-
Hive的数据定义
-
Hive的数据仓库
-
Hive中的表
-
Hive中的数据类型
-
Hive中表的类型
-
Hive的数据操作
1. Hive的数据定义
HQL是一种SQL方言,支持绝大部分SQL-92标准,并对其做了一些扩展,并且仍然存在新的差异:不支持行级的操作,不支持事务等,从语法上讲,HQL最接近MySQL的方言,操作HIve的时候注意HQL与SQL的区别。
2 Hive中的数据库
Hive中的数据库本质上仅仅是个表的目录或者命名空间。在生产环境中,如果表非常多的话,一般会用数据库讲生成表组织成逻辑组。但实际情况中,用户一般没有指定数据库,用的是默认的default数据库。数据库目录的名字都是以 .db结尾
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库中的表会以子目录的形式存储,表中的数据会以表目录下的文件形式存储,如果用户使用的是默认的default数据库,该数据库本身没有自己的目录。数据库所在目录在:hive-site.xml文件的配置项hive.metastore.wareshuse.dir配置的目录之后,默认是:/user/hive/warehouse:
1.使用create database 库名 来创建数据库(如果存在将抛出错误信息)
推荐使用:drop database if exists 库名(判断是否存在)
![]()
2. 查看已存在的数据库:
-
-
- show databases ;
- show databases like '库名' 模糊查询
- desc databases(table) extended 库(表) ; 详细查询
-
3.和MySQL一样,可以切换库:use 库名;
4.删除某个数据库时:drop database 库名;
3 .Hive中的表
1.查看当前数据库下的表:show tables;或者show tables in 库名;
2.创建表:

- 如果用户加上:if not exists,那么当该表存在时Hive会忽略掉后面的命令,但不会做出任何提示,
- 如果用户当前的数据库非目标数据库,需要指定数据库才能以上操作;hive>use 库名
- 可以对表的字段和表添加注释,在需要添加注释的字段后面加上:"COMMENT.."
- 需要在表的最后指定截取方式:row format delimited fields terminated by '截取方式';
- 查看表级别的注释,则需要使用:
- desc extended 表名;
- desc format 表名;
- 可以使用:row format delimited ,stored as 的字句指定行列的数据格式和文件存储格式,也可省略不写
- location字句可以指定该表的存储位置,如果不写,将会存储在默认的数据仓库目录,
- 复制表:
- create table 新表名 like 老表名;(只复制表结构复制数据)
- create table 新表名 row format delimited fields terminated by ' ' (截取方式) as select * from 老表;(查询语句)
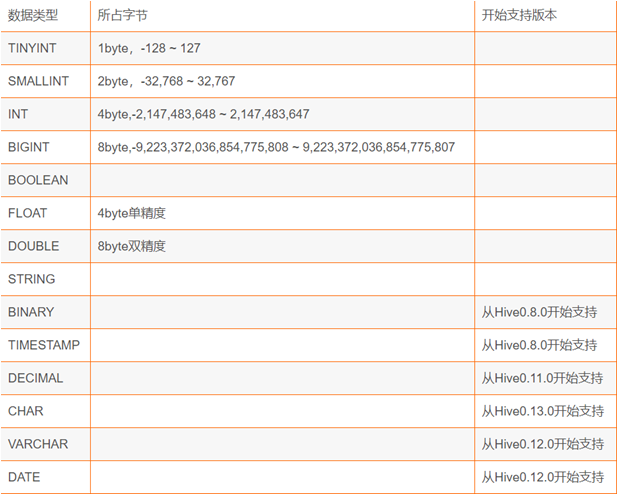
4. Hive中的数据类型
1.基础数据类型:
TINYINT SMALLINT INT BIGINT BOOLEAN DOUBLE STRING TIMESTAMP DECIMAL CHAR VARCHAR DATA
2.复杂数据类型:
ARRAY MAP STRUCT UNION 这些复杂数据类型都是由基本类型组成。
- ARRAY
- 定义方式:字段名 array<数据类型>
- ARRAY类型是由一系列相同数据类型元素组成,这些元素可以通过下标来访问。
- 截取方式:collection items terminated by '截取方式';
- MAP
- 定义方式:字段名 map<字段名 数据类型,....>
- Map包含key-value,我们可以通过key来访问元素
- 截取方式:map keys terminated by '截取方式';
- STRUCT
- 定义方式:字段名 struct<字段名 数据类型......>
- struct可以包含不同的数据类型的元素,可以通过 “点语法” 的方式来获取所需元素比如user是一个struct类型,可以通过user.address得到这个用户的地址。
5.· Hive中表的类型
- 管理表
- 在创建表的时候如果没有特别指定的话,都是所谓的管理表,也叫内部表,表管理意味着由Hive负责管理表的数据,hive默认会将数据保存到数据仓库目录下,当删除管理表时,hive会将表的数据还有元数据删除。
- 外部表
- 如果当一份数据需要被多种工具分析时,如:hive,pig。意味着这份数据的所有权并不由hive拥有,这个时候可以创建一个外部效(External table)来保存数据;如下:
- 关键字:External 指明该表为外部表,而location 字句指明了数据存放的位置
- 当需要删除外部表时,Hive会认为没有完全拥有这份数据,所以Hive只会删除该外部表的元数据信息而不会删除该表的信息
- 分区表
- Hive可以支持进行分区(partition),分区可以将表进行水平切分,讲表数据按照某指定规则进行存。
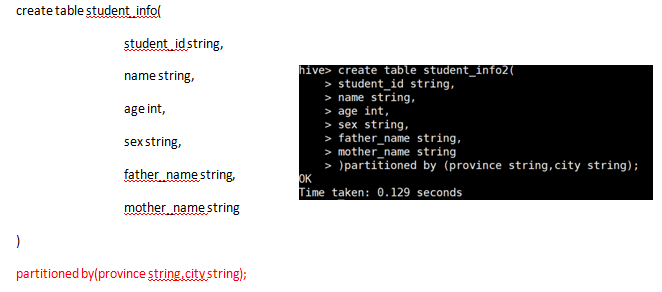
效果如下所示:

-
无论是管理表还是外部表,一旦给表存在分区,那么数据在加载时后必须进入指定分区中:
- load data inpath '路径' into table 表名 partition(分区字段 = 值);
- 删除表(和sql一样)
- drop table 表名;
- drop table if exists 表名;
- 修改表
- 在Hive中,可以使用alter table 表名;来修改表属性,仅仅修改表的元数据,不会修改表本身数据。,所以一定要保证表的数据和修改后的元数据模式要匹配,否则数据将不可用。
- 表重命名
- alter table 老 rename to 新名;
- 增加分区(通常都是外部表)
- alter table 表名 add partition(字段名=值)
- alter table 表名 add partition (分区字段 = '值') (分区字段 = '值'); 空格隔开
- 修改分区路径
- alter table 表名 partition(字段名=值) set location '路径';
- 删除分区
- alter table 表名 drop partition (字段名=值)
- 修改表的属性(内部表和外部表的相互转换)
- alter table 表名 set tblproperties('WXTERNAL'='TRUE');
- 修改列信息
- alter table 表 chang column 老列 新列 数据类型;
- 增加列
- alter table 表名 add columns 新列名 数据类型
- 删除或者换列
- alter table 表名 replace colums 新列名 数据类型
6. Hive的数据操作
在创建完表之后,就应该对表中的数据进行相关操作,但是Hive不支持行级别的删改,也就是传统关系型数据库中的updata,delete操作时不支持的,支持的只有转载数据,导出数据和查询数据操作;
- 装载数据,在Hive中转载数据可以理解为传统数据库中的添加数据,但原理不同,Hive总有五种装载数据的方式;
- hdfs上传:hadoop fs -put 文件 路径;
- load data local(本地) inpath '路径' into table 表名;
- 覆盖现有的表
- load data local inpath '路径' overwrite into table 表名;
- 如果是分区表:load data local inpath '路径' overwrite into table 表名 partition(分区字段 = 值);
- 导出数据
-
- 可以通过查询语句选取所需要的的数据格式,再用insert字句将数据导出至HDFS或本地,如下:
- insert overwrite directory '路径' select * from 表名;
- hadoop dfs -cp '路径' '目标路径';