G1的特点
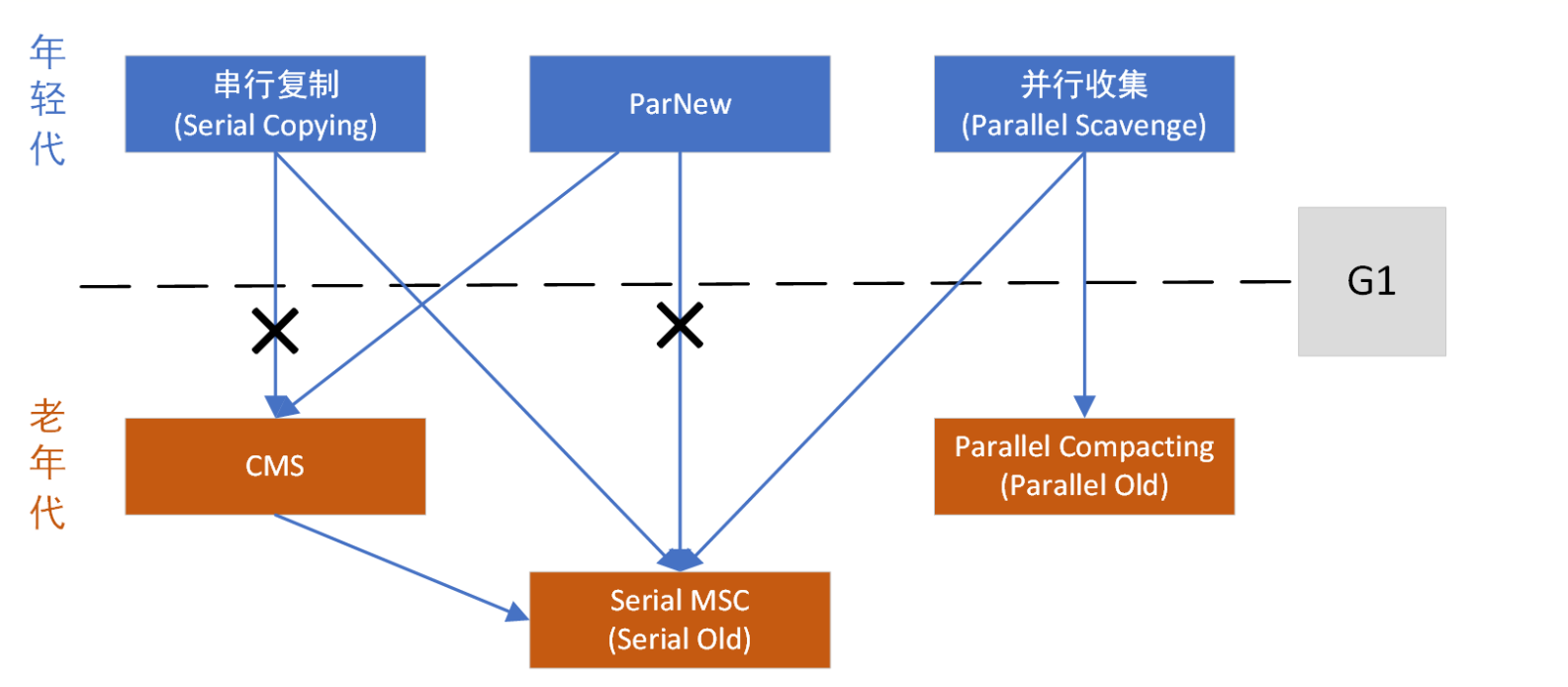
除了G1的其余垃圾回收器的特点是,年轻代和老年代是各自独立且连续的内存块,年轻代收集使用单edn+s0+s1进行复制算法,老年代收集必须扫描整个老年代区域。都是以尽可能少而快速地执行GC为设计原则。
G1是一款面向服务端应用的收集器,应用在多CPU和大容量内存的环境中,在实现高吞吐量的同时,尽可能减少GC回收的时间(STW的时间)它和CMS一样,可以和应用线程并发执行。并且具有以下特性:
- 整理空闲空间的速度更快
- 需要更多的时间来预测GC停顿时间
- 不希望牺牲大量的吞吐性能
- 不需要更大的Java堆内存
G1横跨老年代和年轻代,G1的垃圾回收日志记录上只有G1heap和元空间。G1的收集目的是取代CMS收集器,与CMS相比它有一个整理内存的过程,所以不会产生大量的内存碎片。而且G1的STW是可控的,G1在停顿时间上加了预测机制,用户可以指定期望的停顿时间。
CMS虽然减少了STW的时间,但是存在内存碎片的问题。G1很好的保留了CMS的STW时间短的优点,同时又去除了内存碎片的问题。JDK1.7u4发布后G1可以开始使用。Java9将G1作为默认垃圾回收器体改CMS。

G1的底层原理

G1算法将堆划分成若干区域,仍然属于分代收集器。区域一部分是老年代,一部分是新生代。新生代的垃圾回收器依然采用STW的方式,将存活的对象拷贝到幸存区或者老年代。G1收集器通过将对象从一个区域复制到另一个区域完成了清理工作,在正常的处理过程中,G1完成了堆的压缩,从而不会存在内存碎片的问题。
G1的回收步骤:
- 初始标记:只标记GC Roots能关联到的对象
- 并发标记:进行GC Roots Tracing的过程
- 最终标记:修正并发标记期间,因为程序运行导致标记变化的那部分对象。
- 筛选回收:根据时间来进行价值最大化的回收(尽可能减少内存碎片,获得连续的内存空间)


总结
G1可以重复利用多CPU、多核环境硬件优势来减少STW。整体上采用标记整理算法,局部采用复制算法,不会产生内存碎片。宏观上来看宏观上看,G1中不再区分年轻代和老年代,不再是物理隔离的,它把内存划分成多个独立的子区域。但是G1仍在逻辑上具有分代的概念,每个分区可能随G1的运行在不同代之间切换。G1虽然也是分代收集器,但是整个内存区不存在物理上的老年代和年轻代的区别,不需要完全独立的to区做复制准备。