于双子座,那么维度属性修改后,其销售额将都属于双子座。因此维度设计人员只在必要情况下使用此方法,同时需要告知下游分析人员。
采用重写维度值方法的维度表和事实表变化如图:
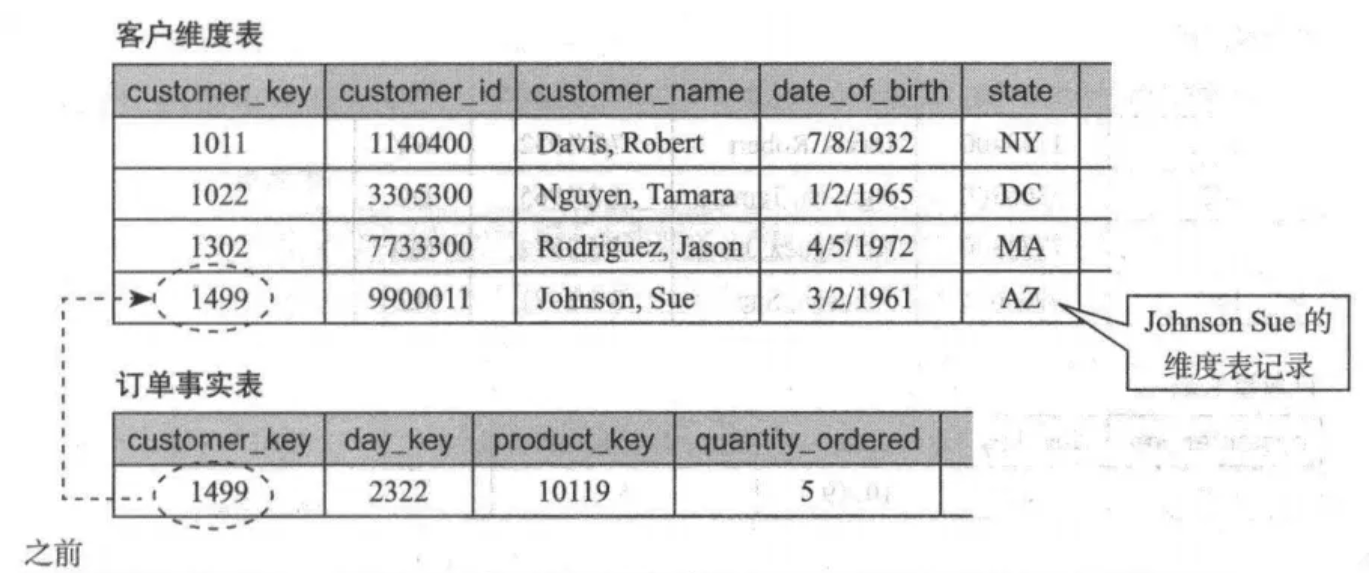
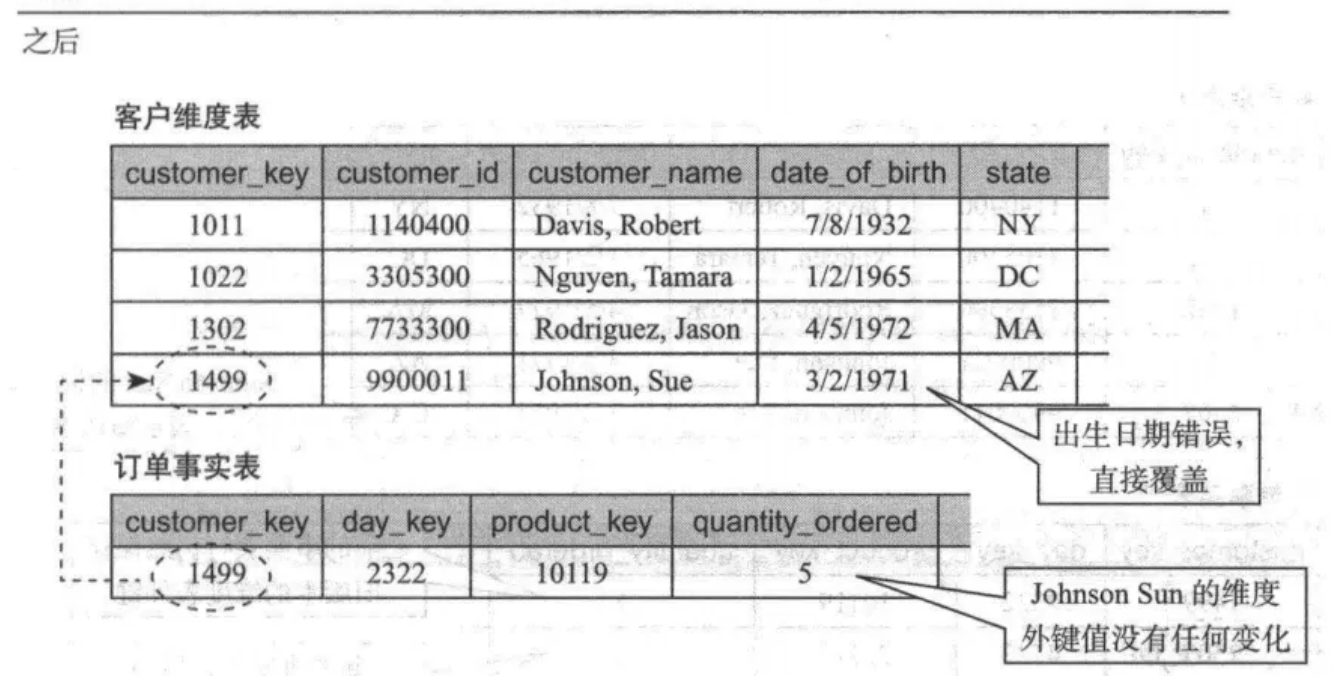
采用重写维度值方法处理变化维示例
2. 插入新的维度行
相比重写维度值方法不维护维度属性变化的特点,插入新的维度行方法则通过在维度表中插入新的行来保存和记录变化的情况。
属性改变前的事实表行和旧的维度值关联,而新的事实表行和新的维度值关联。
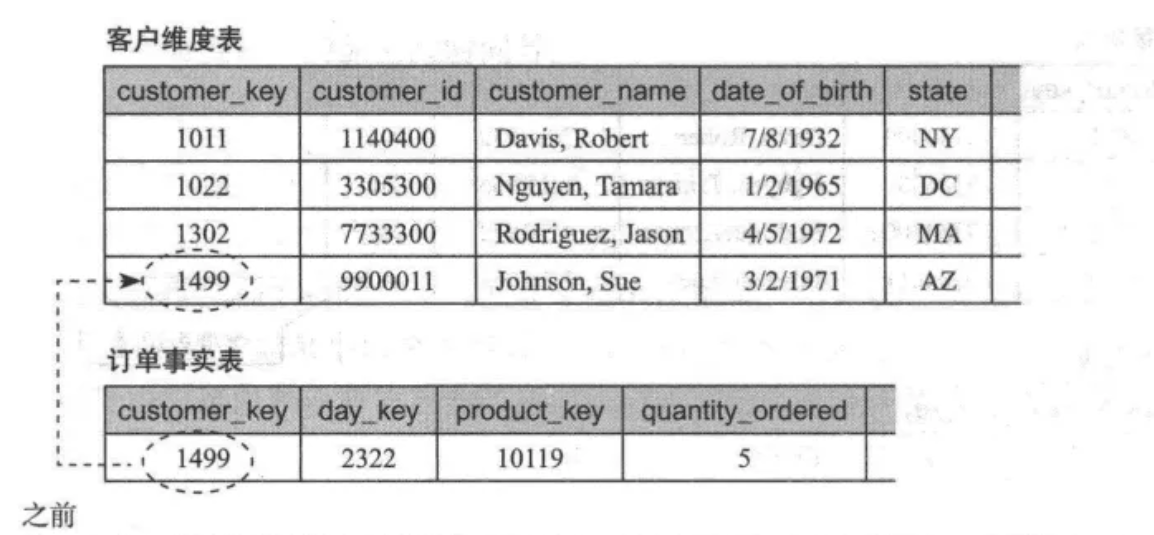
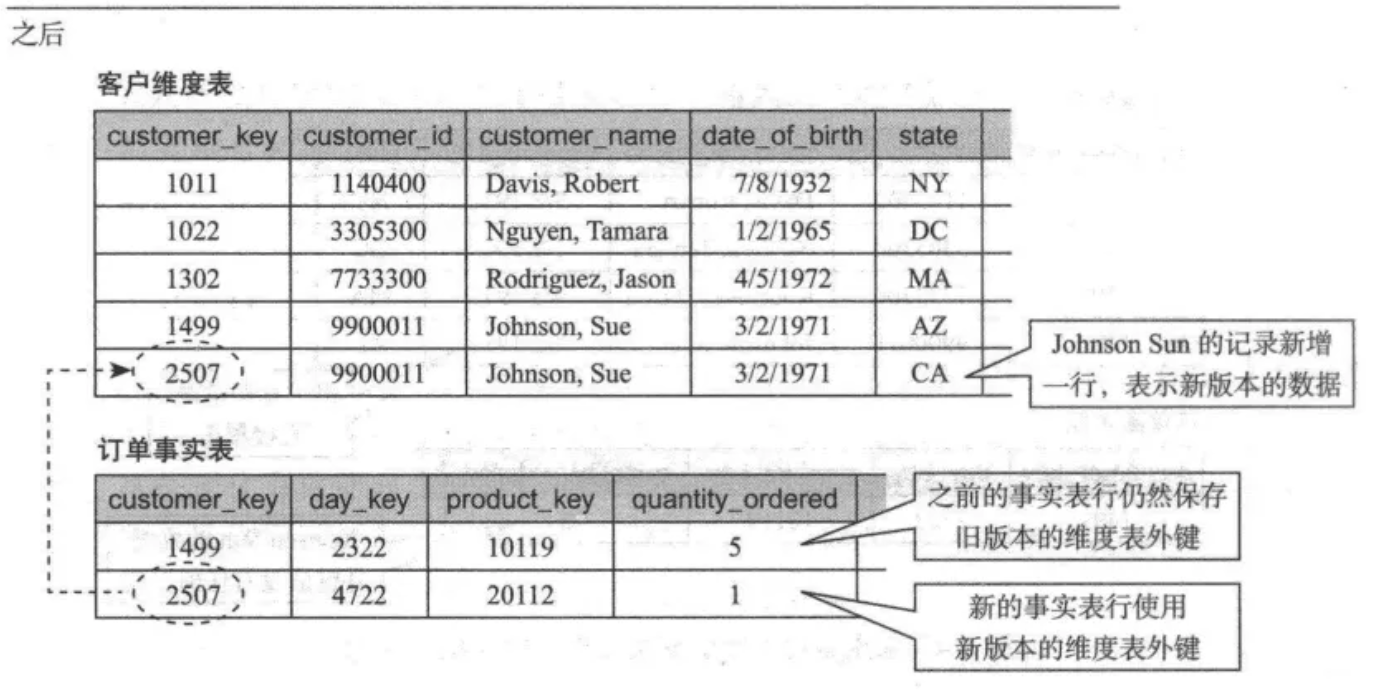
采用插入新的维度行方法处理缓慢变化维示例
我们仔细观察变化后的维度表可以发现,新复制了一行该用户的信息,唯一不同在于 state 的不同(之前是 AZ,之后是 CA)。同时,仔细观察订单事实表也会发现,过去的订单是和旧的唯独行关联,而新的订单和新的维度行关联。
通过新增维度行,我们保存了维度的变化,并实现了维度值变化前的 实和变化后的事实分别与各自的新旧维度值关联。
但是这也给维度表用户带来了困惑,为什么查询会员会在维度表中发现多行记录?尽管可以向用户解释,但是用户的使用和学习成本无疑增加了, 而且数据开发人员对于维度变化的处理逻辑无疑更复杂了。
3. 插入新的维度列
在某些情况下,可能用户会希望既能用变化前的属性值,又能用变化后的属性值来分析变化前后的所有事实。此时可以采用插入新的维度列这种方法。
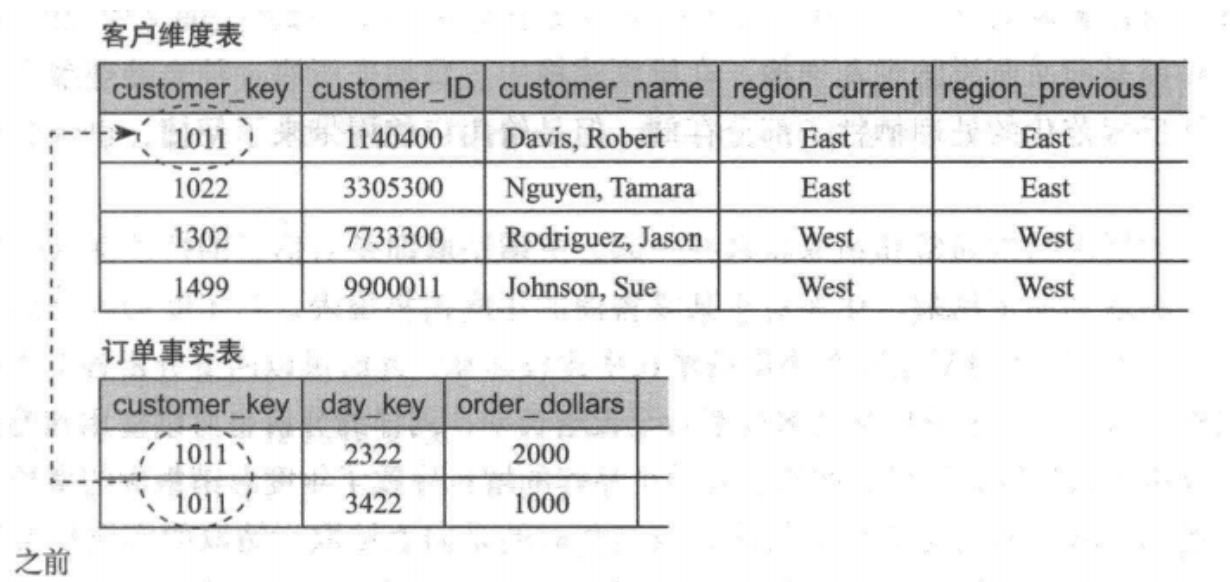

采用插入新的维度列处理缓慢变化维示例
不同于前一种方法的添加一行,这种方法通过新增一列,比如用 region_previous 列表示之前的所属大区,同时新增 region_current 来表示变化后的所属大区。如果有多次变化,就需要有多个列来存储。
实际上,这三种方法都能从不同角度解决维度变化的问题,还有通过组合这三种方法形成的其他各种技术可用于处理维度变化,这里就不再赘述。
当然了,不管哪种技术,在大数据时代都不是完美的,而且有一定的处理复杂度和学习使用成本。
如何以一种最简单、直接的办法来解决维度变化呢?我们在后面会聊聊 快照技术 ,以解决大数据时代的维度变化问题。
维度层次
维度层次指的是某个维度表中属性之间存在的从属关系问题。比如商品的类目可能是有层次的(一级类目、二级类目、三级类目等,尤其对于宝洁、联合利华等大的快消企业集团),同时类目、品牌和产品实际上也是有层次的。那么维度建模如何处理这些层次结构呢?
实际上有两种处理办法:
- 第一种是将所有维度层次结构全部扁平化、冗余存储到一个维度表中,比如商品的一至三级类目分别用三个字段来存储,品牌等的处理也是类似的;
- 第二种是新建类目维度表,并在维度表中维护父子关系。
第一种其实就是星型架构,第二种是雪花架构。在维度建模中,我们采用第一种来处理维度的层级问题,这样反规范化的处理牺牲了部分存储,但是给用户使用带来了便捷,也降低了学习使用成本。
维度的层次结构通常和钻取联系在一起,所谓钻取即是对信息的持续深入挖掘。
钻取分为向上钻取和向下钻取,比如对于某零售商的年度销售报表,其年度销售总额显示增长20%,那么从时间上分析是哪个季度的增长率比较高呢?
此时可以向下分析各个季度的增长率,同样可以继续向下分析到月增长率乃至天增长率,同样的分析也可以应用到类目 、品牌等,来分析到底是哪个类目的增长或者哪个品牌的增长导致了年度总销售额的增长 20% 。这就是向下钻取。
与之相对的是向上钻取,钻取的实质是增加或者减少维度,增加维度(向下钻取)从汇总数据深入到细节数据,而减少维度(向上钻取)则从细节数据概括到汇总数据 。通过钻取,用户对数据能更深入地了解数据,更容易发现问题,从而做出正确的决策。
维度一致性
在 Kimball 的维度设计理论中,并没有物理上的数据仓库。数据仓库是在对多个主题、多个业务过程的多次迭代过程中逐步建立的,这些多个问题、多个业务过程的多次迭代过程常被从逻辑上划分为数据集市。
所谓数据集市一般由一张和多张紧密关联的事实表以及多个维度表组成,一般是部门级的或者面向某个特定的主题。数据仓库则是企业级的、面向主题的、集成的数据集合。
物理上的数据集市组合成逻辑上的数据仓库, 旦数据集市的建立是逐步完成的,如果分步建立数据集市的过程中维度表不一致,那么数据集市就会变成孤立的集市,不能从逻辑上组合成一个集成的数据仓库,而维度一致性的正是为了解决这个问题。
维度一致性的意思是指:两个维度如果有关系,要么就是完全一样的,要么就是一个维度在数学意义上是另一个维度的子集。
不一致既包含维度表内容的不 致,也包含维度属性上的不一致。
- 比如对于一个电子商务公司,如果其浏览等相关主题域的商品维度表包含了该企业的所有商品的访问信息,但是由于某种原因其交易域的商品缺失了部分商品 (有可能是成交在其他平台完成),那么对这些缺失商品的交易分析就无法完成 。
- 同样如果两的商品属性不同,比如日期格式、类目划分(有可能浏览分为前天类目,成交是后台类自)等不一致,那么跨浏览域和交易域的对类目和日期的交叉分析就无法进行,因为其类目划分就不一致。
维度一致性对于数据集市成为数据仓库起着关键作用,实际数据集市设计和开发过程中,必须保证维度一致性,具体可以采用共享同一个维度表或者让其中一个维度表是另外一个维度表的子集等方式来保证一致性,从而避免孤立数据集市的出现。
维度整合和拆分
实际维度表设计中,有时候会出现同一个维度表来自于多个前台业务系统的问题,此时就会带来维度整合和拆分问题。
前台的业务系统通常是比较复杂的,比如移动端交易系统和PC端交易系统的系统架构和底层数据库、表结构等完全不一致,此时就存在维度的整合问题。
在实际整合中,同一个维度整合需要考虑如下问题:
- 命名规范:要确保一致和统一
- 字段类型 :统一整合为一个字段类型
- 字段编码和含义:编码及含义要整合为一致
与整合相对的是拆分
对于大的集团公司来说,以中石化为例,其主业为成品油销售,但是同时其还有中石化加油站的快捷零售店(在此仅做说明问题使用),它们的商品表字段和属性由于业务的不同而存在很大的差异(石油商品和零售店销售的食品、饮料等)。
此时需要用一个统一整合的商品表么(从直觉来说是不需要的,因为业务差异巨大)?
在维度建模理论中,对于上述情况通常有两种处理办法
- 建一个基础的维度表, 此基础维度表包含这些不同业务的共有属性,同时建立各自业务的单独维度表以包含其独特的业务属性。比如,上述例子就可以建立一个共有的商品维度表记录商品价格、商品描述等共有属性字段,同时建立成品油销售的商品维度表记录油标号( 92 95 97 等)等成品油独特的商品属性,另外建立一个零售商品维度表记录便利店的各种商品属性(实际操作中通常先建立两个单独的维度表,然后基于单独维度表生成共有的商品维度表或者视图)
- 拆分,即不合并,即各个业务差异独特性的业务各自建立完全独立的两个维度表,各自管理各自维度表和属性。
我们在实际操作中 ,对于业务差异大的业务,偶合在一起并不能带来很大的便利和好处,因此通常倾向于拆分(即不合并),各自管理各自的维度表。而对于业务相似度比较大的业务,则可以采用上述的第一种方法。