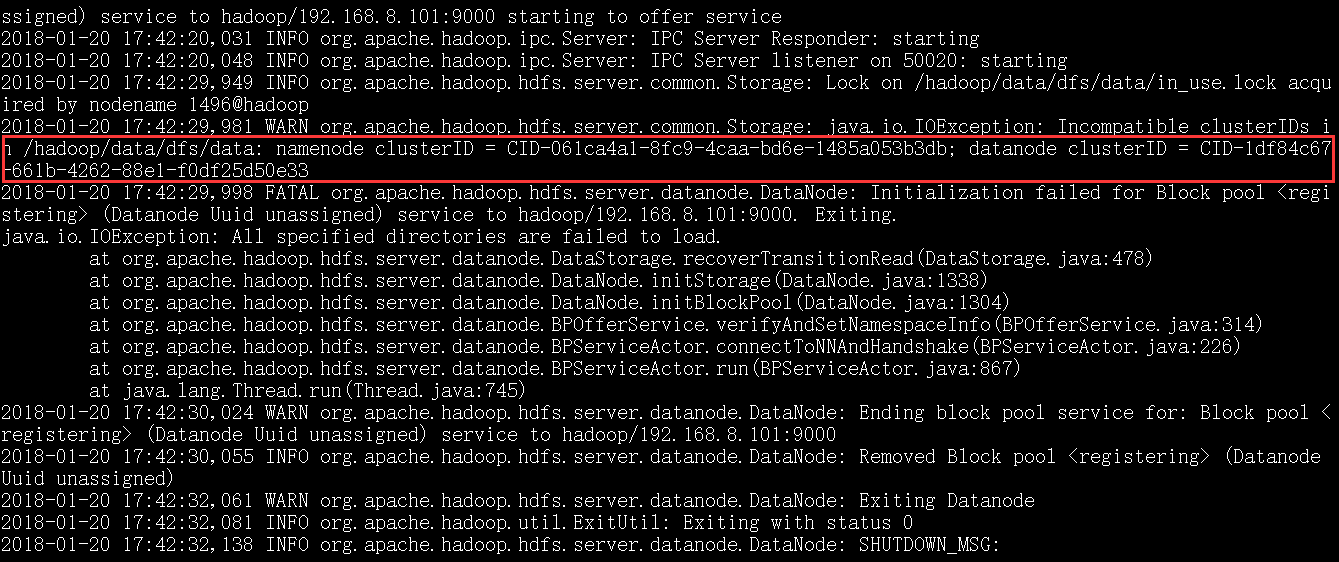
从截图上看是datanode的clusterID 和 namenode的clusterID 不匹配。
解决办法:
根据日志中的路径,cd /hadoop/data/dfs/
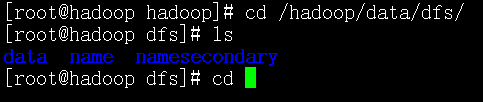
能看到 data和name两个文件夹,
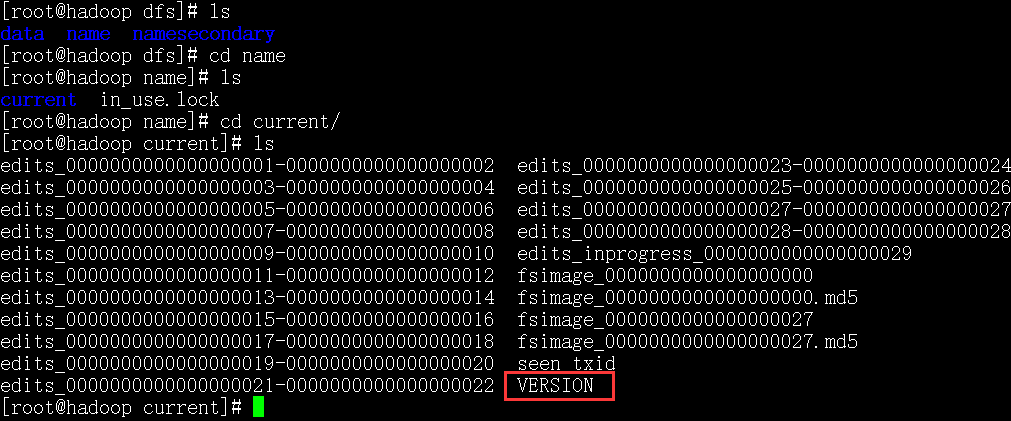
将name/current下的VERSION中的clusterID复制到data/current下的VERSION中,覆盖掉原来的clusterID
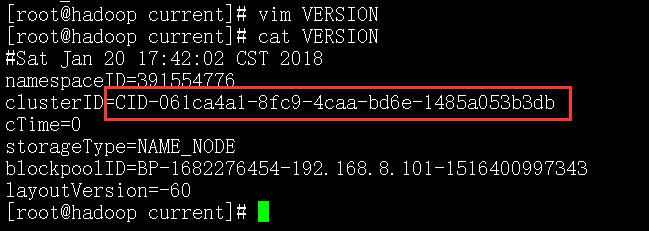
让两个保持一致
然后重启,启动后执行jps,查看进程
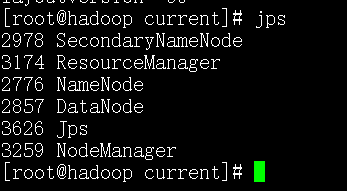
出现该问题的原因:在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。
说白了就是用了几次格式化命令!