1. 创建虚拟环境
conda create –n py37-keras python=3.7
2. 激活虚拟环境
conda activate py37-keras
3. 安装ipykernel
使用conda install ipykernel 安装jupyter notebook 的插件,该插件能让我们在notebook里自主切换anaconda中的环境
4. 安装tensorflow-gpu
使用conda install tensorflow-gpu 可根据当前python版本,选择合适的tensorflow-gpub版本,并自动关联安装合适的cudatoolkit 和 cudnn ,而不需要去官网下载exe文件并配置环境变量等等,十分方便。
PS:这种方法得到的cuda是不完整的,例如使用
nvcc -V将无法显示当前cuda版本。
以下代码能测试tensorflow是否能够调用GPU。
import tensorflow as tf
print(tf.test.gpu_device_name())
print(tf.test.is_gpu_available())
若成功,得到的结果应是

5. 安装keras
使用conda install kears 自动安装对应版本keras
6. 安装完成,进行测试
jupyter notebook 打开 notebook,以一份CNN代码进行测试。
import numpy as np
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Dropout,Convolution2D,MaxPooling2D,Flatten
#二维卷积、二维最大池化、扁平化(二维->一维)
from keras.optimizers import Adam # 优化器
#载入数据集
(train_data,train_label),(test_data,test_label) = mnist.load_data()
#(60000, 28, 28)------->(60000, 784) 转化数据格式(扁平化)
train_data = train_data.reshape(-1,28,28,1)/255.0 #除以255是做归一化 1表示图像深度
test_data = test_data.reshape(-1,28,28,1)/255.0 #-1会自动进行匹配,也可以写60000
#将标签转化为one hot编码,
#one hot会将每一个标签用唯一的形式进行表示
train_label = np_utils.to_categorical(train_label,num_classes=10)
test_label = np_utils.to_categorical(test_label,num_classes=10)
#创建模型,输入784个神经元,输出10个神经元
model = Sequential()
# 第一个卷积层
# input_shape输入平面
# kernel——size 卷积窗口大小
# padding padding方法 same or valid
# activation 激活函数
model.add(Convolution2D(
input_shape = (28,28,1),
filters = 32, #32个特征图
kernel_size = 5, # 卷积窗口大小为5
strides = 1, # 步长为1
padding = 'same', # 用same padding ,得到的图片与输入的图片大小是一样的
activation = 'relu'
))
# 第一个池化层
model.add(MaxPooling2D(
pool_size = 2,
strides = 2, # 出来的特征图为14*14大小
padding = 'same',
))
#第二个卷积层 64个滤波器(卷积核),卷积窗口大小为5*5
#经过第二个卷积层后,有64个特征图,每个特征图为14*14
model.add(Convolution2D(64,5,strides = 1, padding='same',activation='relu'))
# 第二个池化层,经过第二个池化层以后,得到的图大小为7*7
model.add(MaxPooling2D(2,2,'same'))
# 把第二个池化层的输出扁平化为1维 64*7*7
model.add(Flatten())
# 第一个全连接层
model.add(Dense(1024,activation = 'relu'))
#Dropout
model.add(Dropout(0.5))
#第二个全连接层,由于是输出层,所以使用softmax做激活函数
model.add(Dense(10,activation='softmax'))
#定义优化器
adam = Adam(lr=0.001)
# 优化器,loss function,训练过程中的准确率
model.compile(optimizer = adam,
loss='categorical_crossentropy',
metrics=['accuracy']
)
#开始训练
model.fit(train_data,train_label,batch_size=32,epochs=10)
#评估模型
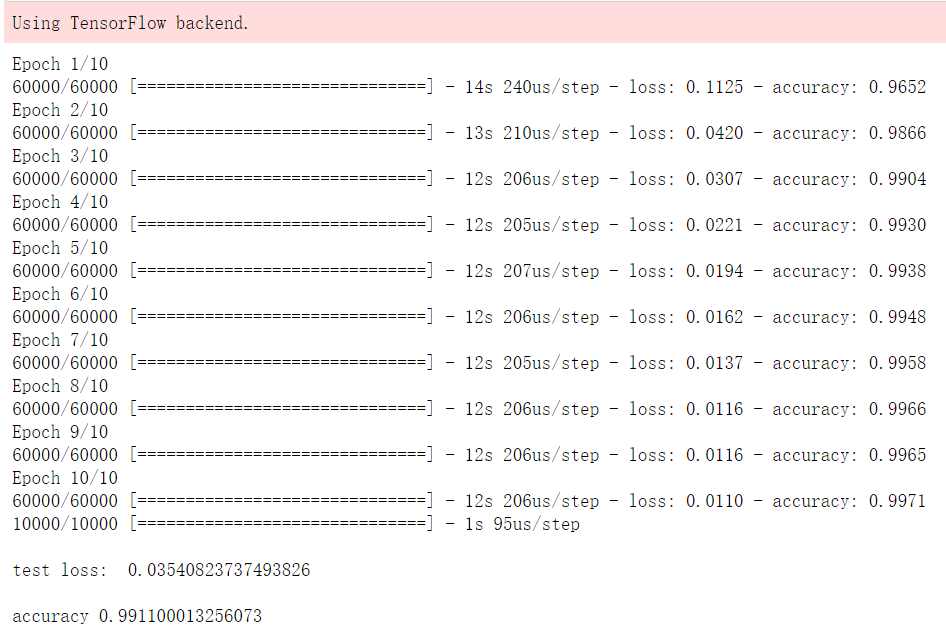
loss,accuracy = model.evaluate(test_data,test_label)
print('
test loss: ',loss)
print('
accuracy',accuracy)
运行结果如下: