一、程序结构分析
注:本部分的数据和图例均来自IDEA的插件MetricsReloaded、Statistic和UML。
1、第一次作业
(1)类方法的复杂度进行分析
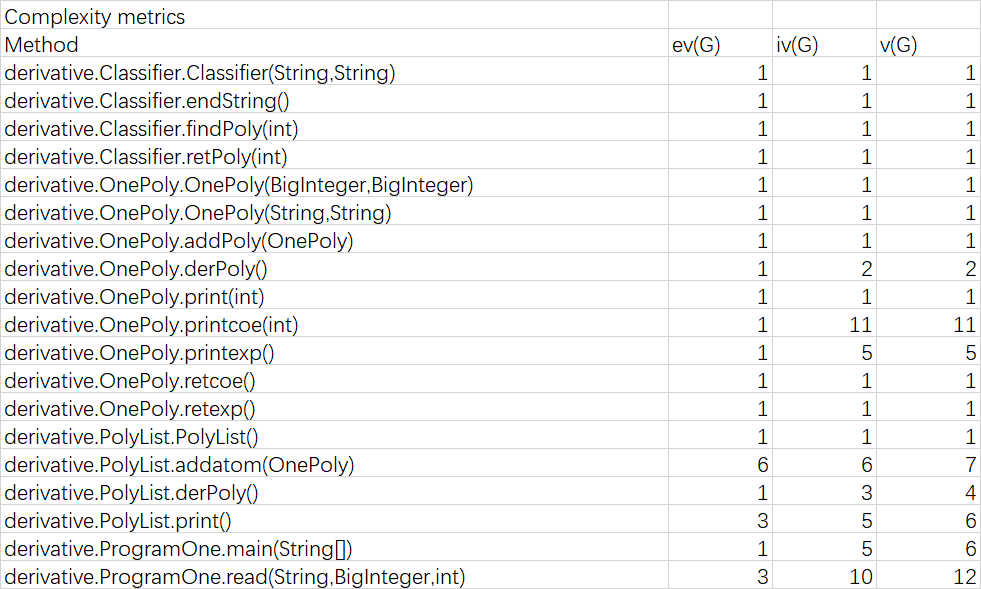
表一 第一次作业方法复杂度
可以看出PolyList的addatom方法由于在插入一个单项时需要按指数降序排列,因此需要使用查找算法,所以其基本复杂度ev(G)和循环复杂度v(G)都比较高。而OnePoly中的printcoe方法以及ProgramOne中的read方法由于在输出和读入时需要判断多种情况,并且在做输入输出处理时需要调用大量其他方法,所以v(G)和iv(G)明显高于其他方法。
(2)对类的规模进行分析

图一 类的规格分析
可以看出本次作业类的长度基本控制在了150行以内,长度较短,调试和测试都比较方便。
(3)画出类图
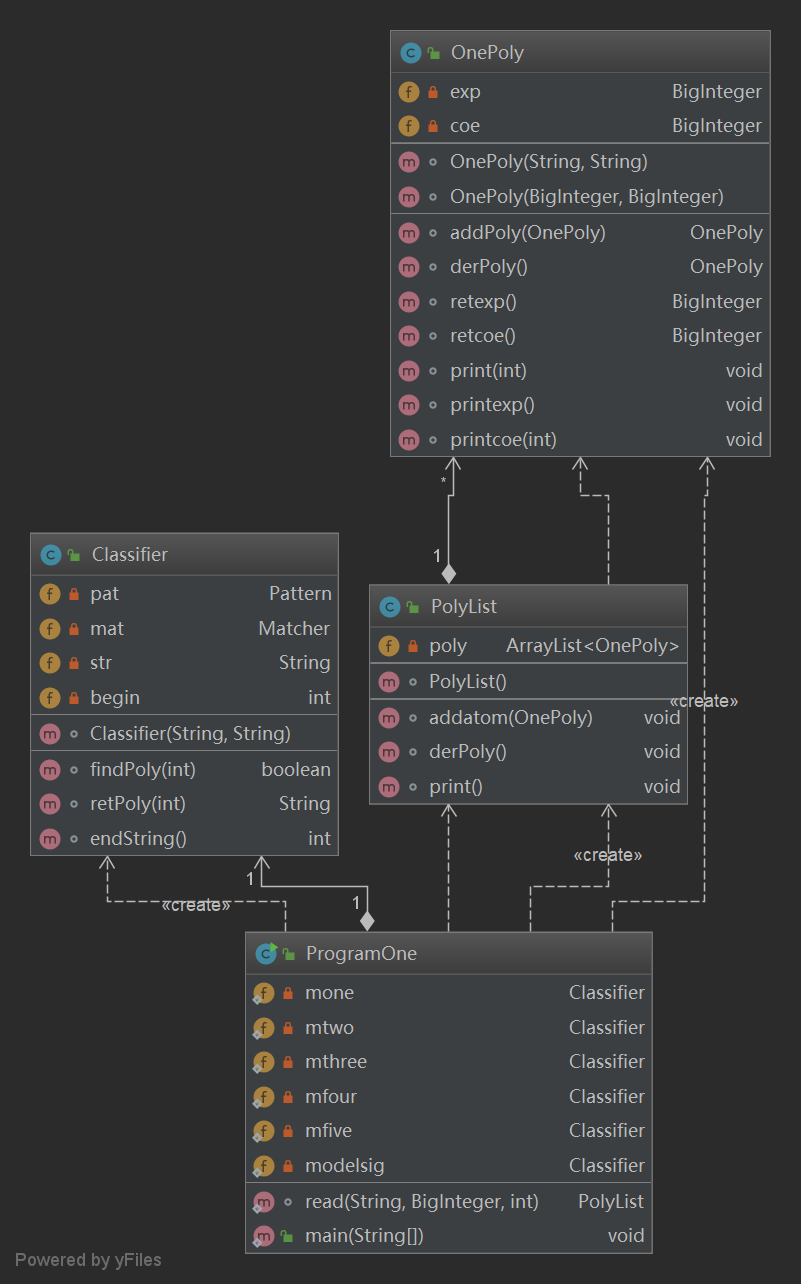
图二 第一次作业类图
可以看出本次作业总体来说类的耦合程度比较小,因为本次作业比较简单也不会涉及到类的复用问题,但是存在的一个问题就是把读入部分放在了主类里,降低了可读性和可维护性,比如说如果此题改成从文件读入,则需要更改主类。
2、第二次作业
(1)类方法的复杂度分析
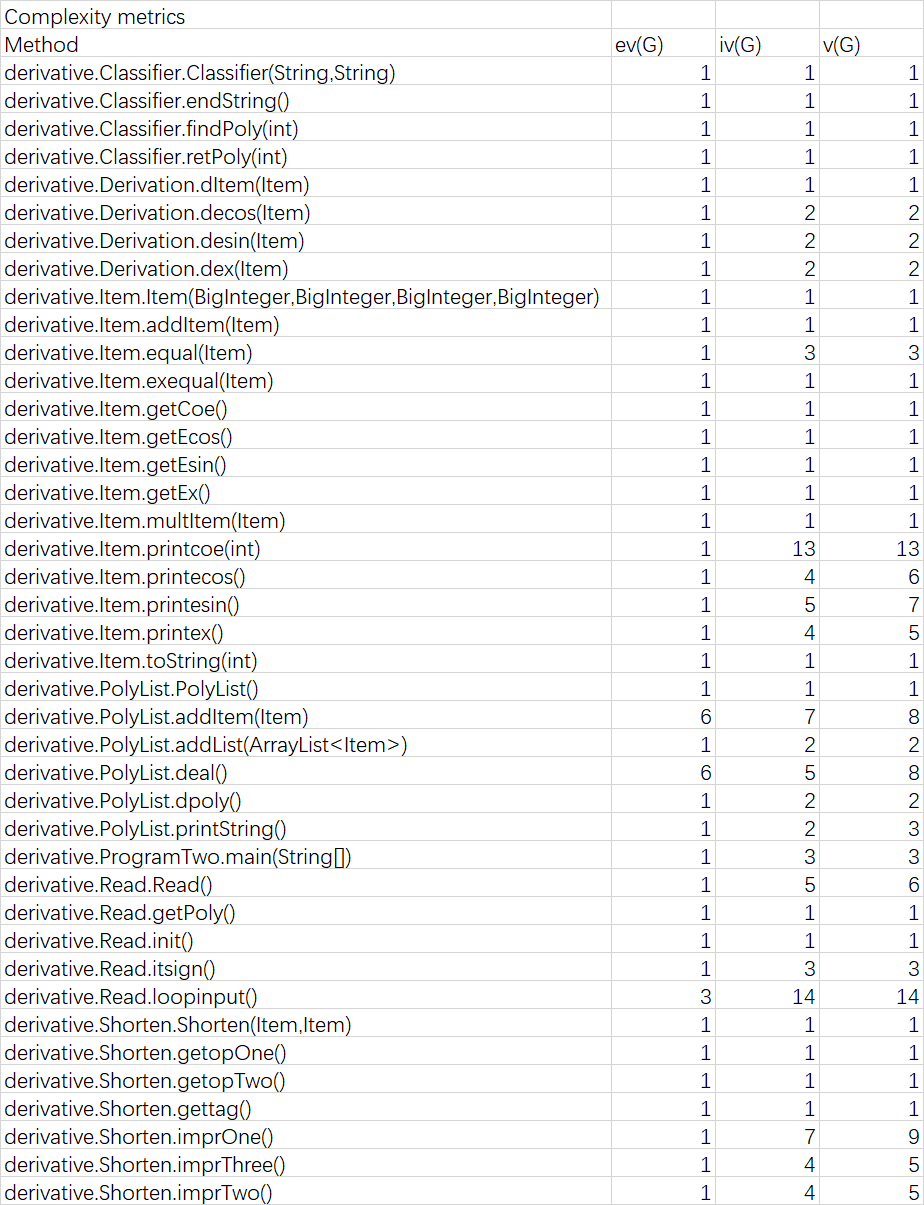
表二 第二次作业类方法复杂度分析
其中大部分复杂度高的原因与第一次作业相同,这里不再赘述,需要注意的是本次作业的优化比较复杂,而优化部分是个反复迭代检查的过程,所以PolyList中Deal方法的非结构化程度和循环复杂度较高。
(2)类的规模

图三 第二次作业类的规格
可以看出由于加入了三角函数,本次作业中的Item类相比第一次作业的OnePoly长度增加了百分之五十左右,并且将求导与Item类分开单独成一个类,有利于代码的测试与维护,整体来说类的最大长度相比第一次作业增长不大,代码仍具有比较好的可读性和可维护性。
(3)画出类图
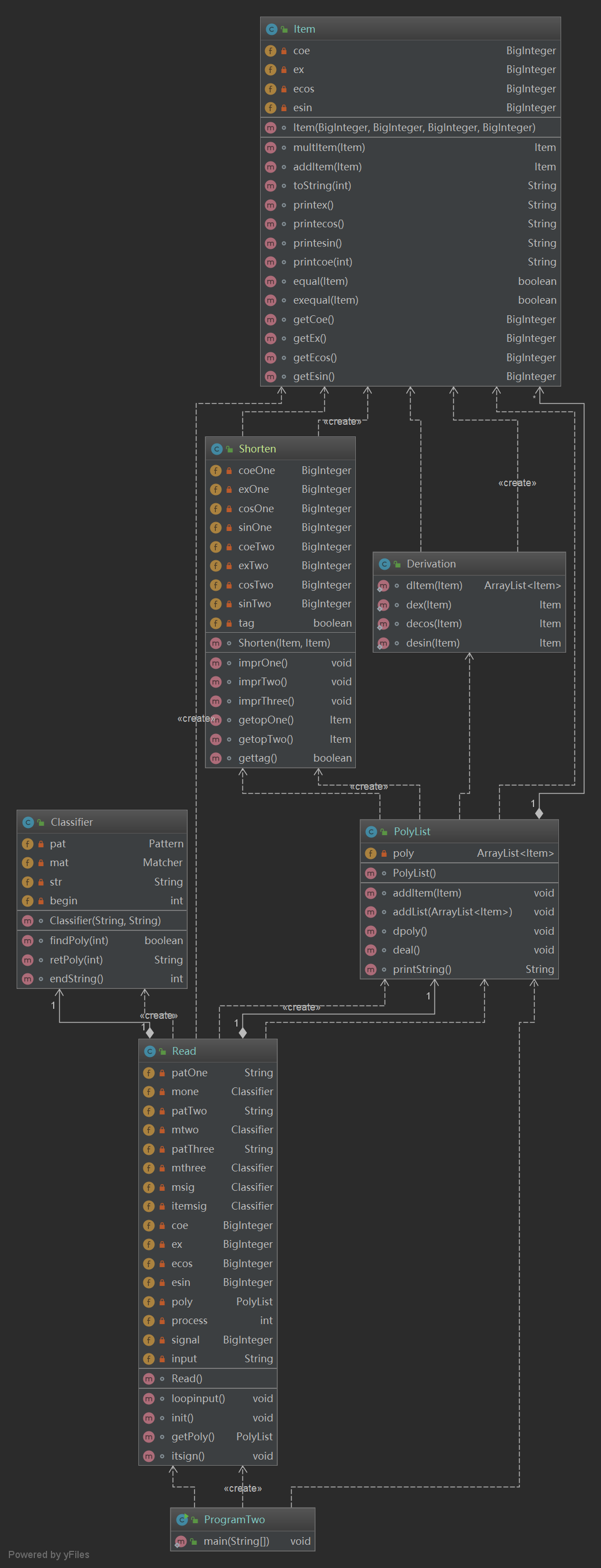
图四 第二次作业类图
通过类图可以看出本次作业的大体架构,相比于第一作业,最大的一个改进就是把Read从主类中独立了出来,主类通过Read类处理读入建立多项式类PolyList,多项式类中使用ArrayList储存数据,并且数组的每一个元素是Item的引用,PolyList通过调用Derivation类进行求导,Shorten类进行优化处理,最后通过printString()方法输出结果。
3、第三次作业
(1)类方法复杂度分析
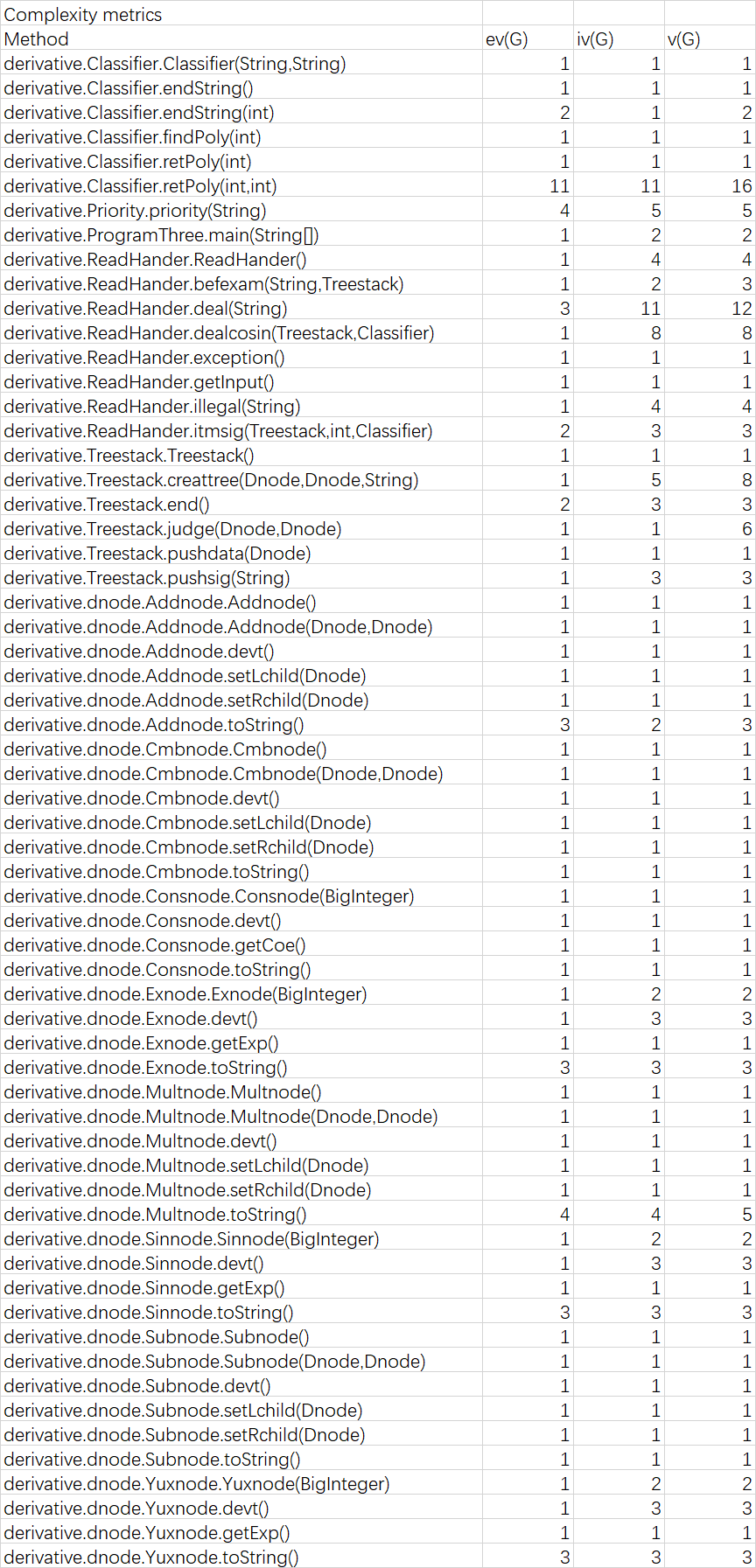
表三 第三次作业类方法复杂度分析
本次作业的架构相对前两次改动较大,因为本次作业会有多层括号嵌套问题,所以在Classifier类的retPoly方法中由于涉及到括号处理,需要多种情况的分支和循环,所以复杂度很高,除此之外就是每个节点都有的toString方法,由于需要多层判断,所以复杂度相对比较高。
(2)类规格
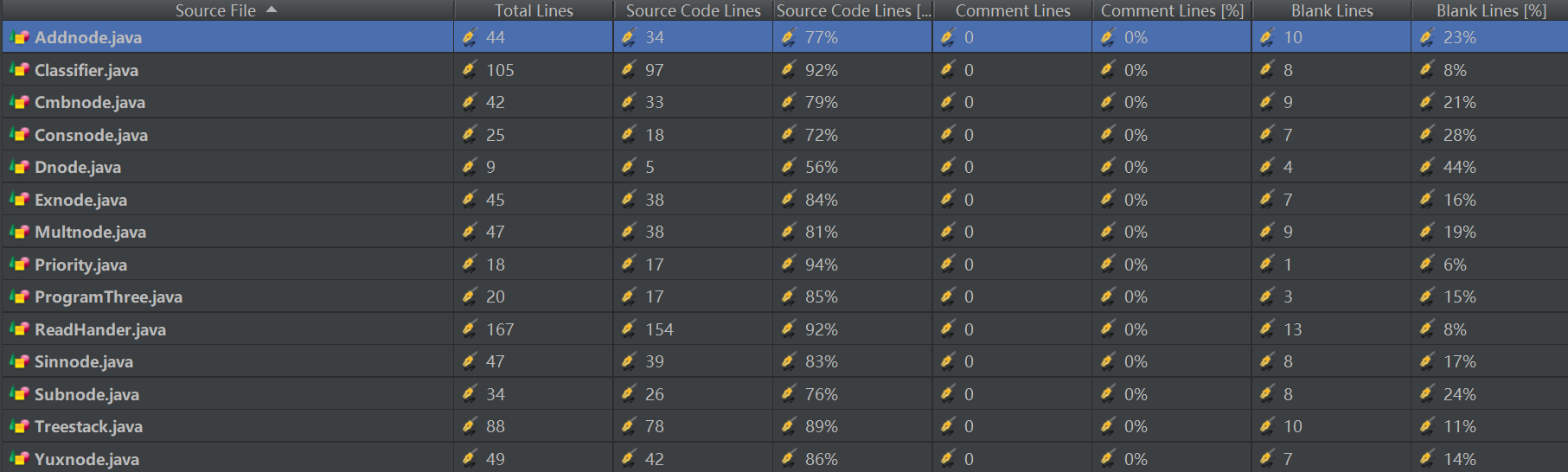
图五 第三次作业类规格
通过规格分析可以看出,由于本次使用了二叉树结构,节点采用了接口的继承,没有了前两次作业中“项”的概念,因此类的长度普遍比较短,而因为此次表达式复杂程度进一步增加,又有了括号的嵌套,所以Reader和Classifier方法的长度有所增加,但都保持在了200行以内,总体来说还是有着比较良好的可读性和可维护性的。
(3)类图
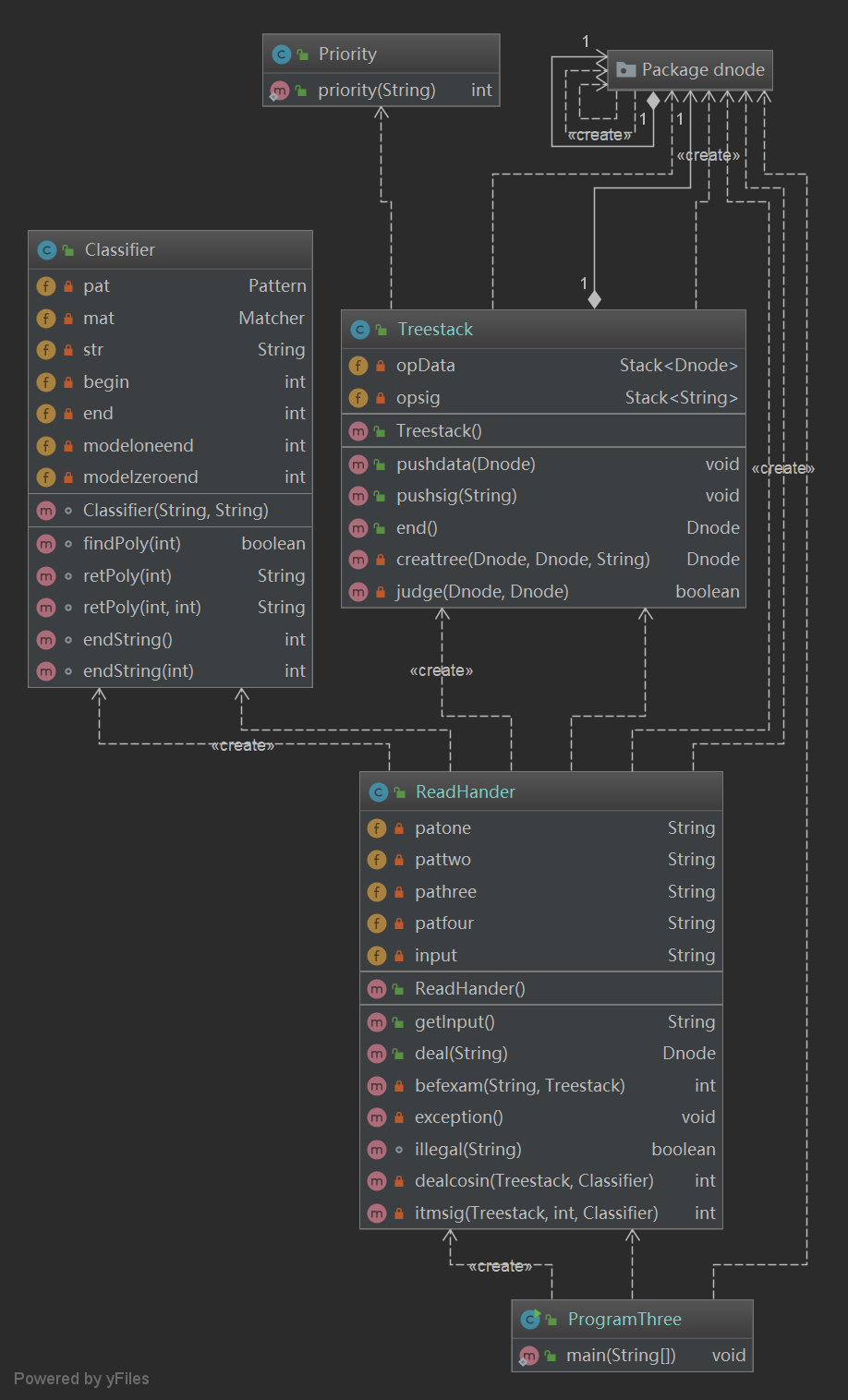
图六 第三次作业类图(1)
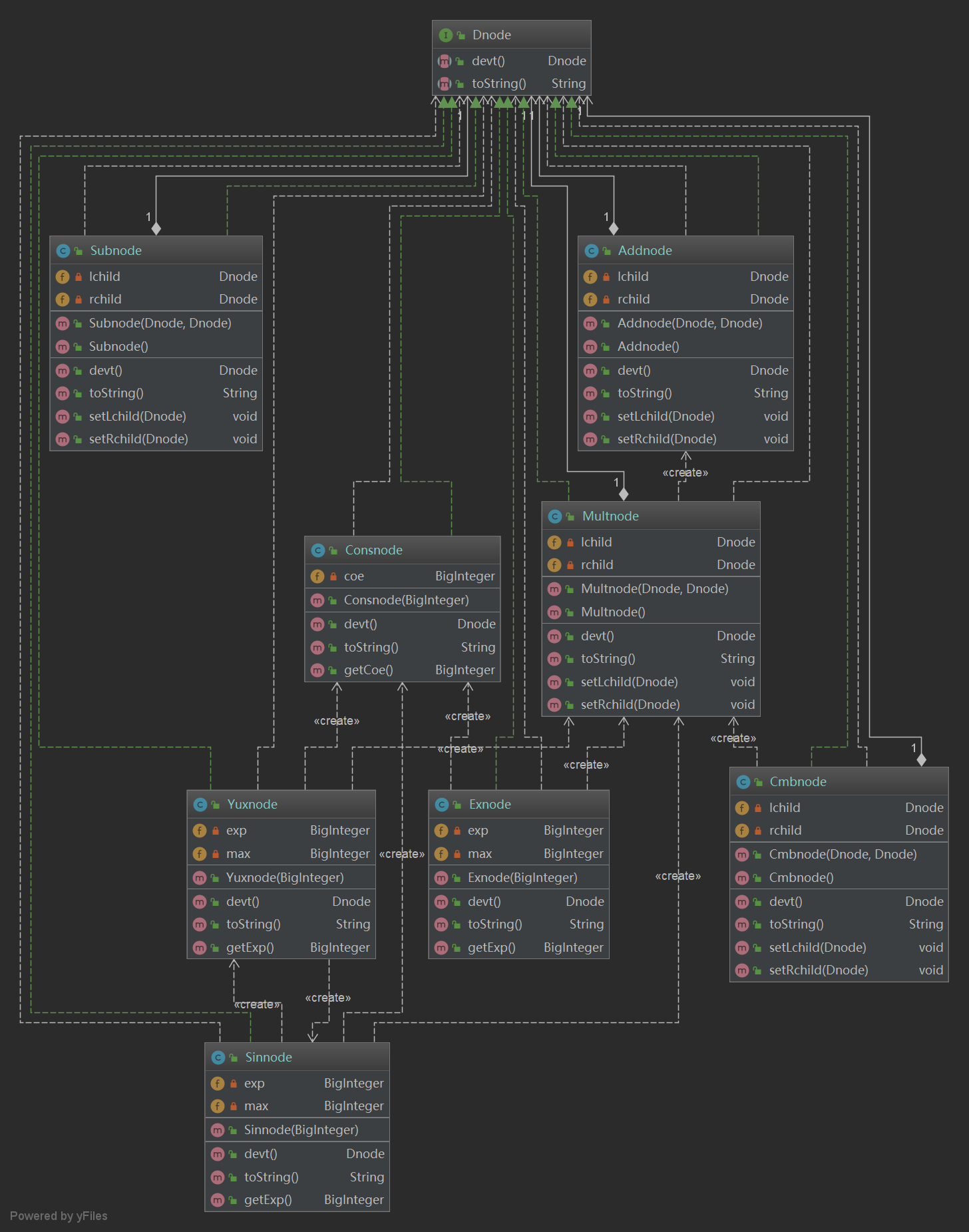
图七 第三次作业类图(2)
本次作业的类图分为两层,外层类图将所有的节点看为一个整体,而内层类图则展示了dnode包内部各节点类之间的关系。在dnode 内部定义一个接口,之后所有的节点类都从这个接口继承。所有的节点共有的方法为求导devt和toString。而在外部,主类首先调用 Read类,而Read类通过调用Classifier和TreeStack解析输入的字符串,建立表达式树返回根节点。之后主类递归调用根节点的求导方法便可递归地进行求导。最后同样递归调用根节点的toString方法将结果输出。
二、个人bug分析
本单元的作业中我出现了两个明显的bug。
1、在第一作业中我的程序在某些时候会输出"+0"字符串,导致性能降低。
原因:在PolyList类的addPoly方法中填入项时,在原有多项式有指数相同项时我会合并同类项并检查合并后系数是否为零,但如果没有同类项我并没有判断插入项系数是否为零就将其插入到多项式中,所以有时会出现"+0"这种现象。
分析:我认为出现这种bug的原因是在前期设计中逻辑上有问题,因为对于系数是否为0的判断与原多项式是否有同类项无关,所以在判断系数是否为零的程序不应该与是否有同类项的判断语句相耦合。
2、在第三次作业中我的程序当一个乘积项同类因子幂之积超过10000时也会报错
原因:在读入解析时一个乘积项同类因子我会进行合并,而在判断是否指数超过10000的判断被我放在了节点中,因此在合并同类项之后再建立节点就会报错。
分析:设计时判断的顺序出现了错误。
三、发现别人程序bug所采用的策略
本次在给别人发现bug的时候主要采用随机生成测试用例的策略
发现bug主要是两个方面,一个是正确性,即输入合法用例是否会计算出正确的结果,并且结果格式是否正确;另一个是输入格式错误用例是否会输出"WRONG FORMAT!"。
(1)在生成合法测试用例时利用的是python 的xeger包,即可以根据正则表达式随机生成字符串。而正则表达式这可以参考我们在写作业时读入时设计的正则表达式并进行一定的修改。以第二次作业我的随机生成样例的程序为例
1 from xeger import Xeger
2 import os
3 x = Xeger(limit = 1000)
4 coe = '( ?[+-]?d{1,2})'
5 cos = '( ?cos ?( ?x ?)( ?^ [+-]?d{1,2})?)'
6 ex = '( ?x(^ [+-]?d{1,2})?)'
7 sin = '( ?sin ?( ?x ?)(^ [+-]?d{1,2})?)'
8 tem = '('+coe+'|'+ex+'|'+cos+'|'+sin+')'
9 item = '( ?[+-]?('+tem+'*){4,5}'+tem+')'
10 poly = '[+-]?('+item+'[+-]){6,9}'+item
11 print(x.xeger(poly))
在判断输出结果时又分为两个方面,一方面要检验计算的正确性,一方面要考虑格式的正确性(因为一些可以在matlab等数学计算软件跑的公式格式并不符合要求)。在正确性方面我采用了matlab脚本,在[-10,10]区间上随机选6个点(0除外),利用指导书上给出的测试公式计算出结果(可利用vpa进行高精度计算)。而在格式正确性方向方面,由于我们本单元的输出要求和输入一致,我直接将别人的输出导入我的Read类中,如果没有输出"WRONG FORMAT!"则说明输出结果格式正确。
(2)生成非法测试用例时我的方法是将所有的可能出现的字符随机组合,生成长度比较短的字符串(如果长度较长,则可能会有很多种格式错误,难以发现bug),将生成的结果与我的程序输出相对比。仍以第二次作业为例
1 from xeger import Xeger
2 poly_wf = "((((s ?i ?n|c ?o ?s)(x))|x|[+-*^012 ])|[+-*^]){2,4}"
3 x = Xeger(limit = 100)
4 print(x.xeger(poly_wf))
四、Applying Creational Pattern
本单元的第三次作业中特别适合使用工厂模式来实例化节点对象。即利用一个工厂类来统一管理节点对象的实例化,会使得程序更加清晰,隐藏性更好,扩展性更强。我的重构想法如下,这里给出工厂类的实现。
1 package derivative;
2
3 import derivative.dnode.*;
4
5 import java.math.BigInteger;
6
7 public class FactoryNode {
8 public Dnode getnode(BigInteger exp, String pattern) {
9 if (pattern.equals("x")) {
10 return new Exnode(exp);
11 } else if (pattern.equals("cons")) {
12 return new Consnode(exp);
13 } else if (pattern.equals("sin")) {
14 return new Sinnode(exp);
15 } else if (pattern.equals("cos")) {
16 return new Yuxnode(exp);
17 } else {
18 return null;
19 }
20 }
21
22 public Dnode getnode(Dnode op1, Dnode op2, String pattern) {
23 if (pattern.equals("+")) {
24 return new Addnode(op1,op2);
25 } else if (pattern.equals("-")) {
26 return new Subnode(op1,op2);
27 } else if (pattern.equals("comb")) {
28 return new Cmbnode(op1,op2);
29 } else if (pattern.equals("*")) {
30 return new Multnode(op1,op2);
31 } else {
32 return null;
33 }
34 }
35
36 }
这样在需要实例化对象的时候只需要通过工厂类,传给工厂制定的标识符就可以得到相应的对象了。