什么是漏斗?
提起漏斗,让我首先想到的是它的 形状:圆锥形的、顶部宽底部窄;其次是它的 功能:过滤杂质,如生了虫的白面、炸过豆腐的油等。
形状
如下图形状才能够有效的行使它的功能职责 — 过滤。

功能
过滤杂质
生了虫的白面
小时候的农村,夏天雨水较多,家里比较潮湿,缸里的面经常会有虫子光顾。
那个时候物质匮乏,不舍的扔掉,会把虫子以及结块的面粉经过筛子(筛子及漏斗)给过滤掉,然后继续吃过筛的面粉。
炸过豆腐的油
过年的时候,会炸几片豆腐,俗称过油豆腐。然后炸过豆腐的油,里边会有一些豆腐渣子残留,为了重复利用油,会拿油漏把豆腐渣子给过滤掉,然后漏下的油在下次炒菜的时候继续用。
什么是漏斗模型?
漏斗我们知道了,那什么是模型呢?
模型一般是指对事物、规律等进行抽象后的一种形式化表达方式。
大部分的模型都是由三部分组成的,即目标、变量和关系。
漏斗模型就是对漏斗的形状和功能进行抽象后的一种形式化表达方式,通过目标、变量和关系对数据进行分析。
目标
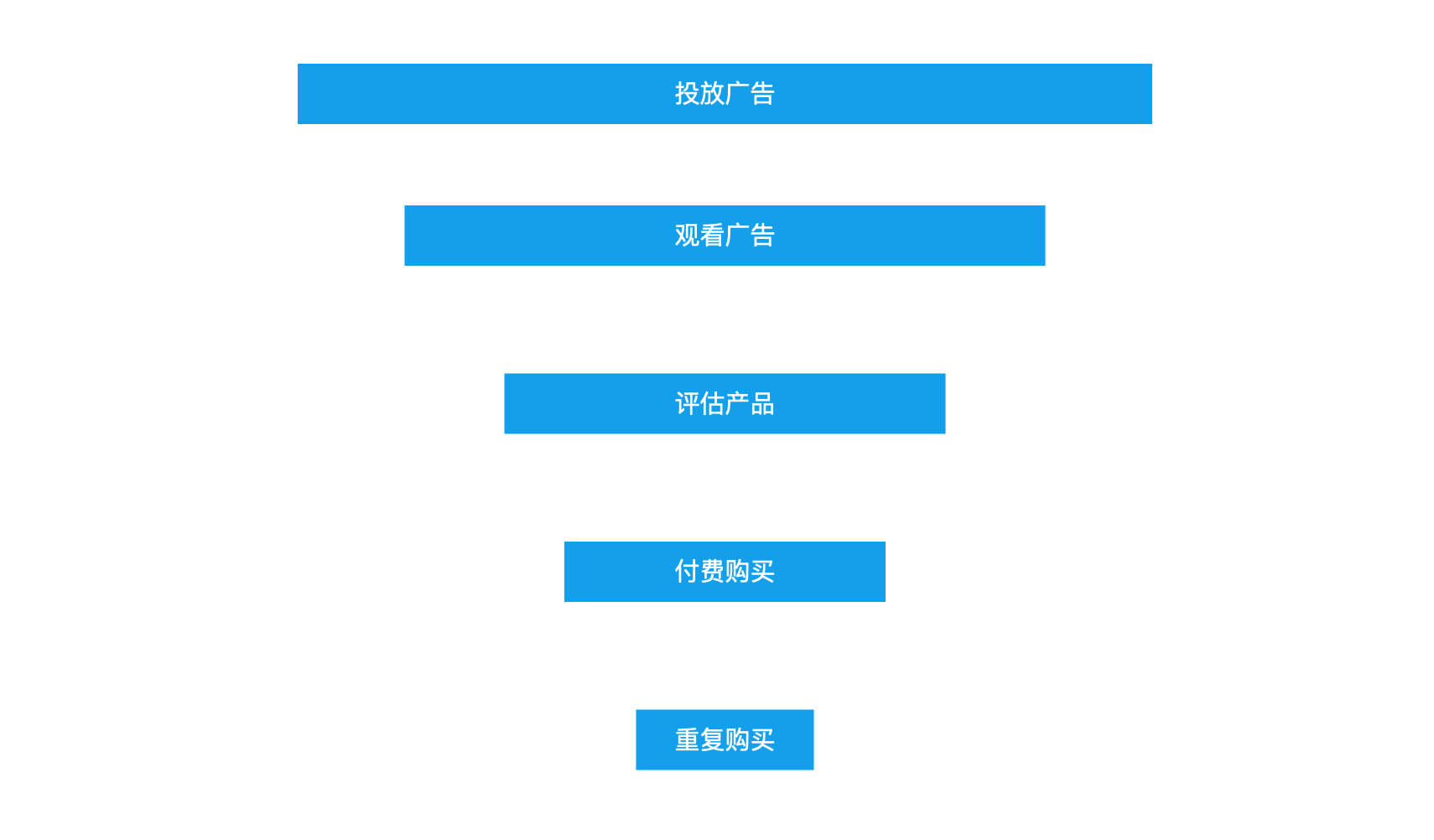
在使用漏斗模型进行分析之前,首先需要明确目标,知道需要做什么。比如传统漏斗模型,最早起源于传统行业的商业营销活动中,目标就是商业变现。
- 投放广告,提高用户对品牌的认知,占领用户的心智;
- 观看广告,提高用户对产品的兴趣;
- 评估产品,用户会根据对品牌认证和产品兴趣来决定是否购买;
- 付费购买,用户会对评估完后感兴趣的产品进行购买,达成交易;
- 重复购买,部分用户会持续重复购买,也可能推荐给亲戚朋友。
以上是传统的金典的漏斗模型,是一种收缩型思维,每一步之间都可能会因为各种不确定变量而被过滤掉。
变量
在明确了漏斗模型的目标以后,才能进一步确定影响目标的各关键变量。
变量又分为自变量、因变量和中介变量。
因变量 在组织行为学中就是所要测量的行为反应,而 自变量 则是影响因变量的变量。
如上边传统漏斗模型,因变量是广告观看率、商品付费率、重复购买率等,那么广告的投放渠道(如电视、报纸杂志、地铁、门户网站等)、观看广告的用户年龄层次、用户所在的区域、用户的兴趣爱好、用户的经济条件等就是影响因变量的自变量。
中介变量 又称为干扰变量,它会削弱自变量对因变量的影响。中介变量的存在会使自变量与因变量之间的关系更加复杂。
中介变量也就是我们需要介入的变量,需要我们去无限的进行解构,来影响自变量。比如从 A 到 R (获客 - 盈利)的转换问题,我们可以把 A 拆分为 A1、A2、A3,再看哪一步对自变量的影响比较大,假设是 A2,那么再把 A2拆开,再看其中的主要问题。
如上边传统的漏斗模型,假设我们的品牌为高端奢侈品,那么我们需要对投放渠道、用户年龄层次、投放区域等进行拆分。然后发现我们的投放区域覆盖面太多,成本比较高。然后我们对投放地区进行拆分,发现偏远地区投放占比比较高,那么这个时候,我们是否找到了问题呢?我们可以收缩投放区域,有针对性的在北上广深等这样的大城市集中投放会不会效果更好一些呢?
最理想的状态是,我们能够解构到唯一变量的颗粒度。然后我们就能够精准定位并且解决这个问题,从而带来增长。
如果我们用的漏斗是一个很粗略的漏斗,是无法解决问题的。需要一步步解构、定位问题,然后去解决,这样才能带来有效的增长。
关系
确定了目标,确定了影响目标的各种变量之后,还需要进一步研究各变量之间的关系。在确定变量之间的关系时,对何者为因、何者为果的判断,应持谨慎态度。不能因为两个变量之间存在着统计上的关系,就简单地认为他们之间存在着因果关系。对变量间因果关系的判断不能轻率。
用户增长漏斗转化
很多时候我们谈增长,更多的是在谈获客,而没有考虑如何提升现有用户的转化率、激活率。我们需要考虑如何才能让用户变成忠诚用户,只有忠诚用户才不会流失,才能带来更多的收益。

通过漏斗分析可以从前到后还原用户转化的路径,分析每一个转化节点的效率。
- 从开始到结尾,整体的转化率是多少?
- 每一步的转率是多少?
- 哪一步流失最多,原因是什么?流失的用户符合哪些特征?
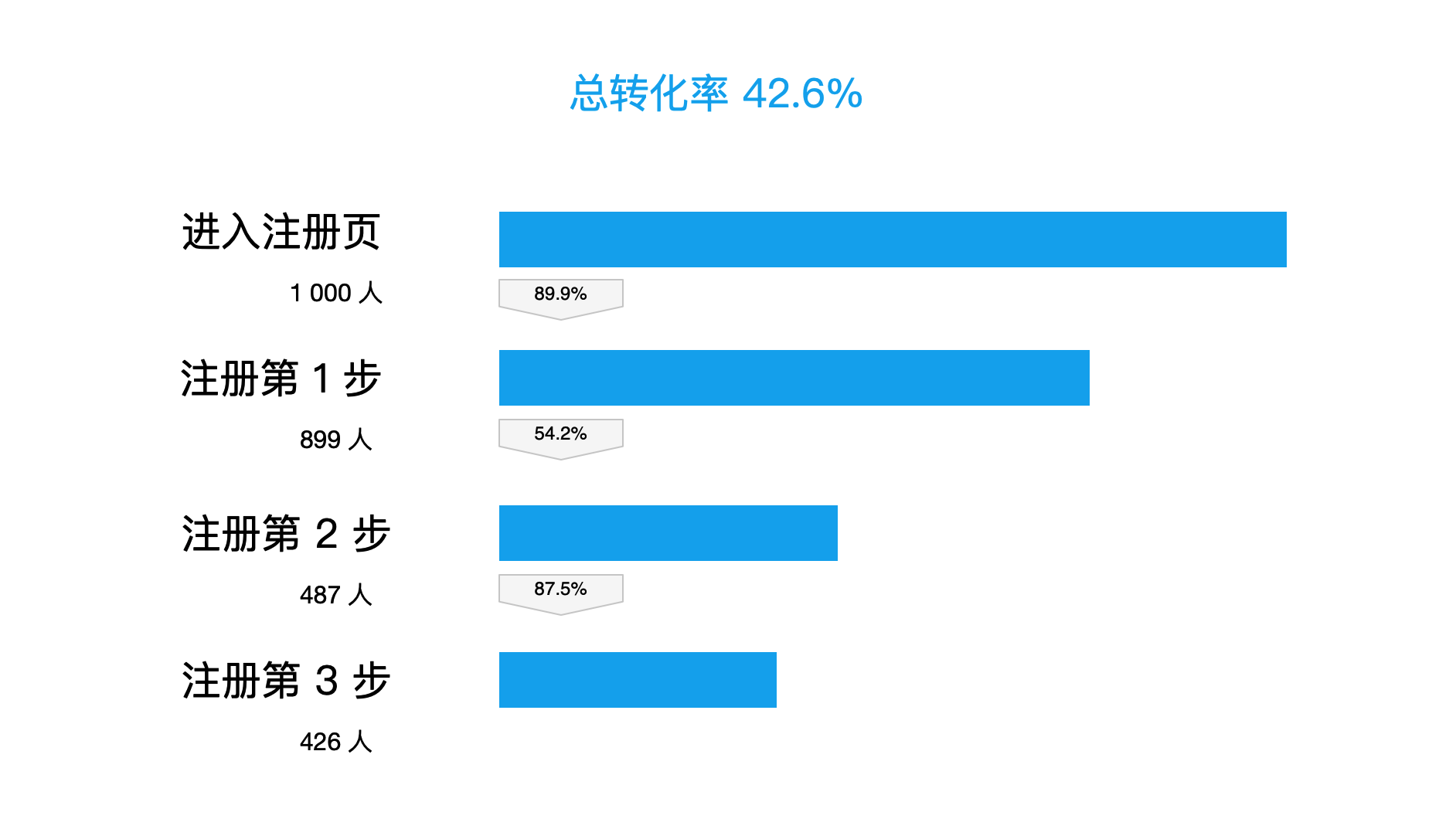
上图中注册流程分为 3 个步骤,总体转化率为 42.6%,也就是说有 1000 个用户来到注册页面,其中 426 个成功完成了注册。
但是我们不难发现注册第 2 步的转化率是 54.2%,明显低于注册第 1 步的 89.9% 和 第三步的 87.5%,可以推测注册第 2 步流程存在问题。
显而易见注册第 2 步的提升空间是最大的,投入回报比肯定不低;如果要提高注册转化率,我们应该优先解决注册第 2 步。
请关注公众号:白胡子海盗
