直接上代码:
import jieba
import pandas as pd
import re
from collections import Counter
if __name__=='__main__':
filehandle = open("news.txt", "r",encoding='utf-8');
mystr = filehandle.read()
seg_list = jieba.cut(mystr) # 默认是精确模式
print(seg_list)
#all_words = cut_words.split()
#print(all_words)
stopwords = {}.fromkeys([line.rstrip() for line in open(r'stopwords.txt')])
c = Counter()
for x in seg_list:
if x not in stopwords:
if len(x) > 1 and x != '
':
c[x] += 1
print('
词频统计结果:')
for (k, v) in c.most_common(100): # 输出词频最高的前两个词
print("%s:%d" % (k, v))
#print(mystr)
filehandle.close();
# seg2 = jieba.cut("好好学学python,有用。", cut_all=False)
# print("精确模式(也是默认模式):", ' '.join(seg2))
运行截图:
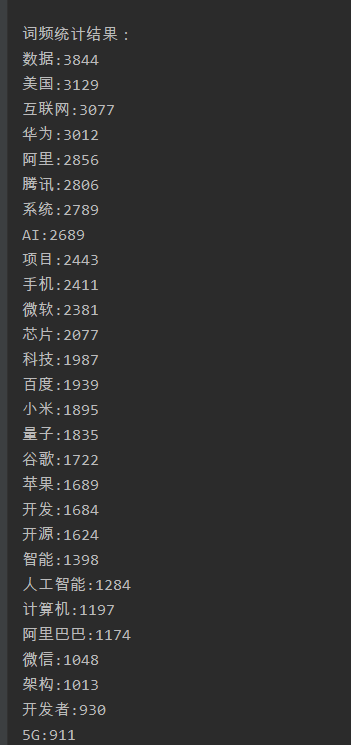
总结:第一步先爬取的大量数据,再根据爬取的数据进行分词,分词中去除多余的单词,用stop.txt。
然后就可以得到上述数据。
stop.txt部分截图: