目录结构
2.1.【场景实例一:获取前端请求后,对请求数据不做处理,都会统一返回一个特定的结果;】的完整操作流程
2.1.1.第一步:在项目【helloworld/hello/templates】里新增一个【qq_test.html】
2.1.2.第二步:在项目【helloworld/hello/views.py】里新增两个视图函数
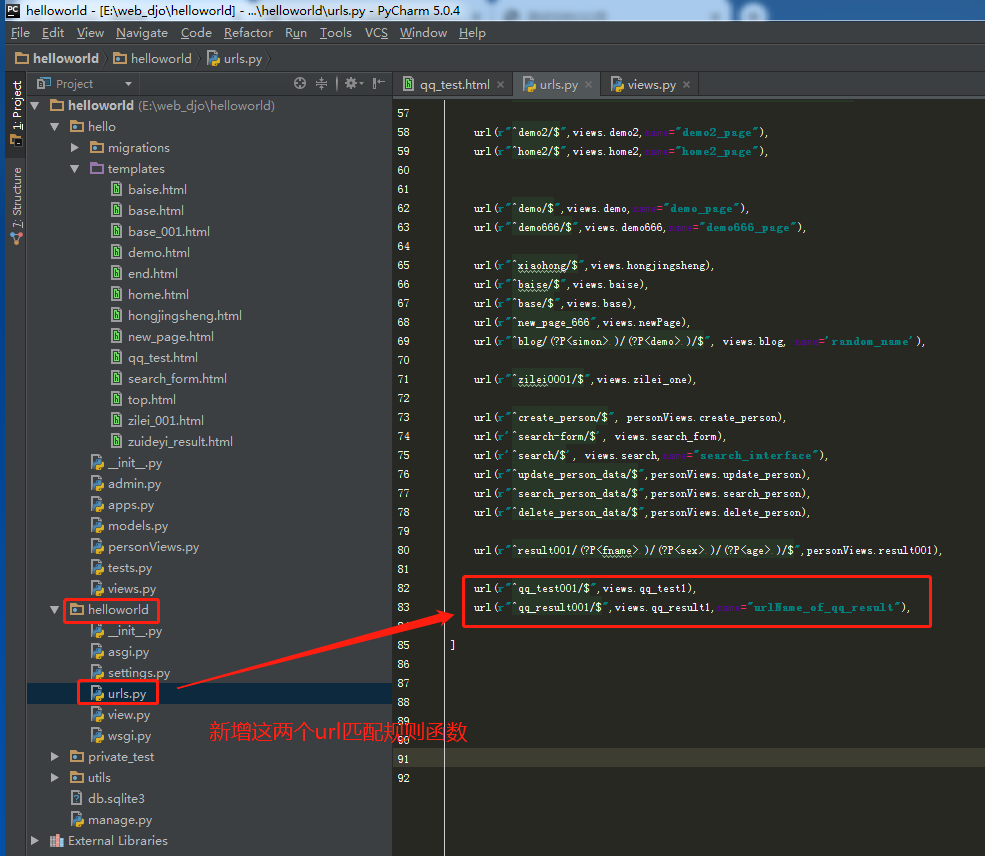
2.1.3.第三步:在项目【helloworld/helloworld/urls.py】里新增两个url匹配规则
2.1.5.第五步:任一浏览器上访问url【http://127.0.0.1:8000/qq_test001/】
2.1.6.第六步:在url【http://127.0.0.1:8000/qq_test001/】对应的页面里的提交字段【qq】里输入任一qq号并点击提交按钮
2.2.【场景实例二:获取前端请求后,对请求数据做处理(请求数据不涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;】的完整操作流程
2.2.1.第一步:在项目【helloworld/hello/views.py】里修改视图函数【qq_result1】
2.2.3.第三步:任一浏览器上访问url【http://127.0.0.1:8000/qq_test001/】
2.2.4.第四步:在url【http://127.0.0.1:8000/qq_test001/】对应的页面里的提交字段【qq】里输入任一qq号并点击提交按钮
2.3.【场景实例三:获取前端请求后,对请求数据做处理(请求数据涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;】的完整操作流程
2.3.1.第一步:在项目【helloworld/hello/templates/animal】里新增一个【animal_search_html.html】
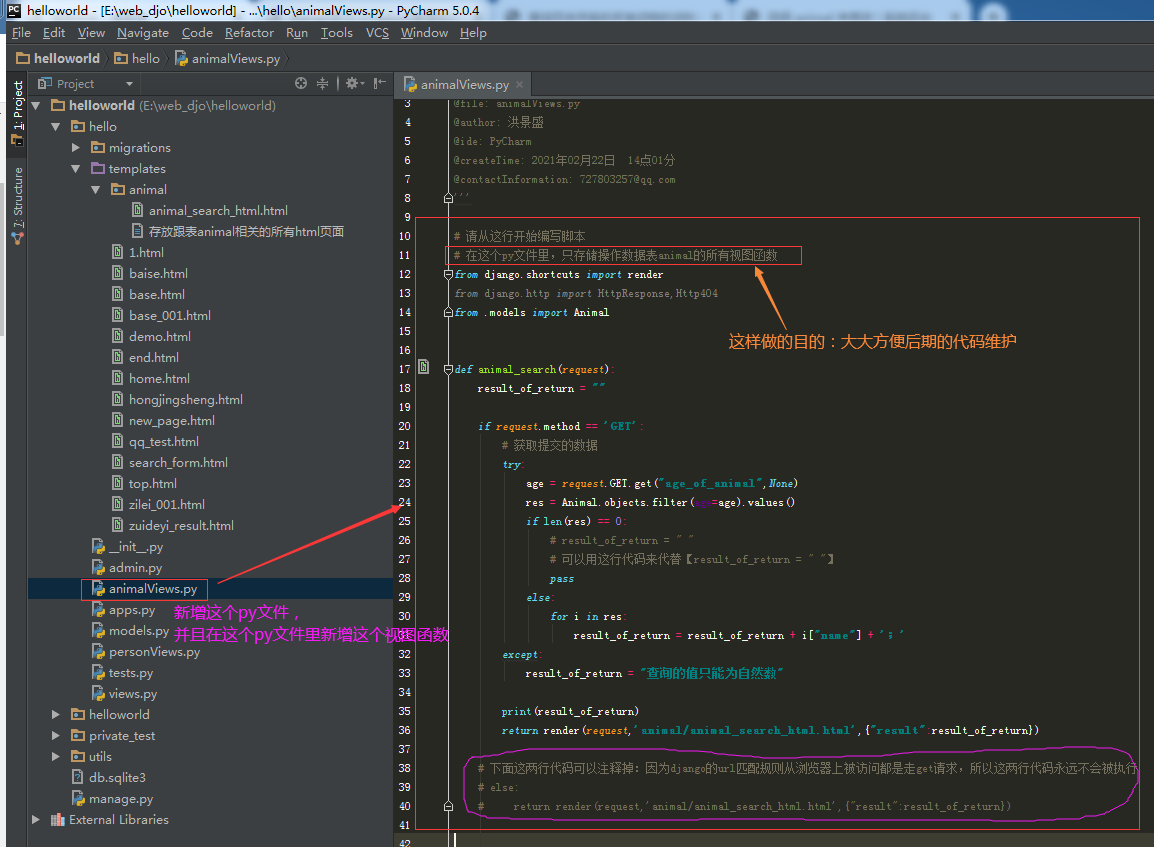
2.3.2.第二步:在项目【helloworld/hello/animalViews.py】里新增一个视图函数
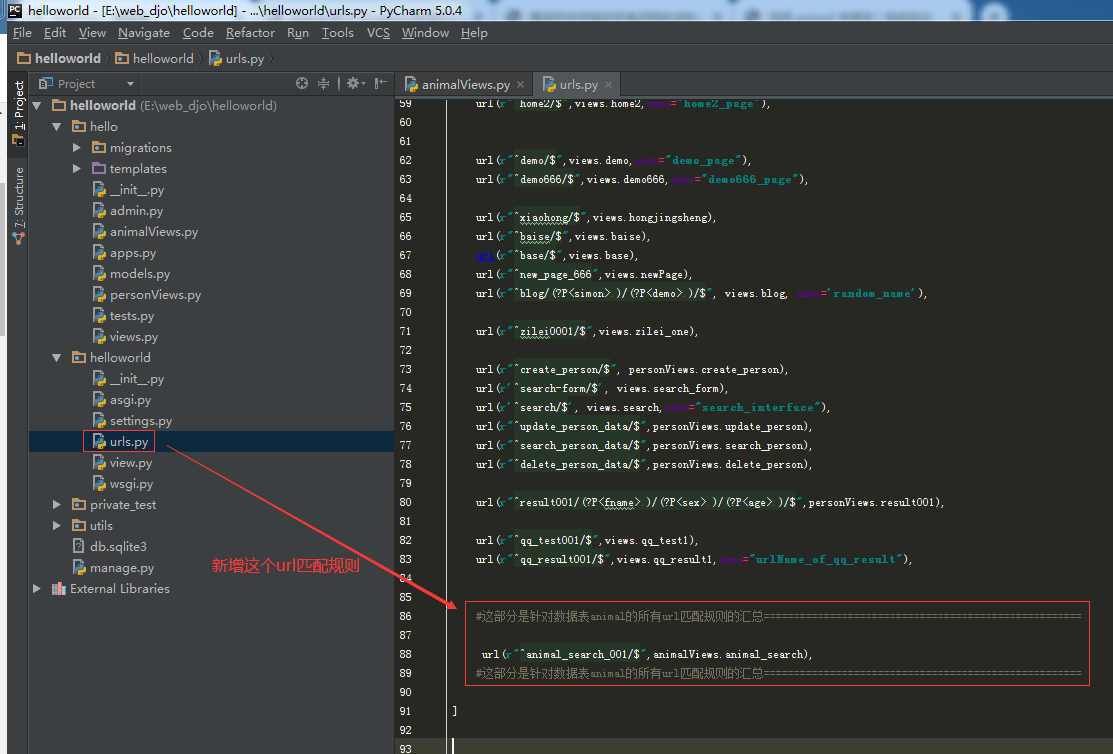
2.3.3.第三步:在项目【helloworld/helloworld/urls.py】里新增一个url匹配规则
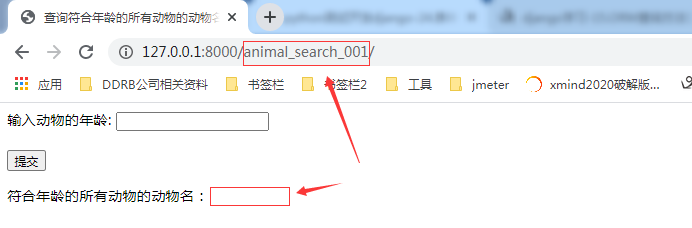
2.3.5.第五步:任一浏览器上访问url【http://127.0.0.1:8000/animal_search_001/】
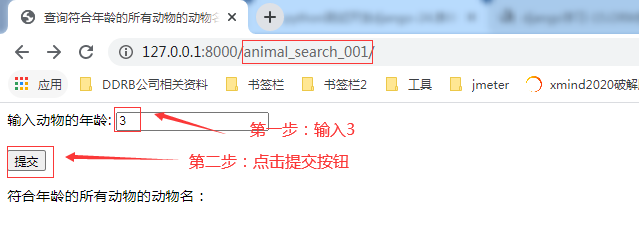
2.3.6.第六步:在url【http://127.0.0.1:8000/animal_search_001/】对应的页面里的提交字段【输入动物的年龄】里输入任一自然数值并点击提交按钮
1.写这篇博客的目的
记录表单提交方式get请求结合几个常见场景实例如何使用,以后即使我太久没用导致不会这个get请求的用法,也能通过查看这篇博客进行快速复习;
涉及表单提交方式的使用:从一个html页面通过任意一个表单提交方式把数据提交到服务端,服务端接收数据后判断提交的数据,然后做出对应的响应再返回给指定的html页面(这么一整个流程就是表单相关的知识点,会涉及到数据的交互);
相关三个场景实例分别是:
- 场景实例一:获取前端请求后,对请求数据不做处理,都会统一返回一个特定的结果;
- 场景实例二:获取前端请求后,对请求数据做处理(请求数据不涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;
- 场景实例三:获取前端请求后,对请求数据做处理(请求数据涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;
我们只需要知道这三个场景实例分别怎么使用即可,不用去学其他的场景实例;
表单提交方法有四种:post、get、delete、put,但主流99%常用的是post和get,尤其post比get更常用,比如某个电商公司的ecrp开放平台有360个接口且这360个接口的表单提交方式都是post,所以delete和put我们不需要去深入学习只需要有这个概念即可;
每个场景实际的具体实现可以分别看接下来的完整操作流程;
2.三个场景实际的完整操作流程
2.1.【场景实例一:获取前端请求后,对请求数据不做处理,都会统一返回一个特定的结果;】的完整操作流程
2.1.1.第一步:在项目【helloworld/hello/templates】里新增一个【qq_test.html】
细节:
①. 表单在html文件里由【<form>】标签实现。一个完整的表单包含四个部分:提交地址、请求方式、元素控件、提交按钮。四个部分的作用分别如下:
- 属性action 提交地址(设置用户提交的数据由哪个url接收和处理)
- 属性method 请求方式(主流常用的请求方式有get和post)
- 标签input 元素控件(输入文本信息)
- 属性submit 提交按钮(触发提交动作/触发对接收请求的url的访问)
②.在html文件里,每个标签比如【<form>】可以理解为是一个类;每个标签里的属性比如【标签<form>里的属性action】可以理解为是一个方法(python语言中,有类和方法的概念);
③.在html文件里,点击某个标签比如【<form>】,或者点击某个属性比如【action】,都能跳转到源码所在页面(html本身也是一门计算机语言,我们只需要怎么用就行,初级阶段不需要去了解源码);
④.属性action的值的相关知识点:
- 如果值为空字符串,表示:请求数据是提交给当前html页面;
- 如果值为一个包含url匹配规则里的参数name对应的参数值的值,比如值为【"{% url 'urlName_of_qq_result' %}"】,表示:请求数据是提交给这个参数name对应的参数值为【urlName_of_qq_result】的url匹配规则;
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>测试你的QQ号</title> </head> <body> <p>请输入你的QQ号</p> <form action="{% url 'urlName_of_qq_result' %}" method="get"> qq: <input type="text" name="q"> <br> <br> <input type="submit" value="提交"> </form> </body> </html>
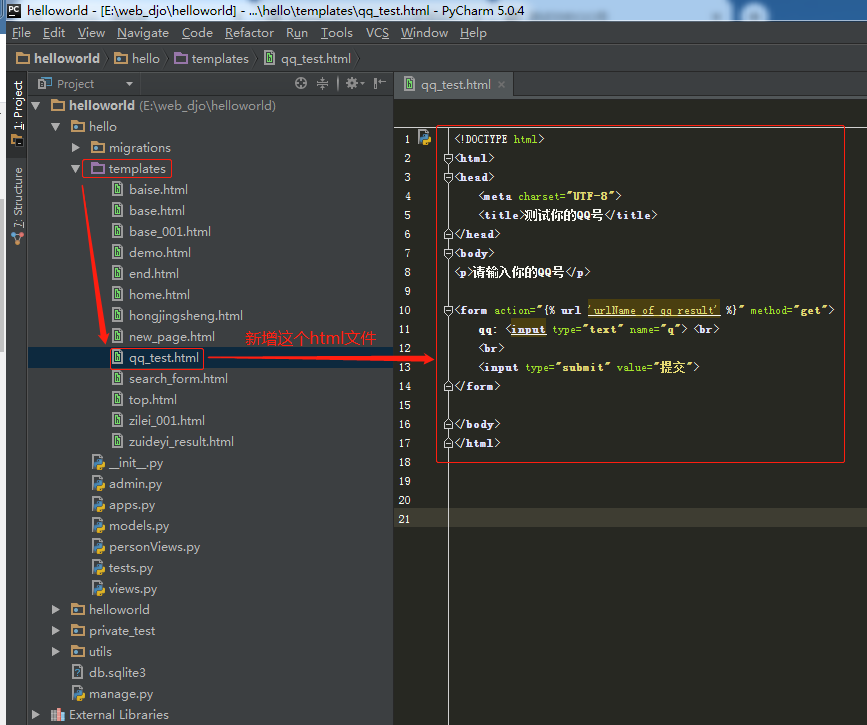
2.1.2.第二步:在项目【helloworld/hello/views.py】里新增两个视图函数
def qq_test1(request):
return render(request,'qq_test.html')
def qq_result1(request):
return HttpResponse("这个qq的数据提交成功了!")
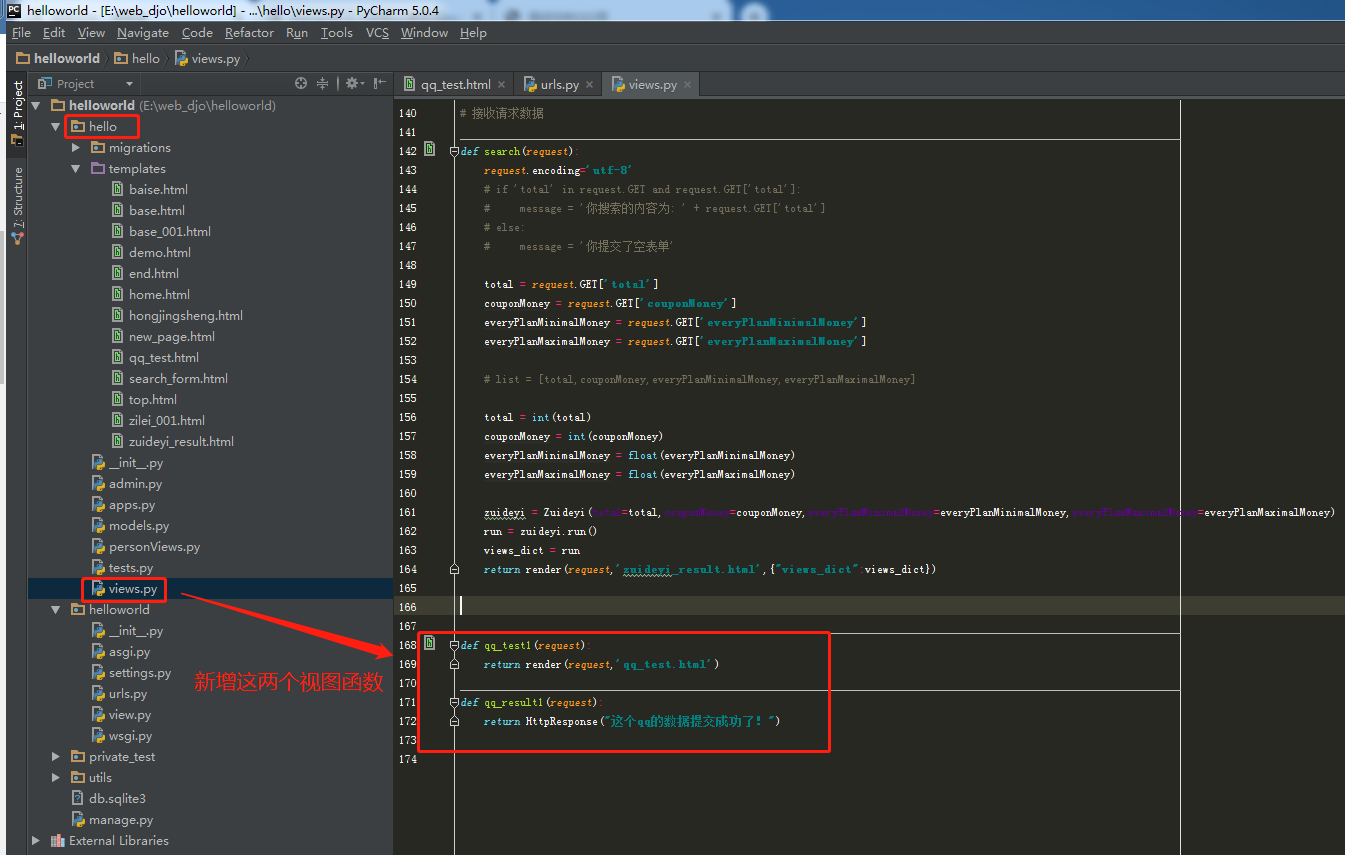
2.1.3.第三步:在项目【helloworld/helloworld/urls.py】里新增两个url匹配规则
url(r"^qq_test001/$",views.qq_test1), url(r"^qq_result001/$",views.qq_result1,name="urlName_of_qq_result"),
2.1.4.第四步:重启服务
2.1.5.第五步:任一浏览器上访问url【http://127.0.0.1:8000/qq_test001/】
2.1.6.第六步:在url【http://127.0.0.1:8000/qq_test001/】对应的页面里的提交字段【qq】里输入任一qq号并点击提交按钮

2.2.【场景实例二:获取前端请求后,对请求数据做处理(请求数据不涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;】的完整操作流程
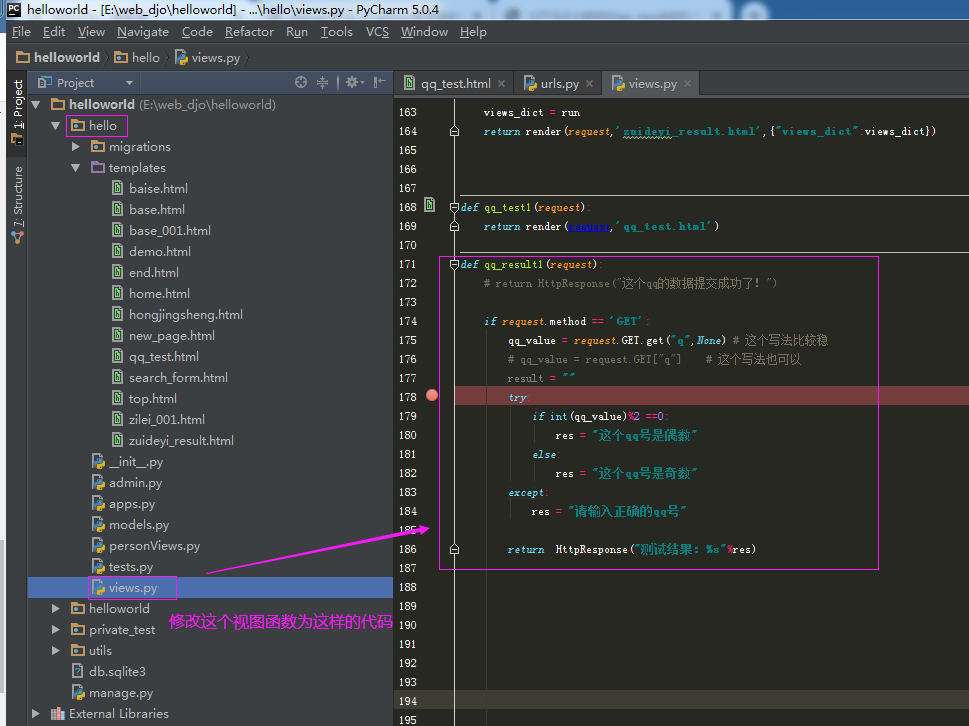
2.2.1.第一步:在项目【helloworld/hello/views.py】里修改视图函数【qq_result1】
细节:
①.【request.GET】可以看成一个字典,用GET方法传递的值都会保存到其中,可以用 request.GET['key_name']来取值。但是当key值不存在时,会报这个错误:“MultiValueDictKeyError”;
②.为了避免key值不存在时报错,我们可以用另外一种写法:request.GET.get("q",None);
③.request.GET['key_name']里的‘key_name’:指的是html页面里的form标签里的每个input标签里的name属性的属性名;
④.key值:指的是html页面里的form标签里的每个input标签里的name属性的值;
def qq_result1(request): # return HttpResponse("这个qq的数据提交成功了!") if request.method == 'GET':
# 获取前端页面提交的数据 qq_value = request.GET.get("q",None) # 这个写法比较稳 # qq_value = request.GET["q"] # 这个写法也可以 result = "" try: if int(qq_value)%2 ==0: res = "这个qq号是偶数" else: res = "这个qq号是奇数" except: res = "请输入正确的qq号" return HttpResponse("测试结果:%s"%res)
2.2.2.第二步:重启服务
2.2.3.第三步:任一浏览器上访问url【http://127.0.0.1:8000/qq_test001/】
2.2.4.第四步:在url【http://127.0.0.1:8000/qq_test001/】对应的页面里的提交字段【qq】里输入任一qq号并点击提交按钮

2.3.【场景实例三:获取前端请求后,对请求数据做处理(请求数据涉及跟数据表数据的对比校验),对不同的处理结果都会返回对应特定的结果;】的完整操作流程
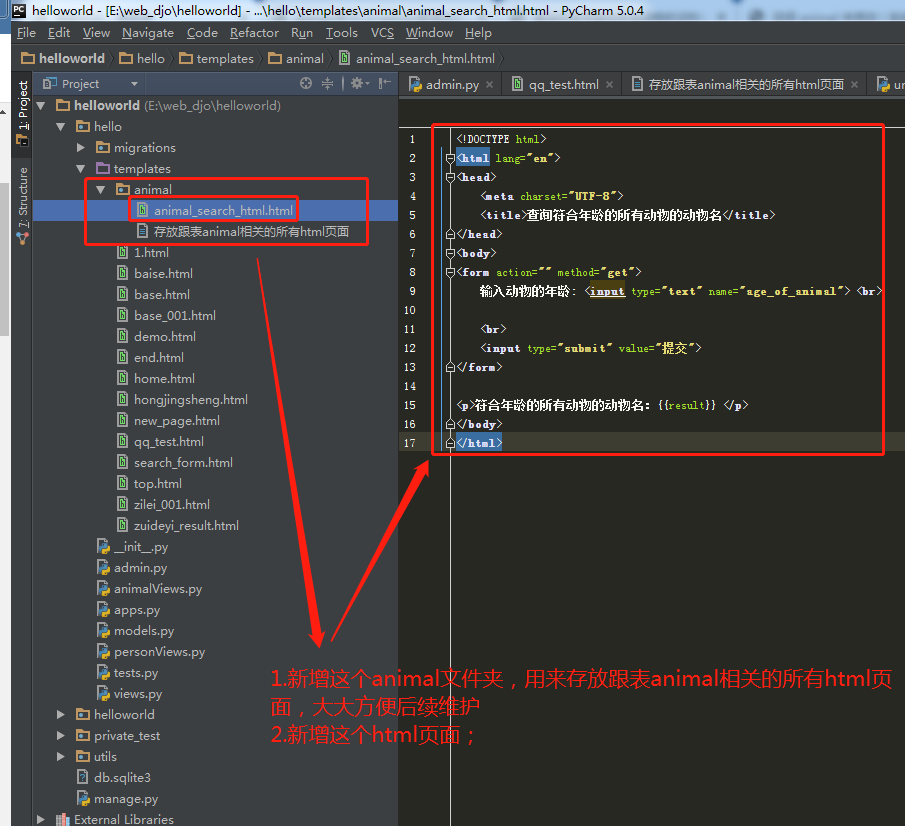
2.3.1.第一步:在项目【helloworld/hello/templates/animal】里新增一个【animal_search_html.html】
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>查询符合年龄的所有动物的动物名</title> </head> <body> <form action="" method="get"> 输入动物的年龄: <input type="text" name="age_of_animal"> <br> <br> <input type="submit" value="提交"> </form> <p>符合年龄的所有动物的动物名:{{result}} </p> </body> </html>
2.3.2.第二步:在项目【helloworld/hello/animalViews.py】里新增一个视图函数
# coding:utf-8 ''' @file: animalViews.py @author: 洪景盛 @ide: PyCharm @createTime: 2021年02月22日 14点01分 @contactInformation: 727803257@qq.com ''' # 请从这行开始编写脚本 # 在这个py文件里,只存储操作数据表animal的所有视图函数 from django.shortcuts import render from django.http import HttpResponse,Http404 from .models import Animal def animal_search(request): result_of_return = "" if request.method == 'GET': # 获取提交的数据 try: age = request.GET.get("age_of_animal",None) res = Animal.objects.filter(age=age).values() if len(res) == 0: # result_of_return = " " # 可以用这行代码来代替【result_of_return = " "】 pass else: for i in res: result_of_return = result_of_return + i["name"] + ';' except: result_of_return = "查询的值只能为自然数" print(result_of_return) return render(request,'animal/animal_search_html.html',{"result":result_of_return}) # 下面这两行代码可以注释掉:因为django的url匹配规则无论通过何种方式被访问都是走get请求,所以这两行代码永远不会被执行 # else: # return render(request,'animal/animal_search_html.html',{"result":result_of_return})
2.3.3.第三步:在项目【helloworld/helloworld/urls.py】里新增一个url匹配规则
#这部分是针对数据表animal的所有url匹配规则的汇总===================================================== url(r"^animal_search_001/$",animalViews.animal_search), #这部分是针对数据表animal的所有url匹配规则的汇总=====================================================
2.3.4.第四步:重启服务
2.3.5.第五步:任一浏览器上访问url【http://127.0.0.1:8000/animal_search_001/】
2.3.6.第六步:在url【http://127.0.0.1:8000/animal_search_001/】对应的页面里的提交字段【输入动物的年龄】里输入任一自然数值并点击提交按钮
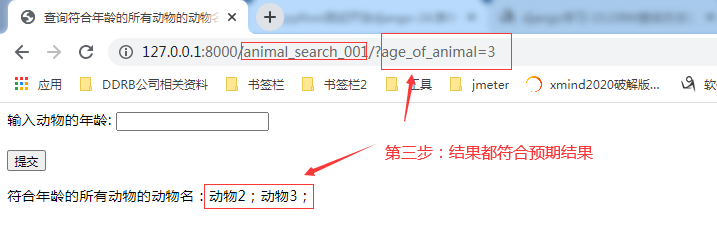
细节:
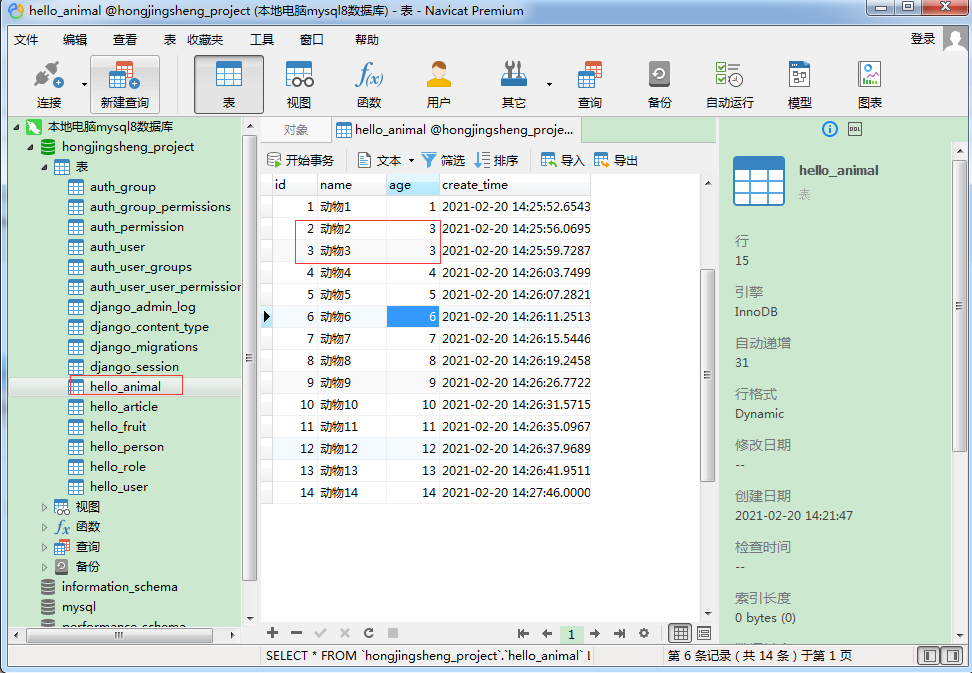
①.数据表animal(一般会把【应用名_数据表名】简称为【数据表名】,比如数据表【hello_animal】会简称为【animal】)的当前最新数据如下: