今天是林永迪老师的讲授~
基础算法
1. 模拟算法
面向测试算法
模拟算法的关键就是将人类语言翻译成机器语言。
要做到以下两点:
1.优秀的读题能力;
2.优秀的代码能力;

程序流程图:
读入,循环处理指令,输出;
读题是很重要的,我们要考虑到用什么样的方法,怎么写;

主要就是要看懂四条规则然后往里面填数就好了,好像很简单,那就看这个题:
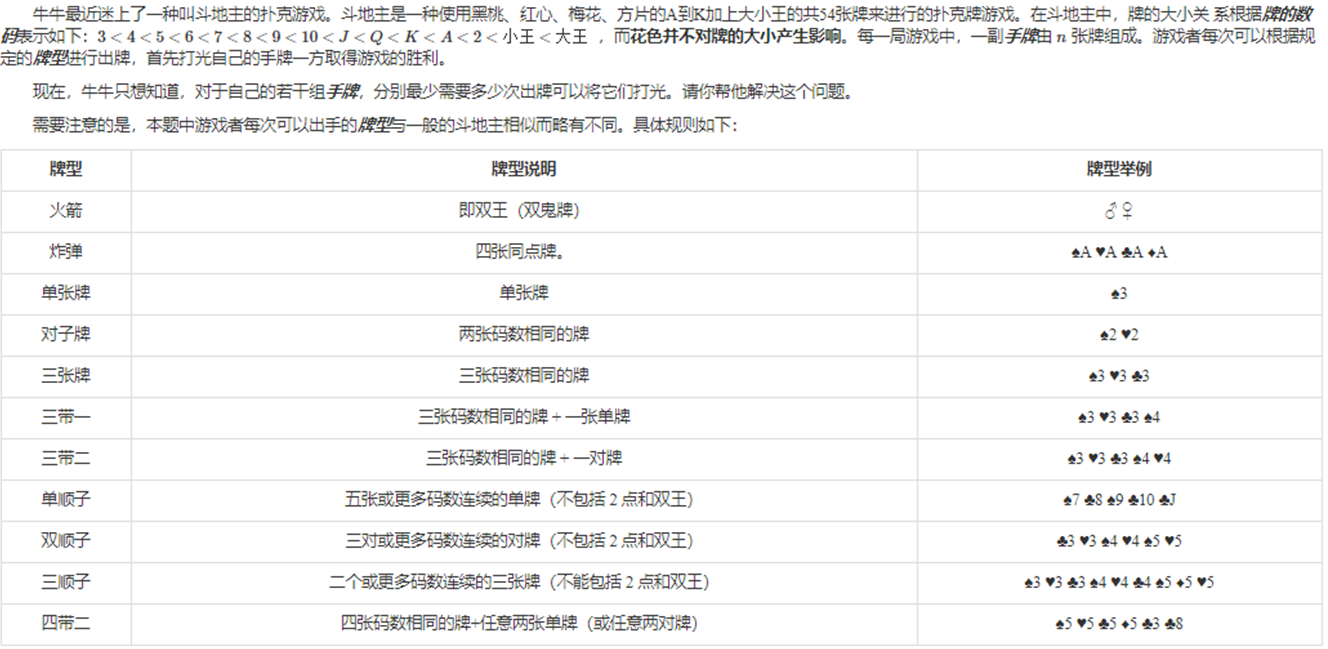
我们要先抓住核心部分:
手里有n张牌,有k(k<?)个规则,每个规则可以打出一定的牌,请问要打出最小多少次牌;
一个明显的深搜:
void dfs(剩下多少张牌没打last,打了多少次牌ans) { if(last==0) //牌打完了 回溯 if(k条规则) …… }
模拟题更强调的就是选手的代码能力,其特点是:题目特烦,细节超多,代码极长;
考验的全部都是选手写代码的基本功:
1.写长代码都不出错的能力;
2.多方面全地考虑问题;
前者要求我们有一个良好的代码习惯,而后者则要求我们在做题时头脑有清晰的逻辑;
注意标准形式缩进;
一个笑话:

所以写长代码的要领在于一遍就写对!
Solution:
模块化结构(如何去思考一个问题?);
没想清楚时不动笔,画程序逻辑图;
写完一部分就检查一部分;最好一次AC;
在赛场上检验自己的程序是否正确的方式有两种:
1.造数据;
2.对拍;
对拍其实就是模拟算法的一种应用;
因为暴力算法的本质就是模拟(大雾)
2.贪心算法
贪心算法的数学原理:局部最优得到全局最优。
在每一个状态下,都选择当前的最优解而不考虑全局的影响;
爬山算法能较好地体现贪心的思想;
如何求解一个函数的最值?
贪心算法要满足两个条件:
1. 决策没有后效性;
2. 不会陷入局部最优解;
一般数据很大的题目,一般考虑用贪心,因为贪心的复杂度挺低的;
一般贪心算法会让你求最优解
做法:先找规律,看能否找到贪心的规律,然后找反例去验证;
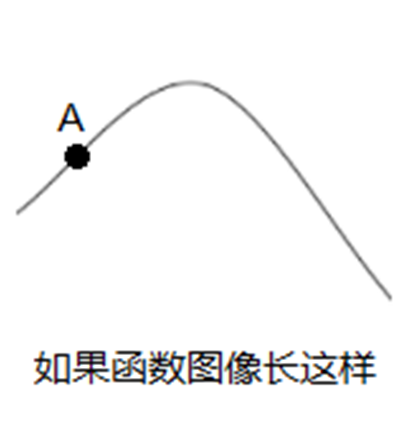
标准做法:要么往下走,要么往上走,当我们走到顶峰的时候发现无论再往哪走都不是最优解了;
但如果函数长这个样子的话,那么就会陷入局部最优解了:
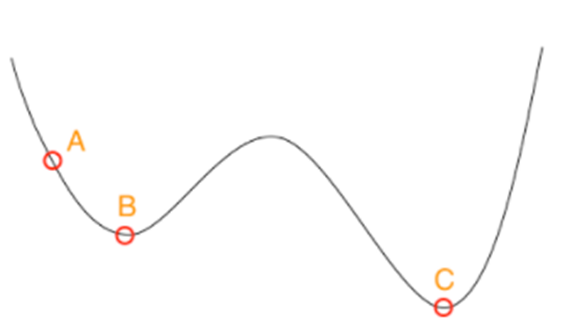
根据贪心的数学背景我们在做贪心题目的时候一般有两种策略:
1.把一个问题划分成很多子问题,对于每个子问题直接求最优解,然后合成一个最优解;
2.对于当前局面,搜索所有的可能的“临近局面”,选择最优的局面进行转移;
例如部分背包问题,我们按照每个物品的性价比往里面放直至塞满;
贪心在OI中更像是一种思路而不是一个确切的算法;
贪心一般用于求最优化问题,但是最优化问题还有很多算法——动态规划与搜索;
没有很好的方法去一下子区分一个最优解究竟是搜索+剪枝,还是动态规划还是贪心;
这个时候就很依赖经验的积累以及对题目性质的把握(触类旁通)
贪心最最重要的地方就是找反例,一般做题的过程中就在思考规律 -> 寻找反例 -> 找到算法或者重新思考的循环中度过;
平时遇到的贪心策略题都要仔细地咀嚼并记忆,这是你以后做其他题的根基;
贪心的经典问题:
例一:

考虑按照巧克力的价钱从小到大排序,然后在不多买巧克力的前提下能买就买;
这就意味着我们在买第 i 块巧克力的时候,前面比它更便宜的巧克力已经买完了;
证明的话很简单:假如你可以花 ai 元钱使第 i 头奶牛开心,同样你也可以花 aj 元钱使第 j 头奶牛开心,既然都是使1头牛开心了,你当然是花的钱越少越好,这样省下钱来买其他的巧克力能使更多的奶牛开心;
例二:

我们先不考虑取模的情况,我们枚举 S1~Sn,对于每个Si 我们去找在它前面最小的那个数,做差求最大值就好了;
现在考虑取模的情况,那么不再单单地找Si 前面最小的那个数了,而是找最接近Si 的数;
因为我们要考虑的是 Si - Sj 和 Si - Sj + Mod(如果Si < Sj 的话) 最大的那个;
我们可以偷懒用 set,先二分查找到第一个大于Si 的元素,然后找到最接近的数就好了;
例三:

先画出一个时间轴,将每个活动看作是一个个线段,要保证每个线段不能有重复的部分,问最多放几个线段;
考虑按照结束时间从小到大排序,然后我们从后往前枚举时间 i,枚举所有右端点小于等于 i 的线段,取其中左端点最大的;
均摊一下后,时间复杂度应该是O(n);
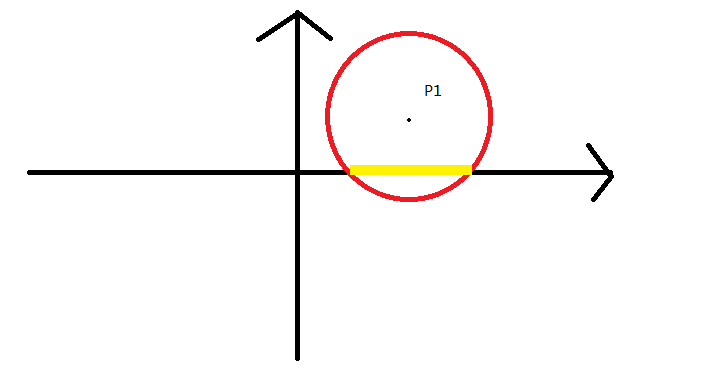
例四(喷水装置):
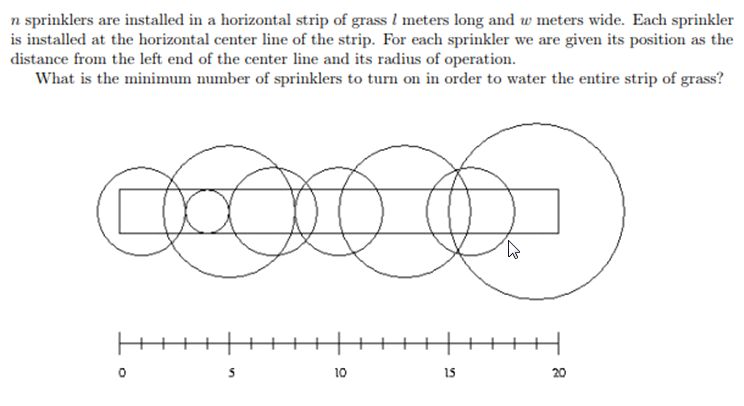
我们发现这个圆实际有用的就是与矩形相交的四个点所形成的矩形(下图中红色部分):

那么这个题就转化成了简单的线段覆盖问题;
我们固定右端点 i,然后找所有右端点大于等于 i 的区间(要覆盖 i 点),取其中左端点最小的,然后 i =这个左端点,继续上步操作直至覆盖整个区间。
例五:
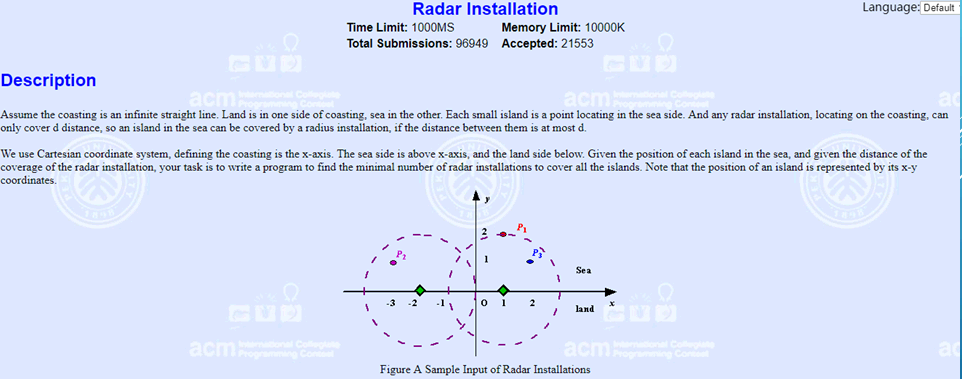
首先考虑到“在x轴上画圆看能覆盖哪几个岛屿”这个想法是不现实的,我们要转化成线段覆盖之类的问题:
我们可以以每个岛屿为圆心画圆,这样的话会交x轴于两点,那么说明在这两点间的任意一点画圆都会覆盖这个岛屿;每个岛屿画一个圆就对应了一段线段,那么问题就转化成选尽量少的点使所有的线段内都有点包含;
这其实就是简单的区间选点的问题,先按照每个区间的右端点从小到大排序,对于每个区间,如果区间范围内有点那就跳到下一个区间里,否则就在区间最后的一个位置上放上点(贪心策略,这样能使这个点尽可能的多利用)。
例六:

lyd:这不是sb题吗?
我们可以将所有的怪分成两类:
1.回血比打怪掉的血多的怪;
2.回血比打怪掉的血少的怪;
我们显然是先打第一种怪吧,打的时候要注意我们要在打怪吃血药前保证生命值>0,也就是说我们要保证生命值要大于打怪掉的血,那么我们可以按照 d [ i ] 升序排序来打怪;
我们设打完第一种怪之后剩下的生命值是 rest,对于第二种情况,我们无论怎么安排打怪顺序,最后还剩下的血一定是固定的,记为 last, 那么我们可以倒着看:从一开始的 rest,先扣除打怪掉的血药,再补上打怪掉的血,保证中途的生命值 >0 的情况下,是否能到达 rest;
由于我们这样反过来看就又变成了第一种情况了(掉的血比会的血少),所以反过来我们按照血药 a [ i ] 降序排序依次打怪就好了。
#include<iostream> #include<cstdio> #include<cstring> #include<algorithm> using namespace std; int read() { char ch=getchar(); int a=0,x=1; while(ch<'0'||ch>'9') { if(ch=='-') x=-x; ch=getchar(); } while(ch>='0'&&ch<='9') { a=(a<<1)+(a<<3)+(ch-'0'); ch=getchar(); } return a*x; } long long n,z,x,y,totb,totc,sum; int ans[100001]; struct rqy { int id,d,h; }b[100001],c[100001]; bool cmp1(rqy x,rqy y) { return x.d<y.d; } bool cmp2(rqy x,rqy y) { return x.h>y.h; } int main() { n=read();z=read(); for(int i=1;i<=n;i++) { x=read(); y=read(); if(x<y) { b[++totb].d=x; b[totb].h=y; b[totb].id=i; } else { c[++totc].d=x; c[totc].h=y; c[totc].id=i; sum+=x-y; } } sort(b+1,b+1+totb,cmp1); for(int i=1;i<=totb;i++) { z-=b[i].d; if(z<=0) { printf("NIE "); return 0; } ans[i]=b[i].id; z+=b[i].h; } int last=z-sum; sort(c+1,c+1+totc,cmp2); for(int i=1;i<=totc;i++) { z-=c[i].d; if(z<=0) { printf("NIE "); return 0; } ans[i+totb]=c[i].id; z+=c[i].h; } if(z) { printf("TAK "); for(int i=1;i<=n;i++) printf("%d ",ans[i]); } else printf("NIE "); return 0; }
例七:

先预处理 k 以内的阶乘,然后从大到小枚举阶乘,n 能减就减,看看最后能否减到 0;
证明:
如果我们到了 k!< n,如果我们不减去 k!的话,我们后面∑ i!(1<= i <= k-1)都到不了 k!,那么肯定是分解不完的,所以我们要选上 k!。
这个方法类似我们在将十进制转化成二进制的过程;
例八:

如果可以的话一定要把最大的数提到最前面,然后发现剩下的数的顺序没变,那么我们就变成了部分序列求最大字典序,我们仍然按照上面的思路,尽量把最大的往前提,这样求出的字典序一定是最大的。
例九:
这个题是最小化最大值的问题,显然用二分。
我们先看怎么计算每个大臣获得的奖赏:1
Moneyi = L1 * L2 * L3 *…… * Li / Ri ,L 和 R 表示大臣左手上和右手上的数字;
所以看起来我们要求一个前缀积了,Si = L1 * L2 * L3 *……* Li-1 ,注意这里由于数据过大需要采用高精运算;
考虑到相邻的两个大臣交换位置并不会对前面和后面的大臣造成影响,只会对交换的这两位大臣的奖赏造成影响,所以我们来讨论一下怎么换更优:
假设我们原来的大臣是这样排列的:
设S=L1 * L2,
第三位大臣的奖赏:S / R3 ;
第四位大臣的奖赏:S * L3 / R4 ;
答案就是:max(S / R3,S * L3 / R4 ) ;
交换第三位和第四位大臣就是这样了:
第三位大臣的奖赏:S * L4 / R3 ;
第四位大臣的奖赏:S / R4 ;
答案就是:max(S / R4,S * L4 / R3) ;
比较一下哪个更优,PK大赛现在开始:
max(S / R,S * L3 / R4 ) PK max(S / R4,S * L4 / R3)
首先我们看蓝色部分是一定小于绿色部分的,所以我们就可以拆掉max了,于是就成了:
S * L3 / R4 PK S * L4 / R3
同时除以S: L3 / R4 PK L4 / R3
同时乘R3R4: L3 * R3 PK L4 * R4
也就是说,我们尽量让 Li * Ri 小的放前面;
那么对于整个序列,我们也按照这个规则走,那么不就是将 Li * Ri 从小到大排序即可?
那么这个题就做完了。
下午测试:
1.统计
(sum3.cpp)
(sum3.in/out)
时间限制:2s/空间限制:256MB
【题目描述】
小Z喜欢自己研究一些问题,今天老师上课讲了相反数,互为相反数的两个数的和为0,小 Z 现在在考虑三个数的情况,小 Z 现在命名三个互不相同且和为 0 的数为“相反数组”,两个相反数组相同当且仅当两个相反数组的三个数字都相同。
现在给定一组数字,求这组数中有多少个相反数组。
【输入格式】
本题读入为多组测试数据!
本题读入为多组测试数据!
本题读入为多组测试数据!
第一行为数据组数T
对于每组测试数据
第一行为数的个数 N
第二行为 N 个数,有正有负
【输出格式】
输对于每组测试数据,输出有多少个不同的相反数组
【输入输出样例1】
|
sum3.in |
sum3.out |
|
1 4 1 1 2 -3 |
1 |
【输入输出样例2】
|
sum3.in |
sum3.out |
|
1 3 1 1 -2 |
0 |
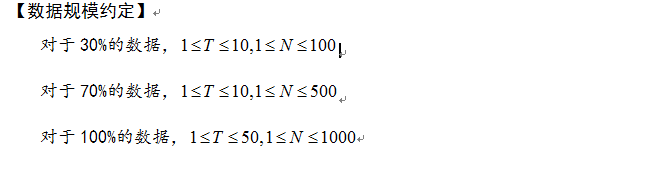
首先要在读入的时候去重,因为我们留几个相同的数字是没有意义的;
50pts:O(n3)
三层for循环暴力枚举,看看是否相加等于零就好了;
70pts:O(n2log n)
既然我们要保证 x+y+z==0,那么不就是看看有没有 x+y== -z 就行了?那么我们就把所有的数排个序,枚举a [ i ] 和 a [ j ] 计算 x = 0 - a [ i ] - a [ j ],然后在排完序的数组里找x,保证 a [ i ] < a [ j ] < x;
my 70pts 代码(用的是set去重+排序):
#include<cstdio> #include<iostream> #include<algorithm> #include<cmath> #include<set> using namespace std; int read() { char ch=getchar(); int a=0,x=1; while(ch<'0'||ch>'9') { if(ch=='-') x=-x; ch=getchar(); } while(ch>='0'&&ch<='9') { a=(a<<3)+(a<<1)+(ch-'0'); ch=getchar(); } return a*x; } int t,n,x,tot,ans; int a[10001]; set<int> st; int main() { //freopen("sum.in","r",stdin); //freopen("sum.out","w",stdout); t=read(); while(t--) { ans=0;tot=0; st.clear(); n=read(); for(int i=1;i<=n;i++) { x=read(); st.insert(x); } set<int>::iterator it; //定义前向迭代器 for(it=st.begin();it!=st.end();it++) { a[++tot]=*it; //cout<<a[tot]<<' '; } if(tot<3) { printf("0 "); continue; } for(int i=1;i<=tot;i++) //作为相反数组的第一个数 { if(a[i]>=0) break; for(int j=i+1;j<=tot;j++) //第二个数 { for(int k=j+1;k<=tot;k++) //第三个数 { if(a[k]<=0) continue; if(a[i]+a[j]+a[k]==0) { ans++; break; } } } } printf("%d ",ans); } return 0; }
100pts:O(n2)
我们再回顾一下70分代码在干什么,如果我们找到了 a [ i ] + a [ j ] + k ==0,那么接下来 a [ j ] 要增大,那么 a [ i ] + a [ j ] + k >0,所以这时候我们要 k 往前找;如果我们遇到 a [ i ] + a [ j ] + k < 0,那么我们要 k 往后找。时间复杂度最坏情况为O(n2);
lyd老师的神仙代码:
#include <cstdio> #include <algorithm> const int numsize = 131072; int T, N; int a[numsize]; inline int getint() { register int num = 0; register char ch = 0, last; do last = ch, ch = getchar(); while (ch < '0' || ch > '9'); do num = num * 10 + ch - '0', ch = getchar(); while (ch >= '0' && ch <= '9'); if (last == '-') num = -num; return num; } int main() { //freopen("sum.in", "r", stdin); //freopen("sum.out", "w", stdout); T = getint(); for (int i = 0; i < T; i++) { N = getint(); for (int i = 1; i <= N; i++) a[i] = getint(); std::sort(a + 1, a + N + 1); //从小到大排序 int cnt = 0; N = std::unique(a + 1, a + N + 1) - (a + 1); //STL里的去重函数 for (int i = 1; i < N; i++) { //枚举a[i] int left = i + 1, right = N; while (left < right) { if (a[i] + a[left] + a[right] == 0) { //满足相反数组 left++; //换个数往下找 cnt++; //答案个数 } if (a[i] + a[left] + a[right] > 0) right--; //大于0的话要往前找 if (a[i] + a[left] + a[right] < 0) left++; //小于0的话要往后找 } } printf("%d ", cnt); } return 0; }
lz大佬的70pts思路但实则100pts的代码:
#include<iostream> #include<algorithm> #include<cstdio> #include<cstring> #include<set> #define ll long long using namespace std; inline ll read(){ ll ans=0; char last=' ',ch=getchar(); while(ch>'9'||ch<'0') last=ch,ch=getchar(); while(ch<='9'&&ch>='0') ans=(ans<<1)+(ans<<3)+ch-'0',ch=getchar(); if(last=='-') ans=-ans; return ans; } bool cmp(int x,int y){return x<y;} ll n,ans; ll c[1010],fcnt,zcnt,cnt0; bool bj0; ll find(ll x){ //二分查找某个数是否在序列里 int l=0,r=n; int mid; while(l<=r){ mid=l+r>>1; if(c[mid]>x) r=mid-1; else l=mid+1; } if(c[r]!=x) return 0; return 1; } void solve(){ sort(c+1,c+n+1,cmp); ll sum; for(int i=1;i<=n;i++){ if(c[i]==c[i-1]) continue; //去重操作 for(int j=i+1;j<=n;j++){ if(c[i]==c[j]||c[j]==c[j-1]) continue; //还是去重操作 sum=c[i]+c[j]; if(-sum<=c[i]||-sum<=c[j]) continue; //严格保持递增 if(sum==0&&bj0==1){ //如果这两个数互为相反数且序列中有0,那么肯定能组成一组解 ans++; continue; } ans+=find(-sum); //找有没有-sum这个数,有的话就能组成一个相反数组 } } } int main(){ freopen("sum.in","r",stdin); freopen("sum.out","w",stdout); int T; scanf("%d",&T); for(int i=1;i<=T;i++){ n=read(); if(n<3){ printf("0 "); continue; } bool bjf=0,bjz=0; memset(c,0,sizeof(c)); cnt0=0;bj0=0;ans=0; for(int j=1;j<=n;j++){ ll _num=read(); if(_num<0) bjf=1,c[j]=_num; //序列中有负数 if(_num>0) bjz=1,c[j]=_num; //序列中有正数 if(_num==0) bj0=1,cnt0++; //序列中有0 } if(bjf==0||bjz==0) { //如果只有正数或只有负数那么一定是无解的 printf("0 "); continue; } solve(); printf("%lld ",ans); } return 0; }
做题的思路是连贯的,我们在没思路的时候可以先想想暴力怎么做 -> 然后 50 分怎么做 -> 然后70分怎么做 -> 最后100分怎么做;
2.二次函数数列
(sequence.cpp)
(sequence.in/out)
时间限制:2s/空间限制:256MB
【题目描述】
我们都知道二次函数的一般形式是,我们打算把二次函数引入到迭代数列的概念中来,得到一个二次函数数列。
那么先来解释一下迭代数列的概念吧:
迭代数列即通过一个函数 和数列的初值来得到数列的每一项:
如果这个数列是一个二次函数数列,那么就意味着函数是一个二次函数。
我们都知道是一次函数和常函数时的情况,现在由于一些不可告人的原因我们希望知道它是二次函数时候,数列的通项公式性质。
我们不会要求你算通项公式,但是我们希望你可以计算这个数列的第项来帮助我们的研究,当然数字会很大,我们只需要你返回后的结果。
【输入格式】
读入一共一行,6 个整数
从左到右,其中 n 和 p 一定是正整数
【输出格式】
输出一共一行,即答案,答案请不要出现负数。
【输入输出样例1】
|
sequence.in |
sequence.out |
|
-9 -100 -100 -100 1000 213213 |
199823 |
【输入输出样例2】
|
sequence.in |
sequence.out |
|
3076 12261 -13645 4116 2246809 953961 |
389812 |
【数据规模约定】
对于30%的数据,n不超过 10 ^ 7。
对于100%的数据,n 不超过 10 ^ 17,p 不超过 2 * 10 ^ 6。
第一个想到的就是暴力啦,直接O(n)暴力求出gn 即可,中间注意取模,期望得分30pts;
100pts:
我们看到 n 的范围是 1e17,这么大的数据说明正解肯定与n无瓜QwQ~
事实上真的是介个样子的,标算的时间复杂度是:O(p);
怎么来的呢?
在我们暴力求gn 的过程中,是要计算n次的,而中间要不断取模;我们都知道,对于一个数模 p 之后,那么只会出现 p 种情况 0,1,2……p-1 , p,我们看到 n 的范围是要大于 p 的范围的,那么我们求到 gp+1 的时候一定是在前面出现过的了(这是最坏情况),说明我们就找到了一个循环节,那么我们就不用在算下去了,直接利用循环节的性质O(1)算出 gn 就好啦,期望得分100pts。
#include <cstdio> #include <cstring> const int mod = 2097152; int F(long long x, int a, int b, int c, int p) { long long ans = 0; ans = a * x % p * x % p; ans = (ans + b * x % p) % p; ans = (ans + c) % p; return ans; } int g1, a, b, c, p; long long n; int f[mod]; int g[mod]; int main() { //freopen("sequence.in", "r", stdin); //freopen("sequence.out", "w", stdout); scanf("%d %d %d %d %lld %d", &g1, &a, &b, &c, &n, &p); g1 = (g1 % p + p) % p; a = (a % p + p) % p; b = (b % p + p) % p; c = (c % p + p) % p; memset(g, 0, sizeof(g)); f[1] = g1, g[g1] = 1; int point = 0; for (int i = 2; true; i++) { if (i > n) break; f[i] = F(f[i - 1], a, b, c, p); if (g[f[i]]) { point = i; break; } g[f[i]] = i; } if (!point) printf("%d ", f[n]); else { int m = g[f[point]] - 1, l = point - g[f[point]]; n -= m; n %= l; if (n == 0) n = l; printf("%d ", f[m+n]); } return 0; }
3.外星罗盘
(boardgame.cpp)
(boardgame.in/out)
时间限制:5s/空间限制:256M
【题目描述】
小H和小Z最近发现了一个神奇的外星罗盘,它的做工十分精美,背景是一副浩大的星空图。就像一个工艺品一般,外星罗盘的本身是一个的棋盘状,为了方便区分出每一个格子,小H和小Z就默认行是从上往下不断增大的,而列是从左到右不断增大的,也就是说你可以认为左上角是,右下角是。
同时罗盘的大部分格子都是光滑的,上面画着一颗行星,但是有些格子很特殊,他们的表面像是故意没有打磨过显得凹凸不平,上面模糊地画着一些小行星带。于是他们将光滑的格子用‘.’来表示,而凹凸不平的格子用‘#’来表示。
罗盘每隔一段时间会有两个光滑的格子突然亮起,一个亮起呈红色,一个呈绿色,然后过一段时间后亮起的格子会熄灭,然后另外两个格子亮起,这样一直反复循环。
小H和小Z觉得这个罗盘一定是在尝试发送什么信息,不过他们也没有思考出任何有效的信息,于是他们打算用这个罗盘玩一个游戏。
他们记录下来了次罗盘的亮灯行为,然后把绿色和红色格子的坐标记录了下来,他们打算研究是否每次绿色坐标都可以只通过往右走和往下走的方式移动到红色坐标,当然凹凸不平的格子是不可以经过的,你也不能神奇的走出棋盘外然后试图从一些神奇的角度绕回来。
【输入格式】(boardgame.in)
一共行。
第一行两个正整数为,表示棋盘迷宫的行列。
接下来行,每行一个长度为的字符串,由‘#’‘.’两种字符组成
接下来1行,一个正整数,表示询问的个数
接下来行,每行四个正整数x1,y1,x2,y2询问绿点(x1,y1)到红点(x2,y2)是否有一条合法的路径
数据保证(x1,y1)(x2,y2)所在的位置都是‘.’,同时x1<=x2,y1<=y2
【输出格式】(boardgame.out)
一共行,每行一个字符串或者,对应每一个询问的答案。
【输入输出样例】
|
boardgame.in |
boardgame.out |
4 4 .... ..#. .##. .... 3 2 2 4 4 2 1 4 4 1 2 4 4 |
No Yes Yes |
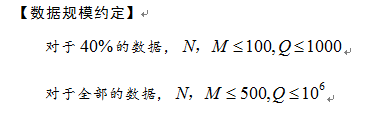
我们yong
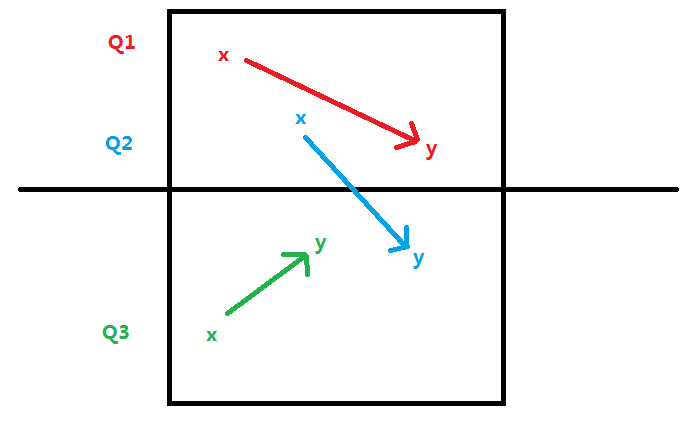
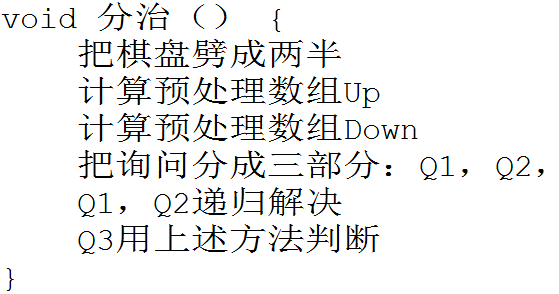
我们希望我们一次预处理能做出多种询问,那么我们用分治的方法做:
我们可以将这个矩阵从中间劈成两瓣,那么我们的询问就会分成三种:
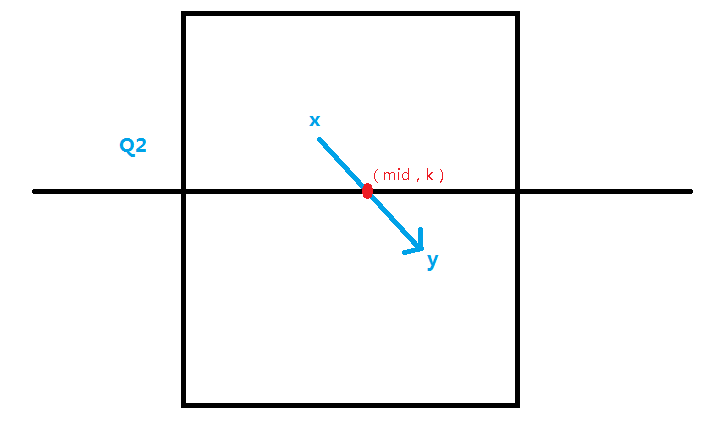
1.起点和终点都在上半方Q1;
2.起点和终点都在下半方Q3;
3.起点在上方,终点在下方或起点在下方,终点在上方Q2;
我们开两个数组 up [ i ][ j ][ k ] 表示从上半部分的点(i,j)能否走到点(mid,k),down [ i ][ j ][ k ] 表示从下半部分的点(i,j)能否走到点(mid,k);
对于前两种情况,我们直接在 up 或 down数组里面找就好了;
对于第三种情况,既然是从上半面某个点到下半面某个点的话,那么不管怎么走,一定是会经过分界线上的某个点,也就是说如果起点(x1,y1)到终点(x2,y2)一定会经过某个点(mid,k);换句话说我们如果(x1,y1)能够到达(x2,y2)的话,那么中间必然有一点(mid,k)满足 up [ x1 ][ y1 ][ k ] = 1 && down [ x2 ][ y2 ];
流程图:
怎么做这两个数组的预处理?
像过河卒一样,我们先看(i,j)往右走能不能走通,再看往下走能不能走通,只要有一个方向可以走通就行:

时间复杂度O((N3 / 64 + Q)* log n);
#include <cstdio> #include <vector> #include <bitset> using std::vector; using std::bitset; const int QUERY_SIZE = 600006; const int MAP_SIZE = 511; int N, M, Q; char map[MAP_SIZE][MAP_SIZE]; int ans[QUERY_SIZE]; bitset<MAP_SIZE> up[MAP_SIZE][MAP_SIZE], down[MAP_SIZE][MAP_SIZE]; struct query { int x1, y1, x2, y2, id; }; query q; void solve(vector<query> v, int l, int r) { int m = (l + r) >> 1; if (l > r) return ; for (int i = m; i >= l; i--) for (int j = M; j >= 1; j--) { up[i][j] = 0; if (map[i][j] == '.') { if (i == m) up[i][j].set(j); else up[i][j] |= up[i + 1][j]; if (j != M) up[i][j] |= up[i][j + 1]; } } for (int i = m; i <= r; i++) for (int j = 1; j <= M; j++) { down[i][j] = 0; if (map[i][j] == '.') { if (i == m) down[i][j].set(j); else down[i][j] |= down[i - 1][j]; if (j != 1) down[i][j] |= down[i][j - 1]; } } vector<query> vl, vr; for (vector<query>::iterator it = v.begin(); it != v.end(); it++) { q = *it; if (q.x2 < m) vl.push_back(q); else if (q.x1 > m) vr.push_back(q); else ans[q.id] = (up[q.x1][q.y1] & down[q.x2][q.y2]).any(); } solve(vl, l, m - 1); solve(vr, m + 1, r); } int main() { //freopen("boardgame.in", "r", stdin); //freopen("boardgame.out", "w", stdout); scanf("%d %d", &N, &M); for (int i = 1; i <= N; i++) scanf("%s", map[i] + 1); vector<query> v; scanf("%d", &Q); for (int i = 0; i < Q; i++) { scanf("%d %d %d %d", &q.x1, &q.y1, &q.x2, &q.y2); q.id = i; v.push_back(q); } solve(v, 1, N); for (int i = 0; i < Q; i++) puts(ans[i] ? "Yes" : "No"); return 0; }