今天分析一波蜂鸟网,话不多说,先来一波网址,url =“ http://image.fengniao.com/index.php#p=1”,首先一个美女图片瞧瞧,
分析一波网页,找到网站的分页特点,该网站请求方式为ajax请求,那么各位看官瞧仔细了,F12打开,鼠标轱辘往下翻,你会发现:
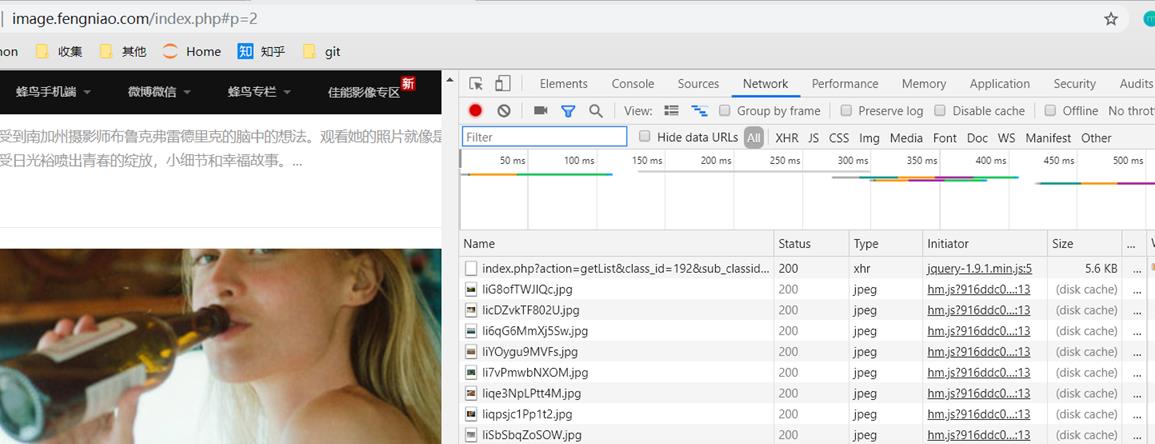

有什么发现么,页数变为2,还有一堆信息,点击右边第一个链接访问,一个新大陆在你眼前:
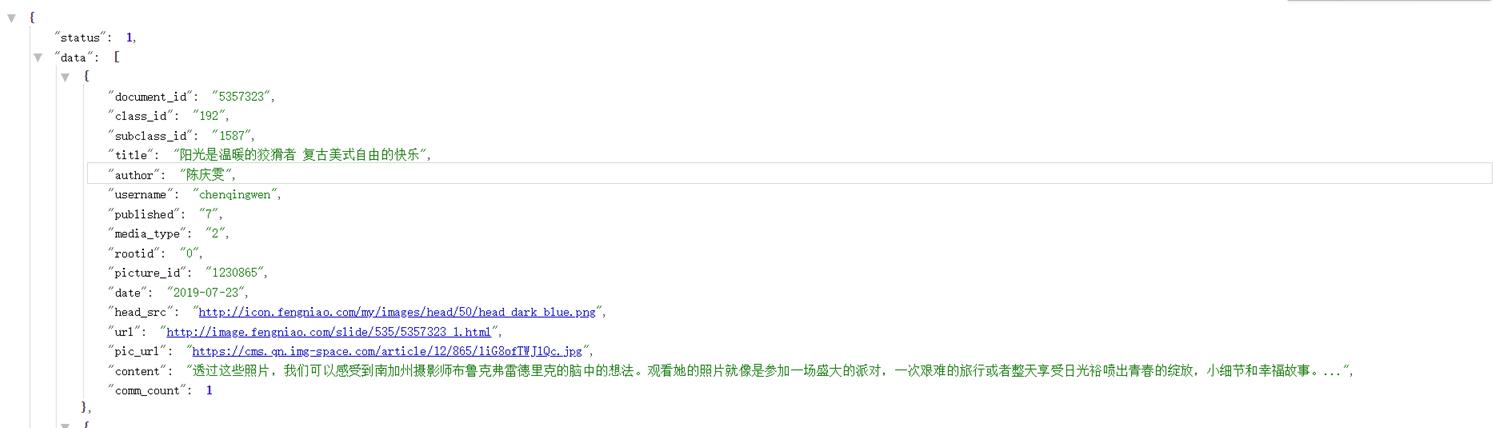

没错,该网页格式返回为json格式,还有一个高大上的名字====》该网站“API”,是不是有点小激动,相信如果学习过这方面知识的小伙伴可以自行发现搓掌敲代码了,好,今天就到此结束了。
你看到这里,小编甚是高兴!那么接下来还是搞事情的节奏,光有数据不行呀,我们需要的是图片。。。。
下面开始上代码:
最好有一些面型对象以及线程的知识,这样对下面代码好理解!
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 # author:albert time:2019/7/29 4 import threading 5 import time 6 import json 7 import re 8 import requests 9 import os 10 11 12 imgs_url_list = [] 13 # 图片操作锁 14 imgs_lock = threading.Lock() 15 16 '''继承threading.Thread''' 17 class Product(threading.Thread): 18 '''初始化''' 19 def __init__(self): 20 super(Product, self).__init__(self) 21 self.__headers = { 22 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', 23 "Referer": "http://image.fengniao.com/", 24 "Host": "image.fengniao.com", 25 "X-Requested-With": "XMLHttpRequest" 26 } 27 self.__start = "http://image.fengniao.com/index.php?action=getList&class_id=192&sub_classid=0&page={}¬_in_id={}" 28 29 def run(self): 30 index = 2 #起始页数 31 not_in = "5352384,5352410" 32 while index < 1000: 33 url = self.__start.format(index,not_in) 34 # print('开始操作:%s' %url) 35 print('开始操作:{}'.format(url)) 36 index += 1 37 content = requests.get(url,headers = self.__headers).text 38 if content is None: 39 print('ok,没有你的东西了,客官请回。。。。。') 40 continue 41 time.sleep(3) 42 json_content = json.loads(content) 43 # print(json_content) 44 if json_content['status'] == 1: 45 for item in json_content['data']: 46 title = item['title'] 47 child_url = item['url'] 48 '''图片链接''' 49 img_content = requests.get(child_url,headers=self.__headers).text 50 #这里需要解释一下,为什么设置匹配pic_url_1920_b后面的,你可以自行print=>img_content,自会晓得 51 pattern = re.compile('"pic_url_1920_b":"(.*?)"') 52 imgs_json = pattern.findall(img_content) 53 # print(imgs_json) 54 if len(imgs_json) > 0: 55 imgs_lock.acquire() 56 '''查询的时候方便''' 57 imgs_url_list.append({'title': title, 'url': imgs_json}) 58 imgs_lock.release() 59 60 61 class Consumer(threading.Thread): 62 def __init__(self): 63 super(Product, self).__init__(self) 64 self.__headers = { 65 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36', 66 "Referer": "http://image.fengniao.com/", 67 "Host": "image.fengniao.com", 68 "X-Requested-With": "XMLHttpRequest" 69 } 70 def run(self): 71 72 while True: 73 if len(img_list) <= 0: 74 continue # 进入下一次循环 75 76 if imgs_lock.acquire(): 77 data = img_list[0] 78 del img_list[0] # 删除第一项 79 80 imgs_lock.release() 81 # print(data) 82 '''双其实是转义后面斜杠,要不会报错''' 83 urls =[url.replace("\","") for url in data["url"]] 84 # print(urls) 85 # 创建文件目录 86 os.makedirs('./image/', exist_ok=True) 87 for item_url in urls: 88 try: 89 # print(item_url) 90 # file = requests.get(item_url,headers = self.__headers,timeout=2) 91 file = requests.get(item_url) 92 time.sleep(2) 93 # print(file.status_code) 94 # print(item_url) 95 with open('./image/{}.jpg'.format(str(time.time())),'wb') as f: 96 f.write(file.content) 97 except Exception as e: 98 print(e) 99 100 if __name__ == '__main__': 101 p = Product() 102 p.start() 103 c = Consumer() 104 c.start() 105