级联森林(Cascade Forest)
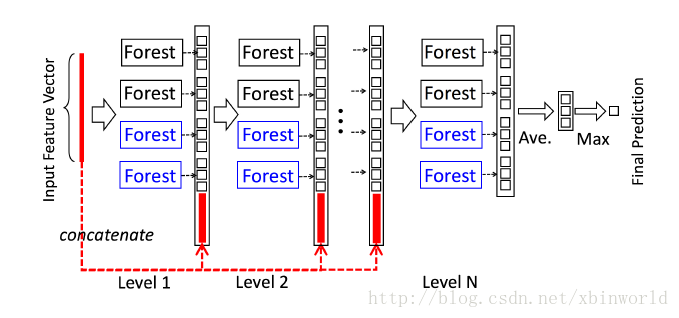
级联森林结构的图示。级联的每个级别包括两个随机森林(蓝色字体标出)和两个完全随机树木森林(黑色)。
假设有三个类要预测,因此,每个森林将输出三维类向量,然后将其连接以重新表示原始输入。注意,要将前一级的特征和这一级的特征连接在一起——在最后会有一个例子,到时候再具体看一下如何连接。
给定一个实例(就是一个样本),每个森林会通过计算在相关实例落入的叶节点处的不同类的训练样本的百分比,然后对森林中的所有树计平均值,以生成对类的分布的估计。如下图所示,其中红色部分突出了每个实例遍历到叶节点的路径。叶节点中的不同标记表示了不同的类。被估计的类分布形成类向量(class vector),该类向量接着与输入到级联的下一级的原始特征向量相连接。例如,假设有三个类,则四个森林每一个都将产生一个三维的类向量,因此,级联的下一级将接收12 = 3×4个增强特征(augmented feature)。
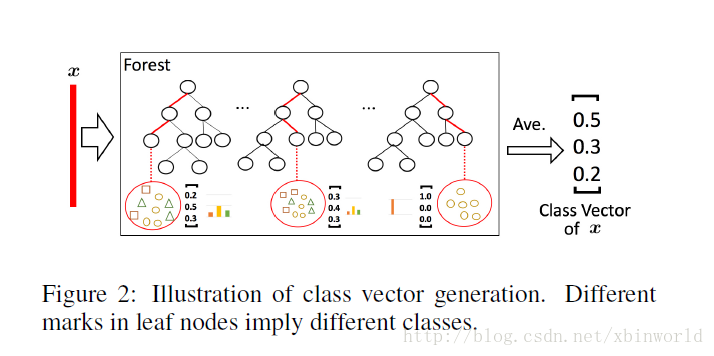
为了降低过拟合风险,每个森林产生的类向量由k折交叉验证(k-fold cross validation)产生。具体来说,每个实例都将被用作 k -1 次训练数据,产生 k -1 个类向量,然后对其取平均值以产生作为级联中下一级的增强特征的最终类向量。需要注意的是,在扩展一个新的级后,整个级联的性能将在验证集上进行估计,如果没有显着的性能增益,训练过程将终止;因此,级联中级的数量是自动确定的。与模型的复杂性固定的大多数深度神经网络相反,gcForest 能够适当地通过终止训练来决定其模型的复杂度(early stop)。这使得 gcForest 能够适用于不同规模的训练数据,而不局限于大规模训练数据。
多粒度扫描(Multi-Grained Scanning)
深度神经网络在处理特征关系方面是强大的,例如,卷积神经网络对图像数据有效,其中原始像素之间的空间关系是关键的。(LeCun et al., 1998; Krizhenvsky et al., 2012),递归神经网络对序列数据有效,其中顺序关系是关键的(Graves et al., 2013; Cho et al.,2014)。受这种认识的启发,我们用多粒度扫描流程来增强级联森林。
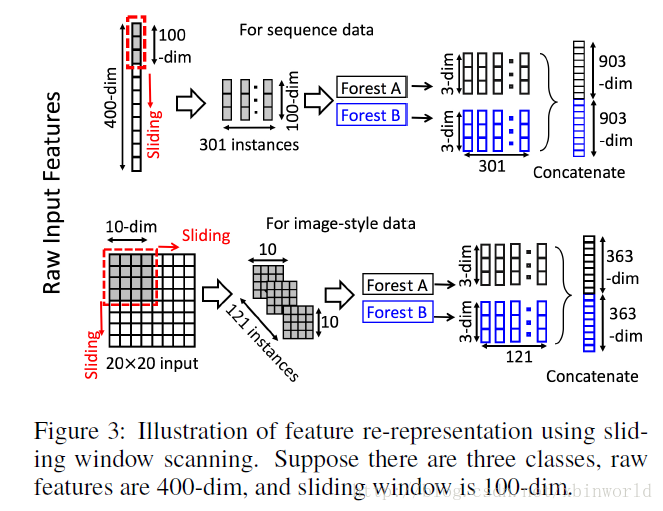
滑动窗口用于扫描原始特征。假设有400个原始特征,并且使用100个特征的窗口大小。对于序列数据,将通过滑动一个特征的窗口来生成100维的特征向量;总共产生301个特征向量。如果原始特征具有空间关系,比如图像像素为400的20×20的面板,则10×10窗口将产生121个特征向量(即121个10×10的面板)。从正/负训练样例中提取的所有特征向量被视为正/负实例;它们将被用于生成类向量:从相同大小的窗口提取的实例将用于训练完全随机树森林和随机森林,然后生成类向量并连接为转换后的像素。如上图的上半部分所示,假设有3个类,并且使用100维的窗口;然后,每个森林产生301个三维类向量,导致对应于原始400维原始特征向量的1,806维变换特征向量。通过使用多个尺寸的滑动窗口,最终的变换特征矢量将包括更多的特征,如下图所示。
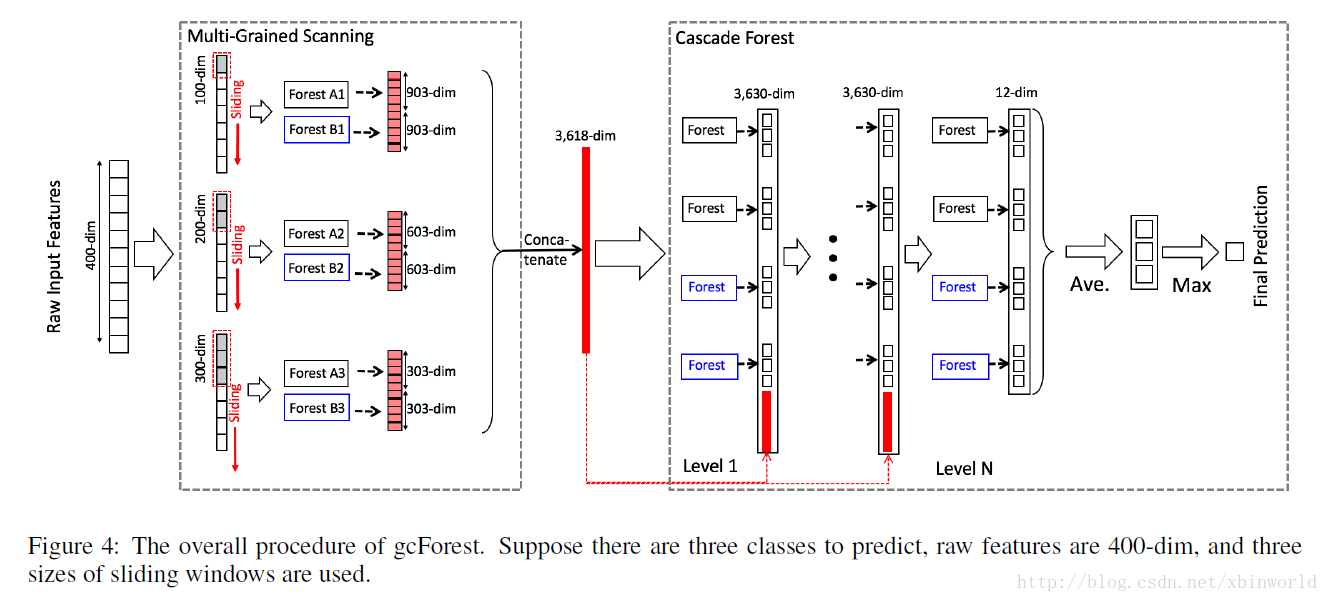
concat成一个3618-dim的原始数据,表示原始的一个数据样本,第一级的输出是12+3618=3630,后面也是一样,直到最后第N级,只有12个输出,然后在每一类别上做avg,然后输出max那一类的label,那就是最终的预测类别。