一. 线程状态类型
1. 新建状态(New):新创建了一个线程对象。
2. 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3. 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
4. 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。

二Executor框架的成员
在开发过程中,合理地使用线程池能够带来3个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,
还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
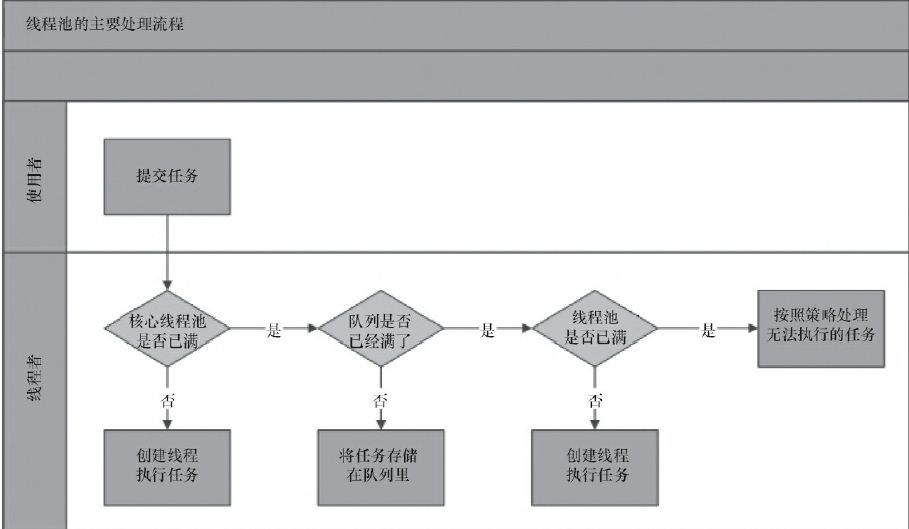
采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行将任务存储在队列里,而步骤2不需要获取全局锁。
2.1 ThreadPoolExecutor
2.1.1创建线程
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime,milliseconds,runnableTaskQueue, handler);或者使用工厂类Executors来创建。
也可以可以创建三种 singleThreadExecutor、FixedThreadPool和CachedThreadPool。
FixedThreadPool使用无界队列LinkedBlockingQueue作为线程池的工作队列(队列的容量为Integer.MAX_VALUE)。使用无界队列作为工作队列会对线程池带来如下影响。
1)当线程池中的线程数达到corePoolSize后,新任务将在无界队列中等待,因此线程池中的线程数不会超过corePoolSize。
2)由于1,使用无界队列时maximumPoolSize将是一个无效参数。
3)由于1和2,使用无界队列时keepAliveTime将是一个无效参数。
4)由于使用无界队列,运行中的FixedThreadPool(未执行方法shutdown()或shutdownNow())不会拒绝任务(不会调用RejectedExecutionHandler.rejectedExecution方法)。
SingleThreadExecutor的corePoolSize和maximumPoolSize被设置为1,使用无界队列LinkedBlockingQueue作为线程池的工作队列,影响与FixedThreadPool相同。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
CachedThreadPool的corePoolSize被设置为0,即corePool为空;maximumPoolSize被设置为Integer.MAX_VALUE,即maximumPool是无界的。这里把keepAliveTime设置为60L,意味着空闲线程等待新任务的最长时间为60秒,空闲线程超过60秒后将会被终止。使用无界队列LinkedBlockingQueue作。极端情况下会因为创建过多线程而耗尽CPU和内存资源。
2.1.2执行线程
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值,get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
threadsPool.execute(new Runnable() {
@Override
public void run() {
}
});
2.2周期任务执行器
·ScheduledThreadPoolExecutor。包含若干个线程,适用于需要多个后台线程执行周期任务,同时为了满足资源管理的需求而需要限制后台线程的数量的应用场景。
1)当调用ScheduledThreadPoolExecutor的scheduleAtFixedRate()方法或者scheduleWith-FixedDelay()方法时,会向ScheduledThreadPoolExecutor的DelayQueue添加一个实现了RunnableScheduledFutur接口的ScheduledFutureTask。
2)线程池中的线程从DelayQueue中获取ScheduledFutureTask,然后执行任务。
SingleThreadScheduledExecutor。只包含一个线程,适用于需要单个后台线程执行周期任务,同时需要保证顺序地执行各个任务的应用场
3.合理地配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
·任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
·任务的优先级:高、中和低。
·任务的执行时间:长、中和短。
·任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能小的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务
和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。建议使用有界队列。
I/O bound 指的是系统的CPU效能相对硬盘/内存的效能要好很多,此时,系统运作,大部分的状况是 CPU 在等 I/O (硬盘/内存) 的读/写,此时 CPU Loading 不高。
CPU bound 指的是系统的 硬盘/内存 效能 相对 CPU 的效能 要好很多,此时,系统运作,大部分的状况是 CPU Loading 100%,CPU 要读/写 I/O (硬盘/内存),I/O在很短的时间就可以完成,而 CPU 还有许多运算要处理,CPU Loading 很高