scrapy框架结构
1. 项目结构
1.1 认识文件
这里我们简单认识一下, 在一个scrapy爬虫项目中各个文件都是用来做什么的, 知道了这些文件是干嘛的, 那么我们来写我们的项目就会很得心应手了.
这次我们还以上次百度的那个项目为例
spider1
|
|——spider1
| ├─spiders
| │ baidu.py # 爬虫文件
| │ __init__.py
| |
| │ items.py # 格式化文件
| │ middlewares.py # 中间件文件
| │ pipelines.py # 持久化文件
| │ settings.py # 详细的配置文件
|--scrapy.cfg # 默认使用的配置文件
2. scrapy结构
2.1 scrapy原理图
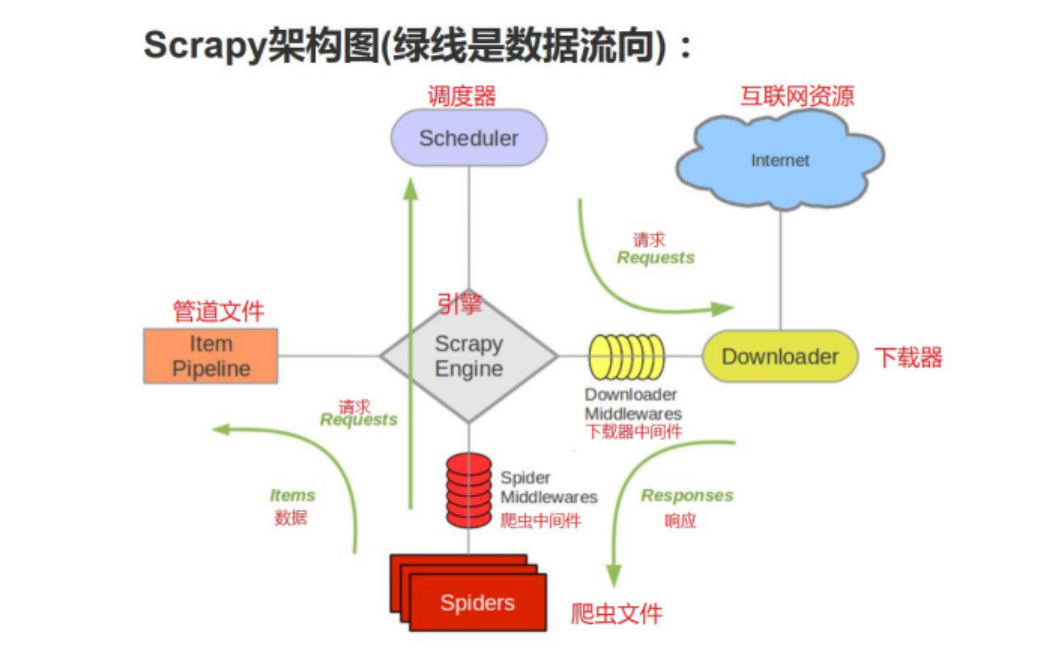
2.2 各个组件的介绍
- Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Item。项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
- Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
- Downloader。下载器,下载网页内容,并将网页内容返回给蜘蛛。
- Spiders。 蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提结果和新的请求。
- Item Pipeline。项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
- Spider Middlewares。 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
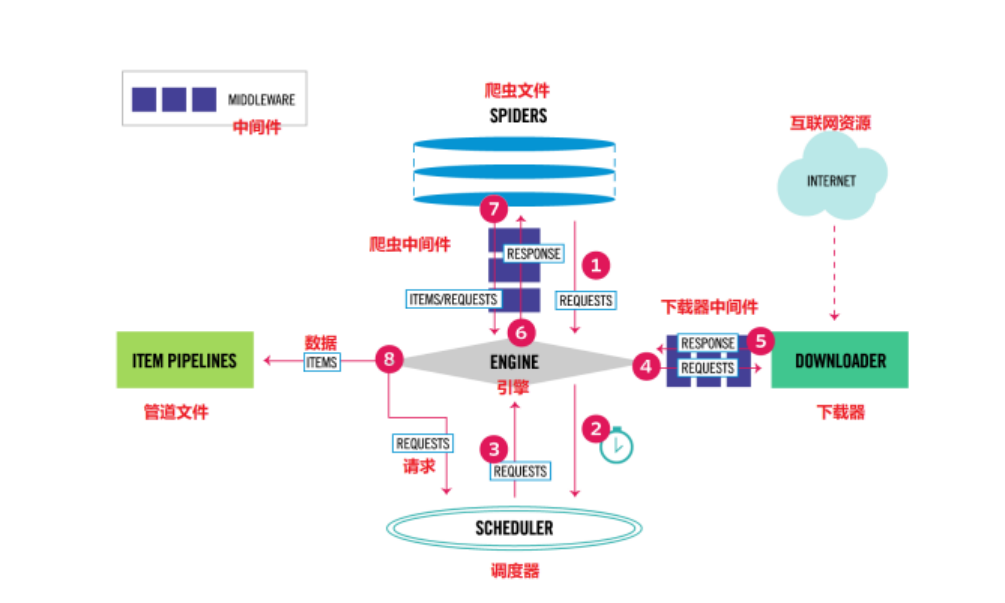
2.3 数据的流动
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
Spider(爬虫):负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
Item Pipeline(管道):负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(爬虫中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
3. 总结
简单对整个scrapy项目的大致内容进行了介绍
接下来我们会深入的对每个组件进行依次介绍