-----------------------------------------------------------学无止境------------------------------------------------------
前言:大家好,欢迎来到誉雪飞舞的博客园,我的每篇文章都是自己用心编写,
算不上精心但是足够用心分享我的自学知识,希望大家能够指正我,互相学习成长。
转载请注明:https://www.cnblogs.com/wyl-pi/p/10510599.html
这段话从百度就有,给你们省功夫直接看吧。
XPath的使用方法:
首先讲一下XPath的基本语法知识:
四种标签的使用方法
1) // 双斜杠 定位根节点,会对全文进行扫描,在文档中选取所有符合条件的内容,以列表的形式返回。
2) / 单斜杠 寻找当前标签路径的下一层路径标签或者对当前路标签内容进行操作
3) /text() 获取当前路径下的文本内容
4) /@xxxx 提取当前路径下标签的属性值
5) | 可选符 使用|可选取若干个路径 如//p | //div 即在当前路径下选取所有符合条件的p标签和div标签。
6) . 点 用来选取当前节点
7) .. 双点 选取当前节点的父节点
另外还有starts-with(@属性名称,属性字符相同部分),string(.)两种重要的特殊方法后面将重点讲。
咳咳,你要确保以上看懂了,不然不需要往下看了。或者看个差不多了也可以往下,看例子就明白了;
我们先普及一下Xpath的基本用法:
#xpath的基本使用方法 from lxml import etree web_data = ''' <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-inactive"><a href="link3.html">second item</a></li> <li class="item-1"><a href="link4.html">third item</a></li> <li class="item-0"><a href="link5.html">fourth item</a> </ul> </div> ''' #(1)etree.tostring(html)将标签补充齐整,是html的基本写法 html = etree.HTML(web_data.lower()) print("html_1 {} ".format(html)) print(type(html)) result = etree.tostring(html) print(" ",type(result)) print('''result.decode("utf-8")_1 {} '''.format(result.decode("utf-8"))) #(2.0)获取标签里的内容,获取a标签的所有内容,a后面就不用再加“/”否则报错 html = etree.HTML(web_data) print(type(html)) html_data = html.xpath('/html/body/div/ul/li/a') print("html_2.0 {}".format(html)) for i in html_data: print("i.text_2.0 {} ".format(i.text)) print(" ") #(2.1)写法二(直接在需要查找的标签后面加一个/text()就行) html = etree.HTML(web_data) html_data = html.xpath('/html/body/div/ul/li/a/text()') print("html_2.1 {}".format(html)) for i in html_data: print("i_2.1 {} ".format(i)) print(" ") #(3)使用pasrse打开html文件 html = etree.parse("xpath_data.xml") html_data = etree.tostring(html,pretty_print=True) res = html_data.decode('utf-8') print(res)
运行结果如下:
html_1 <Element html at 0xc4f558>
<class 'lxml.etree._Element'>
<class 'bytes'>
result.decode("utf-8")_1
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-inactive"><a href="link3.html">second item</a></li>
<li class="item-1"><a href="link4.html">third item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</li></ul>
</div>
</body></html>
<class 'lxml.etree._Element'>
html_2.0 <Element html at 0xc79760>
i.text_2.0 first item
i.text_2.0 second item
i.text_2.0 third item
i.text_2.0 fourth item
html_2.1 <Element html at 0xc4f558>
i_2.1 first item
i_2.1 second item
i_2.1 third item
i_2.1 fourth item
<html>
<body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-inactive"><a href="link3.html">second item</a></li>
<li class="item-1"><a href="link4.html">third item</a></li>
<li class="item-0"><a href="link5.html">fourth item</a>
</li></ul>
</div>
</body>
</html>
Xpath的特殊用法:
#xpath特殊用法 from lxml import etree #(1)starts-with解决标签相同开头的属性值 html=""" <body> <div id="aa">aa</div> <div id="ab">ab</div> <div id="ac">ac</div> </body> """ example = etree.HTML(html) content = example.xpath("//div[starts-with(@id,'a')]/text()") for each in content: print(each) print("(1) is over. ") #(2)string(.)标签套标签 html1=""" <div id="a"> left <span id="b"> right <ul> up <li>down</li> </ul> east </span> west </div> """ pil = etree.HTML(html1) data = pil.xpath("//div[@id = 'a']")[0] #print("data's type is {}".format(type(data))) print("data {} ".format(data)) info = data.xpath("string(.)") #replace是将新的字符串替换旧字符串,第三个参数是max,替换不超过max次; content = info.replace(' ','').replace(' ','') for i in content: print(i) print("(2) is over ")
运行结果如下:
aa
ab
ac
(1) is over.
data <Element div at 0x36483f0>
l
e
f
t
r
i
g
h
t
u
p
d
o
w
n
e
a
s
t
w
e
s
t
(2) is over
------------------------Xpath Learn_Test Is Over-------------------------
用法介绍完了,我们的正文终于来了:
Xpath豆瓣口碑周榜爬取程序:
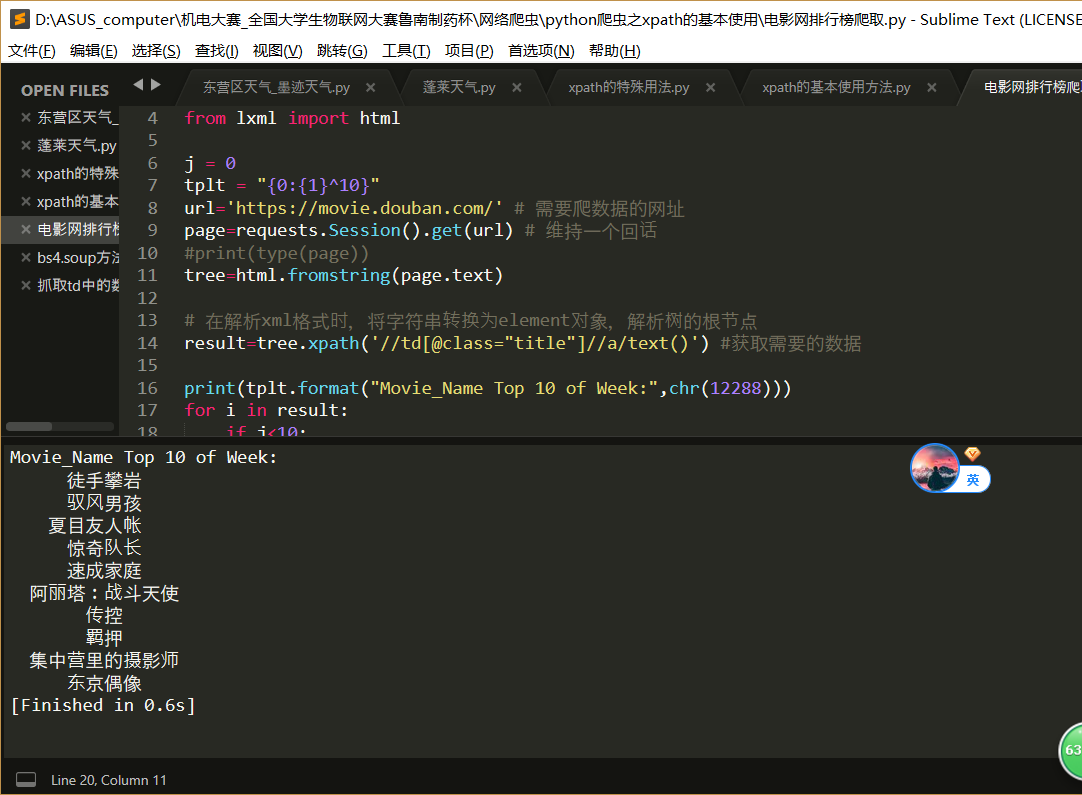
import bs4 import requests from bs4 import BeautifulSoup from lxml import html j = 0 tplt = "{0:{1}^10}" url='https://movie.douban.com/' # 需要爬数据的网址 page=requests.Session().get(url) # 维持一个回话 #print(type(page)) tree=html.fromstring(page.text) # 在解析xml格式时,将字符串转换为element对象,解析树的根节点 result=tree.xpath('//td[@class="title"]//a/text()') #获取需要的数据 print(tplt.format("Movie_Name Top 10 of Week:",chr(12288))) for i in result: if j<10: print(tplt.format(result[j],chr(12288))) j += 1 #print(result)
里面要讲的也就只有fromstring方法需要讲解一下:
fromstring() 可以在解析xml格式时,将字符串转换为Element对象,解析树的根节点。
在python中,对返回的page.txt做fromstring()处理,可以方便进行后续的xpath定位等。
如:
page = requests.get(url)
data = html.fromstring(page.text)
getData = data.xpath('........')
运行结果:
总结:
如何呢?我为您编撰的这两篇豆瓣电影排行榜python代码实现感觉是不是差别很明显,首当其冲的就是这个代码数量少了两三倍,
可不是一点半点了,所以学习的途径,方法或者说一个问题的解决方法的的确确是多样的、丰富的,切忌一成不变一个方法用到 “ 海枯石烂 ” ,
我们要坦然敢于接受比自己优秀的人、事,并从中虚心的去学习他们的闪光点充实自己,为自己加料,逐渐实现自己的升华。
相信自己!!!!
相信自己!!!!
相信自己!!!!
你们好我是誉雪飞舞,再会。
如果觉得我的文章还不错,关注一下,顶一下 ,我将会用心去创作更好的文章,敬请期待。