HIVE STORED&Row format(四)
转载自https://blog.csdn.net/mhtian2015/article/details/78873815
HIVE STORED&Row format
hive表数据在存储在文件系统上的,因此需要有文件存储格式来规范化数据的存储,一边hive写数据或者读数据。hive有一些已构建好的存储格式,也支持用户自定义文件存储格式。主要由两部分内容构成file_format和row_format,两者息息相关,在create table语句中结构如下:

[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
这里会涉及到STORED AS语法,实际上STORED AS file_format语法源于HIVE 0.14中出现的注册机制
,将{SerDe, InputFormat, and OutputFormat}三者绑定到STORED AS file_format语法从而更加便捷,也可以不包含SerDe,这样对于某些file_format,用户可以指定使用那个serde,从而更加多样化。
我们首先要理清InputFormat、OutputFormat与SerDe三者间的关系,直接引用官方的说法:
SerDe is a short name for “Serializer and Deserializer.”</br> Hive uses SerDe (and !FileFormat) to read and write table rows.</br> HDFS files –> InputFileFormat –> <key, value> –> Deserializer –> Row object</br> Row object –> Serializer –> <key, value> –> OutputFileFormat –> HDFS files</br> Note that the "key" part is ignored when reading, and is always a constant when writing. Basically row object is stored into the "value".</br>
从上边解释,不难理解三者之间的关系,下面对file_format和对应的serde进行分别介绍
STORED AS TEXTFILE
实际上等于:
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.IgnoreKeyTextOutputFormat'
作为纯文本文件存储,TEXTFILE默认是hive的默认存储方式,用户可以通过配置 hive.default.fileformat 来修改。STORED AS TEXTFILE中没有指定使用Serde,STORED AS TEXTFILE一般配合ROW FORMAT DELIMITED来使用,实际上若是没有指定ROW FORMAT或者使用了ROW FORMAT DELIMITED,则将使用自带的一个SerDe:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,因此ROW FORMAT DELIMITED语句实际上就是向LazySimpleSerDe传参数。与row format serde org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe with SERDEPROPERTIES(…)类似。文本文件实际上由各种分隔符定义。FIELDS TERMINATED BY char,定义了字段分割符,LINES TERMINATED BY char定义了行分隔符。使用ESCAPED BY语句来指定转义字符,例如 ESCAPED BY ‘’,如果你的数据中含有这些转义字符,则需要指定转义字符。null值可以使用NULL DEFINED AS来进行定义(默认为’N’)。
STORED AS SEQUENCEFILE
实际上等于:
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileOutputFormat'
存储为压缩的序列化文件。是hadoop中的标准序列化文件,可压缩,可分块。SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。在map/reduce过程中,map处理文件的临时输出就是使用SequenceFile处理过的。SequenceFile可以作为小文件的容器,可以通过它将小文件包装起来传递给MapReduce进行处理(即将文件名作为key,文件内容作为value序列化到大文件中)。
SequenceFile 有三种压缩态:
1.Uncompressed – 未进行压缩的状
2.record compressed - 对每一条记录的value值进行了压缩(文件头中包含上使用哪种压缩算法的信息)
3.block compressed – 当数据量达到一定大小后,将停止写入进行整体压缩,整体压缩的方法是把所有的keylength,key,vlength,value 分别合在一起进行整体压缩,块的压缩效率要比记录的压缩效率高
hive中通过设置SET mapred.output.compression.type=BLOCK;来修改SequenceFile压缩方式。
SequenceFile的格式可以参考此文
STORED AS RCFILE
实际上等于:
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
一般的存储方式是按行存储,rcfile是 按列存储,TextFile和SequenceFile都是基于行存储的存储结构,这里介绍下按行和列存储的优缺点:
基于行存储的数据结构:行存储保证了相同记录的所有域都在同一个集群节点;但是它不太满足快速的查询响应时间的要求,特别是在当查询仅仅针对所有列中的少数几列时,它就不能直接定位到所需列而跳过不需要的列,由于混合着不同数据值的列,行存储不易获得一个极高的压缩比。
在面向列的文件存储结构中,列A和列B存储在同一列组,而列C和列D分别存储在单独的列组。这种结构使得在查询时能够直接读取需要的列而避免不必要列的读取,并且对于相似数据也可以有一个更好的压缩比,并且非常适合做聚合操作。但是他的缺点也想但明显,那就是由于元组重构的较高开销,若是查询全部字段与行存储相比没有任何优势。 例如对于select *操作,列式存储需要对列重组开销较大,对于数据库来说不方便更新和删除操作,但是这些操作在hive中不常用。
结合列存储和行存储的优缺点,Facebook于是提出了基于行列混合存储的RCFile,该存储结构遵循的是“先水平划分,再垂直划分”的设计理念。RC File 将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。以下是rcfile的存储格式。
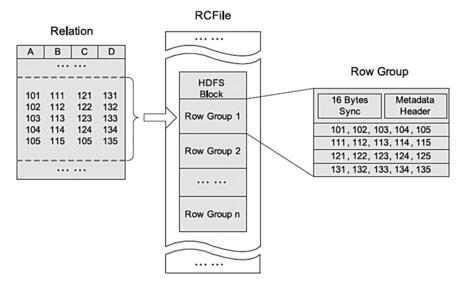
RCFile存储的表是水平划分的,分为多个行组,每个行组再被垂直划分,以便每列单独存储,RCFile的每个行组中,元数据头部和表格数据段(每个列被独立压缩)分别进行压缩,RCFile使用重量级的Gzip压缩算法,是为了获得较好的压缩比。另外在由于Lazy压缩策略,当处理一个行组时,RCFile只需要解压使用到的列,因此相对较高的Gzip解压开销可以减少。
STORED AS ORC/ORCFILE
实际上等于:
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
ORC (Optimized Record Columnar)是RC File 的改进,主要在压缩编码、查询性能上进行了升级; 在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。 
在默认情况下,一个stripe的大小为250MB,在file footer里面包含了该ORC File文件中stripes的信息,每个stripe中有多少行,以及每列的数据类型,每个stripe的数据offset信息。当然,它里面还包含了列级别的一些聚合的结果,比如:count, min, max, and sum。提供了多种RCFile中没有的indexes,这些indexes可以使ORC的reader很快的读到需要的数据,并且跳过无用数据,这使得ORC文件中的数据可以很快的得到访问。stripe footer包含每一列的编码方式和每个stream的位置信息,s实际上可以理解为stripe的头信息,具体可以参考文献7。
官方给出的orc优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载;
(2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
(3)、在文件中存储了一些轻量级的索引数据;
(4)、基于数据类型的块模式压缩:
a、integer类型的列用行程长度编码(run-length encoding);
b、String类型的列用字典编码(dictionary encoding);
(5)、用多个互相独立的RecordReaders并行读相同的文件;
(6)、无需扫描markers就可以分割文件;
(7)、绑定读写所需要的内存;
(8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
hive提供了一个命令orcfiledump来分析orc文件。想要深入了解orc格式、原理需要去读源码。
STORED AS PARQUET/PARQUETFILE
实际上等于:
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
源自于google Dremel系统,Parquet相当于GoogleDremel中的数据存储引擎,而Apache顶级开源项目Drill正是Dremel的开源实现。Apache Parquet 最初的设计动机是存储嵌套式数据,,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,是一件非容易和自然的事情。除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等。总的来说Parquet与orc相比的主要优势是对嵌套结构的支持,orc的多层级嵌套表达复杂底层未采用google dremel类似实现,性能和空间损失较大。
PARQUET使用definition and repetition levels来描述嵌套数据类型。有兴趣的话参考文档10.
STORED AS AVRO/AVROFILE
实际上等于:
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
AVRO是数据序列化系统,它可以提供:
1 丰富的数据结构类型
2 快速可压缩的二进制数据形式
3 存储持久数据的文件容器
4 远程过程调用RPC
5 简单的动态语言结合功能,Avro和动态语言结合后,读写数据文件和使用RPC协议都不需要生成代码,而代码生成作为一种可选的优化只值得在静态类型语言中实现。
Avro依赖于模式(Schema),schemas由json文件定义。Avro数据的读写操作都需要使用模式,这样就减少写入每个数据资料的开销,使得序列化快速而又轻巧。这种数据及其模式的自我描述方便于动态脚本语言的使用。
当Avro数据存储到文件中时,它的模式也随之存储,这样任何程序都可以对文件进行处理。如果需要以不同的模式读取数据,这也很容易解决,因为两个模式都是已知的。
当在RPC中使用Avro时,服务器和客户端可以在握手连接时交换模式。服务器和客户端有着彼此全部的模式,因此相同命名字段、缺失字段和多余字段等信息之间通信中需要解决的一致性问题就可以容易解决。
hive对AVRO进行支持,使用 AvroSerde来读写AVRO数据。
可以直接使用已有的schema来建表。使用avro.schema.url,例如:
CREATE TABLE kst
PARTITIONED BY (ds string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.url'='http://schema_provider/kst.avsc');
也可以直接使用 stored as AVRO/AVROFILE建表。但是目前不支持create as select语句来生成AVRO表。因为AVRO表需要schema,不管是指定schema,还是使用 stored as AVRO(将hive表结构转换为schema)实际上都指定了schema。但是create as不行。AVRO表的数据类型需要注意一下几点:
1.Types that may be null must be defined as a union of that type and Null within Avro. A null in a field that is not so defined will result in an exception during the save. No changes need be made to the Hive schema to support this, as all fields in Hive can be null.
2.Avro Bytes type should be defined in Hive as lists of tiny ints. The AvroSerde will convert these to Bytes during the saving process.
3.Avro Fixed type should be defined in Hive as lists of tiny ints. The AvroSerde will convert these to Fixed during the saving process.
4.Avro Enum type should be defined in Hive as strings, since Hive doesn’t have a concept of enums. Ensure that only valid enum values are present in the table – trying to save a non-defined enum will result in an exception.
你也可以使用avro.schema.literal来指定一个脚本文件来创建Avro表。
hive --hiveconf schema="${SCHEMA}" -f your_script_file.sqlset hiveconf:schema;
DROP TABLE example;
CREATE TABLE example
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.literal'='${hiveconf:schema}');
也可以直接在建表语句中描述schema
CREATE TABLE embedded
COMMENT "just drop the schema right into the HQL"
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
TBLPROPERTIES (
'avro.schema.literal'='{
"namespace": "com.howdy",
"name": "some_schema",
"type": "record",
"fields": [ { "name":"string1","type":"string"}]
}');
INPUTFORMAT and OUTPUTFORMAT
前边介绍的那些文件格式,实际上都是由INPUTFORMAT 和 OUTPUTFORMAT来进行定义的。
通过指定INPUTFORMAT 和 OUTPUTFORMAT对应的类来决定输入输出的处理方式,同时也要配合合适的Serde。比如LZO表的建立,就只能使用这种方式,貌似是lzo的授权问题,可以看到’INPUTFORMAT “com.hadoop.mapred.DeprecatedLzoTextInputFormat”是第三方包。使用LZO需要用户进行配置。
OUTPUTFORMAT “org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat”’
'INPUTFORMAT "com.hadoop.mapred.DeprecatedLzoTextInputFormat" OUTPUTFORMAT "org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat"'
STORED BY StorageHandler
这个语句使用非本地表的格式来存储,目的是创建或者链接到一个非本地表,例如HBASE,DRUID等,是hive与其他数据系统交互的重要方式。用户可以自定义StorageHandler。Besides HBase, a storage handler implementation is also available for Hypertable, and others are being developed for Cassandra, Azure Table, JDBC (MySQL and others), MongoDB, ElasticSearch, Phoenix HBase, VoltDB and Google Spreadsheets. A Kafka handler demo is available.
Storage Handler 可以基于hadoop和hive现有的可扩展功能进行构建 input formats、output formats、serialization/deserialization libraries,除了这些之外也可以实现新的元数据钩子接口,允许hive使用ddl来一致性的管理那些由hive元数据库和其他系统目录定义的对象。
这里引入了非本地表的概念(no-native),native 表就是hive没有使用storage handler,这里与之前说的managed和external表做区分。
managed native: what you get by default with CREATE TABLE external native: what you get with CREATE EXTERNAL TABLE when no STORED BY clause is specified managed non-native: what you get with CREATE TABLE when a STORED BY clause is specified; Hive stores the definition in its metastore, but does not create any files itself; instead, it calls the storage handler with a request to create a corresponding object structure external non-native: what you get with CREATE EXTERNAL TABLE when a STORED BY clause is specified; Hive registers the definition in its metastore and calls the storage handler to check that it matches the primary definition in the other system
Storage handlers通过在建表时使用STORED BY来引入。当指定了STORED BY,ROW FORMAT和STORED AS不能存在。可以通过SERDEPROPERTIES向Storage handlers传递参数。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [col_comment], col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name, ...)] INTO num_buckets BUCKETS] [ [ROW FORMAT row_format] [STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] ] [LOCATION hdfs_path] [AS select_statement]
如下hbase表
CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ( "hbase.columns.mapping" = "cf:string", "hbase.table.name" = "hbase_table_0" );
用户可以实现java接口来自定义Storage Handler :
package org.apache.hadoop.hive.ql.metadata;
import java.util.Map;
import org.apache.hadoop.conf.Configurable;
import org.apache.hadoop.hive.metastore.HiveMetaHook;
import org.apache.hadoop.hive.ql.plan.TableDesc;
import org.apache.hadoop.hive.serde2.SerDe;
import org.apache.hadoop.mapred.InputFormat;
import org.apache.hadoop.mapred.OutputFormat;
public interface HiveStorageHandler extends Configurable {
public Class<? extends InputFormat> getInputFormatClass();
public Class<? extends OutputFormat> getOutputFormatClass();
public Class<? extends SerDe> getSerDeClass();
public HiveMetaHook getMetaHook();
public void configureTableJobProperties(
TableDesc tableDesc,
Map<String, String> jobProperties);
}
在上边接口中HiveMetaHook是可选择的,我们下边将会介绍,若是getMetaHook返回值不为null,对元数据的修改操作将会调用返回HiveMetaHook对象的方法。configureTableJobProperties 方法在hadoop计划执行job时调用,它的主要作用是检查表定义和设置合适的job属性,在执行时,只有jobProperties 在 input format, output format, and serde中是可用的。
HiveMetaHook Interface
package org.apache.hadoop.hive.metastore;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.metastore.api.Partition;
import org.apache.hadoop.hive.metastore.api.Table;
public interface HiveMetaHook {
public void preCreateTable(Table table)
throws MetaException;
public void rollbackCreateTable(Table table)
throws MetaException;
public void commitCreateTable(Table table)
throws MetaException;
public void preDropTable(Table table)
throws MetaException;
public void rollbackDropTable(Table table)
throws MetaException;
public void commitDropTable(Table table, boolean deleteData)
throws MetaException;
不管是否配置使用metastore来存储创建表的元数据,HiveMetaHook 将会在hive客户端的jvm处调用(并不是metastore的服务器处),这意味着jar包在客户端处必须是可用的。
以上主要介绍了file format(Storage Formats),涉及到了一些file format的相关的serde,Row Formats & SerDe的具体细节,下节介绍。
参考文献
1.hive官方文档
2.hive developerGuide
3.https://issues.apache.org/jira/browse/HIVE-5976
4.Hadoop 中SequenceFile的简介
5.rcfile
6.rcfile wiki
7.orc Stripes
8.orc hive
9.orc configuration
10.Dremel made simple with Parquet
11.hive Parquet
12.百科 AVRO
13.AVRO 官网
14.hive AvroSerDe
15.LanguageManual LZO
16.hive StorageHandlers