字符串(str)
可以存储少量的数据并进行相应的操作
- 相加相乘
- 相加:就是字符串拼接,必须都是字符串才能相加,不能相减
- 相乘:字符串和数字相乘,不能相除
a = '世界'
b = '你好'
print(a + b) # 世界你好
print(b * 3) # 你好你好你好
索引切片
-
索引:对字符串进行索引排号,又称为下标,0为起始,每次加1
语法:
str[index]
name = 'meet'
# 索引: 0123
print(name[0]) # m
- 索引倒序:从右向左倒序排号,-1为起始每次减1
name = 'meet'
# 索引 -4-3-2-1
print(name[-1]) #t
-
切片:在字符串中获取一段字符输出
语法:
str[start_index:end_index]- start_index:起始索引
- end_index:结尾索引,尾索引实际取值要加一
注意:以首元素为起始索引、尾元素为结束索引结束可不写
name = 'hello'
# 索引: 01234
print(name[2:4]) # ll
print(name[2:]) # llo(从索引2取到尾)
print(name[:-3]) # he(后三位不取)
-
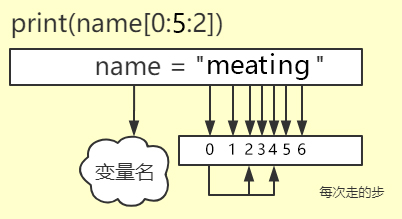
步长:切片里输出字符间隔的长度,默认为1 ,逐位输出
语法:
str[start_index:end_index:步长]
name = 'meating'
# 索引: 0123456
print(name[0:5:2]) # mai(从切片的首位开始每间隔一位输出)
- 步长倒序:切片倒序必须为负,索引从右往左以负数切片,步长也必须为负(尾索引实际取值要减一)
s = 'hello你好'
print(s[-1:-3:-1]) # 好你(输出切片每一位)
print(s[-3::-2]) # olh(切片每间隔一位输出)
print(s[::-1]) # 好你olleh(全取倒序输出)
操作方法
字母操作
- 转换大写:
str.upper() - 转换小写:
str.lower()
应用场景:填验证码不区分大小写
username = input('用户名:')
password = input('密码:')
code = 'QwEr'
print(code)
your_code = input('不区分大小写验证码:')
if your_code.upper() == code.upper():
# 如果输入的验证码的大写版与设定的验证码大写版相等
if username == '小王' and password == '123':
print('欢迎')
else:
print('用户名密码错误')
else:
print('验证码错误')
- 大小写反转:
str.swapcase()
a = 'AHDDdsnda'
print(a.swapcase()) # ahddDSNDA
- 首字母大写
str.capitalize():首字母大写,其余变小写
str.title():每个单词的首字母大写首字母大写,其余变小写
注意:只要以非字母隔开都认为是一个单词
a = 'taiBI sAy中hi'
print(a.capitalize()) # Taibi say中hi
print(a.title()) # Taibi Say中Hi
-
判断以什么字符为开头:
str.startswith(substr, beg=0,end=len(string)) -
判断以什么字符为结尾:
str.endswith()(同语法)- substr:指定的元素或切片,可设定多个
- beg:设置字符串检测的起始位置,默认从头
- end:设置字符串检测的结束位置,默认到尾
s = 'taiBAifdsa'
print(s.startswith('t')) # True
print(s.endswith('a')) # True
print(s.endswith('ifdsa')) # True(与尾字符挨着的均可)
print(s.endswith('BAi',2,6)) # True(切片判断)
字符操作
-
字符串替换:
str.replace(old, new, max) -
- old:将被替换的子字符串
- new:新字符串,用于替换old子字符串
- max:指定替换次数,默认全部替换
msg = 'wang很nb wang很帅wang 有钱'
msg = msg.replace(' ','') # 将所有空格替换去掉
msg1 = msg.replace('wang','小王') # 替换wang为小王,默认全部替换
# 结果:小王很nb小王很帅小王有钱
msg2 = msg.replace('wang','小王',2) # 替换wang为小王,从左至右替换2次
# 结果:小王很nb小王很帅wang有钱(只替换了前两个)
print(msg1,msg2)
- 去除:
str.strip()(默认去除空格)
注意:从左右两边同时向中间开始检查,遇到空格、中文会停止
s = '
你好 ' #
:换行 :空四格(等效Tab)
print(s)
s1 = s.strip() # 去除s两边的空格
print(s1)
str.strip(指定字符) :去除指定字符,可乱序排列
机制:遇空格、中文停下,必须是与首字符顺序、尾字符倒序挨着的才可一起除去,不可从中间去除
s = 'abcde你好fg'
print(s.strip()) # 默认去除所有空格
print(s.strip('abc')) # 去除指定字符
print(s.strip('好cbagf你')) # 可乱序排列指定去除字符
分割连接
- 分割:
str.split()(括号内为空默认按空格分割)
str ---> list:字符串返回列表
s1 = '你好 我好 他好' # 默认按照空格分隔
print(s1.split()) # 结果:['你好', '我好', '他好']标准列表格式
str.split('指定分隔符') :指定分隔符符号,以指定的符号来分割字符串,返回列表
s1 = '你好#我好#他好'
s = s1.split('#') # 指定以#为分隔符
print(s) # 结果:['你好', '我好', '他好']
str.split('指定分隔符',分割次数) :控制分割次数,其余的相同符号可不分割
s1 = ':你好:我好:他好'
s = s1.split(':',2) # 指定以冒号为分隔符,只分割2次
print(s) # 结果:['', '你好', '我好:他好']
- 连接:
'连接符'.join(str)(每个字符之间用指定的连接符号接合起来)
s1 = 'alex'
s2 = '+'.join(s1) # 每个字符之间用加号连接起来
print(s2) # 结果:a+l+e+x
list ---> str:列表里面的元素必须都是str类型才能连接
s1 = ['你好', '我好', '他好'] # 前提:列表里面的元素必须都是str类型
s = ':'.join(s1) # 把每个元素以冒号连接
print(s) # 结果:你好:我好:他好
统计居中
- 获取长度:
len(对象)(获取对象的长度是多少)
- 计数:
str.count(sub, start= 0, end=len(string))(某元素出现的次数)- sub:搜索的子字符串
- start:字符串开始搜索的位置,默认索引值为 0
- end:字符串中结束搜索的位置,默认到结尾
注意:返回结果的数字为整型
s = 'sdfsdagsfdagfdhgfhg'
s1 = s.count('d') # 计算s出现的次数
print(s1, type(s1)) # 4(表示出现了4次,这里的数字是int类型)
print(s.count('d',0,4)) # 2(计算两索引间d出现的次数)
- 查找下标
str.find('字符') :通过元素找索引,找到第一个就返回,找不到就返回-1(整型)
str.index('字符') :通过元素找索引,找到第一个就返回,找不到就报错
- 居中:
srt.center(宽度,fillchar)(fillchar:居中左右两边填充的字符,默认为空)
a = 'hi'
print(a.center(10)) # | hi |
print(a.center(10,'+')) # |++++hi++++|
format() 格式化
"{} {}".format(对应位置一, 对应位置二) :不设置指定位置,按默认顺序
msg = '我叫{}今年{}性别{}'.format('大壮', 25, '男') # 括号内容顺序填入对应大括号中
print(msg) # 结果:我叫大壮今年25性别男
"{0} {1} {0}".format(字符0, 字符1) :将字符设置指定序号,序号可重复用
msg = '我叫{0}今年{1}性别{2}我依然叫{0}'.format('大壮', 25, '男')
print(msg) # 结果:我叫大壮今年25性别男我依然叫大壮
'{age} {sex} {age}'.format(sex=变量, age=数字) :将字符设置指定变量名,可重复用,可对应变量
a = 18
msg = '我叫{name}今年{age}性别{sex}我依然叫{name}'.format(age=a, sex='男', name='大壮')
print(msg) # 结果:我叫大壮今年18性别男我依然叫大壮
is 系列
str.isalnum() :判断字符串是否由字母或数字组成
str.isalpha() :判断字符串是否只由字母组成(中文也算)
str.isdecimal() :判断字符串是否只由正整数组成
注意:判断结果返回布尔值(有符号或空格结果:False)
name = 'taibai123'
print(name.isalnum()) # 结果:True
print(name.isalpha()) # 结果:False(中文:True)
print(name.isdecimal()) # 结果:False