linux正则表达式
正则表达式(REGULAR):为处理大量的字符串而定义的一套规则和方法
Linux中适用于:grep egrep awk sed 命令
这里我们介绍grep命令,并于正则结合使用
grep
(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
选项说明:
-a 不要忽略二进制数据。
-A <显示列数> 除了显示符合范本样式的那一行之外,并显示该行之后的内容。
-b 在显示符合范本样式的那一行之外,并显示该行之前的内容。
-c 计算符合范本样式的列数。
-C <显示列数>或-<显示列数> 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d <进行动作> 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e <范本样式> 指定字符串作为查找文件内容的范本样式。
-E 将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。
-f <范本文件> 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 将范本样式视为固定字符串的列表。
-G 将范本样式视为普通的表示法来使用。
-h 在显示符合范本样式的那一列之前,不标示该列所属的文件名称。
-H 在显示符合范本样式的那一列之前,标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件内容符合指定的范本样式的文件名称。
-L 列出文件内容不符合指定的范本样式的文件名称。
-n 在显示符合范本样式的那一列之前,标示出该列的编号。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
正则匹配说明:
^ 匹配首字符
$ 匹配尾字符
^& 匹配空行
. 匹配任意一个字符
* 重复前面任意0或者多个字符
.* 匹配所有字符
[abc] 匹配字符集内的任意一个字符 [0-9]匹配0-9 [a-z] a-z
[^abc] 不匹配字符集内的任意字符,相当于取反
w 只打印字母
W 打印非字母
匹配单词的定界符
d 匹配数字
...
实例(仅演示grep常用选项 -n -v -i -c及部分正则命令):
新建zen文件,并向其写入如下内容:
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!

在zen文本中查找S(大写),并返回匹配的行总数(此时返回3代表文本中有三行包含"S")

加上
-i参数后,以不区分大小写方式查找,返回结果20

不区分大小写查找并显示行号
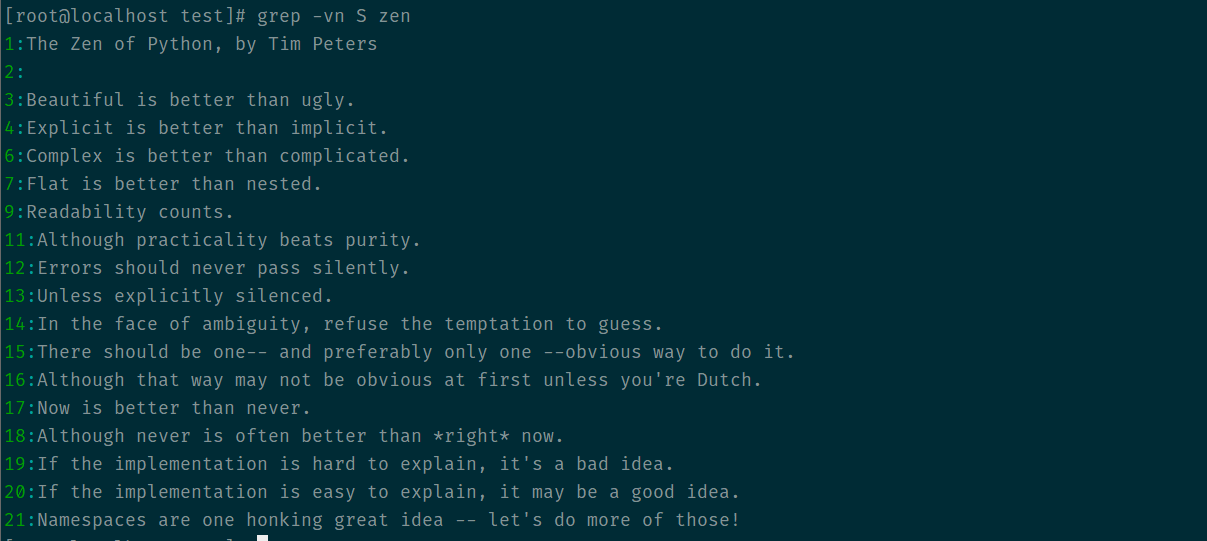
-v选项代表反转查找 故显示除包含S的行

^字符用来匹配首字符(图中匹配S开头的行)

$字符用来匹配尾字符(图中匹配s结尾的行)

当
^$同时使用即可匹配空行 如图匹配本实例文档第二行空行内容 (搭配-v可以显示所有非空行)
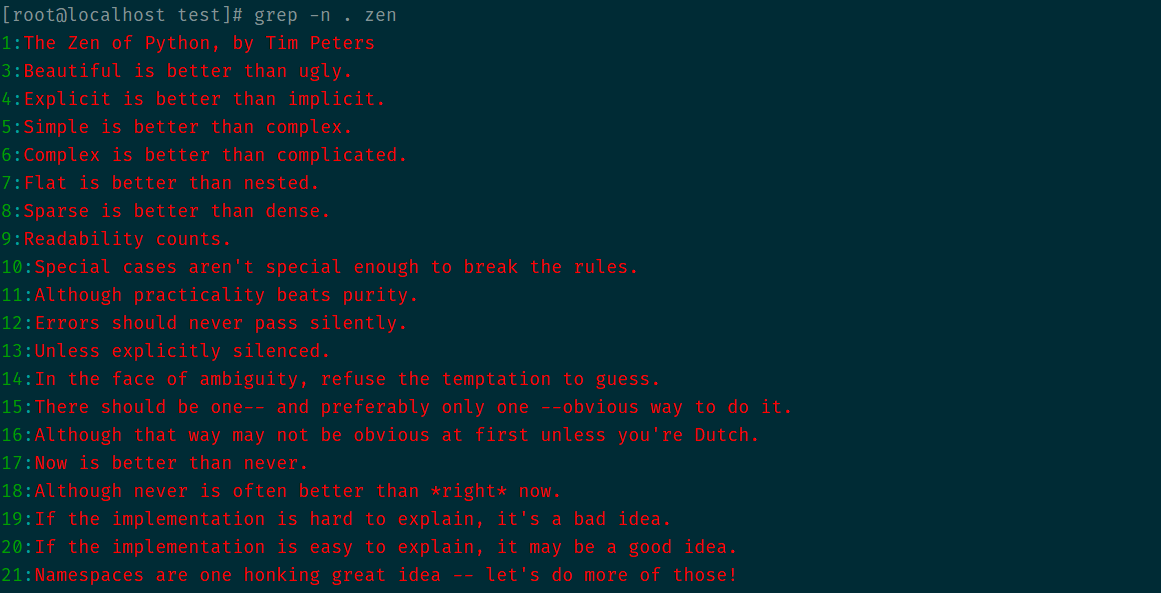
.用来匹配任意一个字符 故全匹配
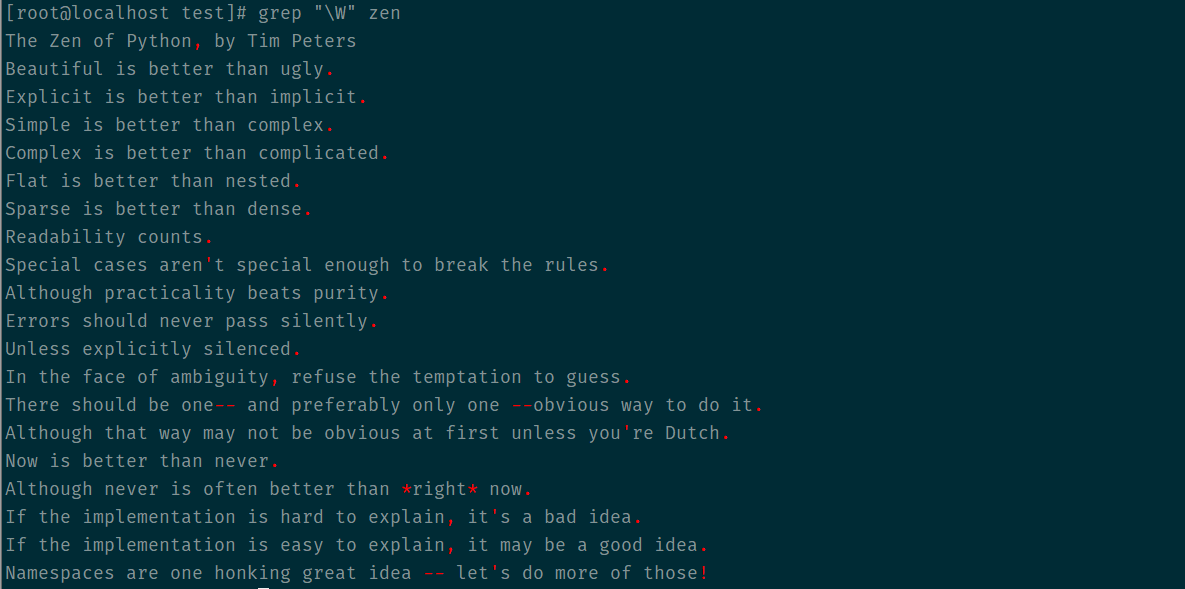
W匹配所有非字母
总之,正则是一个非常强大的工具,不仅限于linux,由于博主也是接触不久,本文仅仅介绍linux基础使用,随着学习的深入,在今后的学习中在来讨论更多正则相关的用法和技巧。