一、爬取信息
分析网页:打开网易云课堂-----输入python搜索-----点击全部,得到下面网页
https://study.163.com/courses-search?keyword=python#/?ot=5
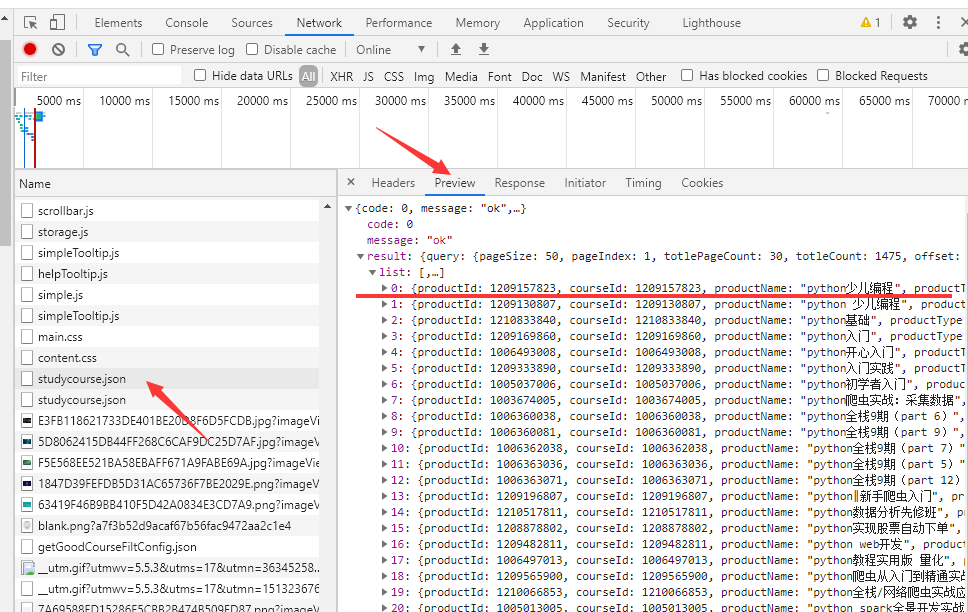

下面开始数据提取
import requests payload ={ "activityId": 0, "keyword": "python", "orderType": 5, "pageIndex": 1, "pageSize": 50, "priceType": -1, "qualityType": 0, "relativeOffset": 0, "searchTimeType": -1, } # 伪造头部信息 headers = { "accept":"application/json", "content-type":"application/json", "origin":"https://study.163.com", "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36" } response = requests.post(url=url,json=payload,headers=headers) content = response.json() if content and content["code"]==0: # 如果content存在,并且content的code属性的内容为0 content_list = content["result"]["list"] # 获取content的result的list print(content_list) lesson_1 = content_list[0] print(lesson_1) lesson_1_name =lesson_1["productName"] # 获取课程1的名字 print(lesson_1_name)
二、保存到Excel
import xlsxwriter workbook_XDD = xlsxwriter.Workbook("网易云课堂Python课程数据.xlsx") # 创建excel worksheet = workbook_XDD.add_worksheet("first_sheet") worksheet.write(0,0,'商品id') # 写在第1行第1列 worksheet.write(0,1,'课程id') # 写在第1行第2列 worksheet.write(0,2,'商品名称') # 写在第1行第2列 workbook_XDD.close()
