1 Hive
Hadoop在海量离线数据分析时遇到的问题:
开发调试一个复杂的MR程序,不适合要求快速得出结果的业务场景。
Hadoop是由Java开发的,MR天生对java支持最好,对其他语言的使用者不太友好。
需要对Hadoop底层具有一定的了解,并且要记忆大量的API,才能开发出一个优秀MR。
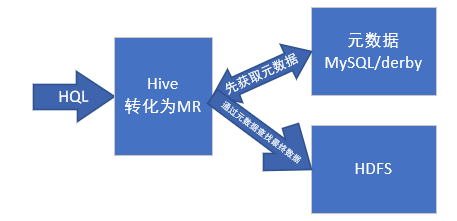
hive是一个基于hadoop的数据仓库,使用hiveQL(类sql)来实现分布式离线数据处理。
hive的优点:
1、不需要开发调试复杂的MR,适用于要求快速出结果的业务场景。
2、类SQL请多对所有的程序员都比较友好
3、不需要对hadoop底层有过深的了解
4、支持使用java或其他语言处理逻辑封装成UDF,来丰富函数库。
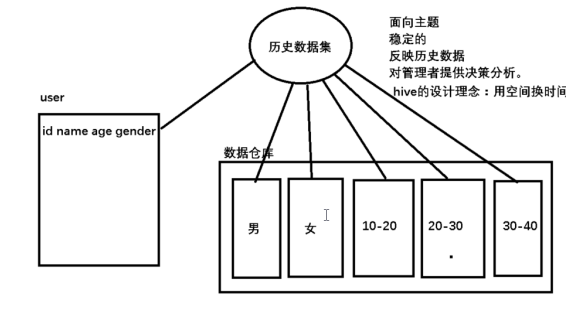
数据仓库的概念:
数据仓库是一个面向主题的,稳定的,反映历史数据的数据存储系统,一般用来为管理者提供决策分析。
数据仓库和数据库的区别:

数据表:
内部表:先有表,后有数据。删除表时,数据清空。
外部表:先有数据,后有表。删除表时,数据依然保留。
分区:
分区实现了数据仓库的面向主题的设计思想。
分桶表:
分桶表是用来测试,用hash模余的方式实现每桶中的数据都具有一定的代表性。
1.1 概述
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,也允许开发者使用java等语言解决复杂逻辑问题,并封装起来成为一个自定义函数(UDF),加载到hive中,来弥补原函数库的不足。
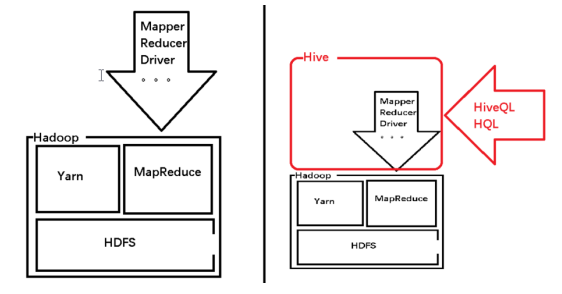
1.1.1 数据仓库
数据仓库是一个面向主题的,稳定的,反映历史数据的数据存储系统,一般用来为管理者提供决策分析。
1.2 Hive的安装
Hive的安装非常简单,上传,解压,启动。前提是,Hadoop要全量启动。配置JAVA_HOME,HADOOP_HOME。
Hadoop启动:
Start-all.sh全量启动hadoop。
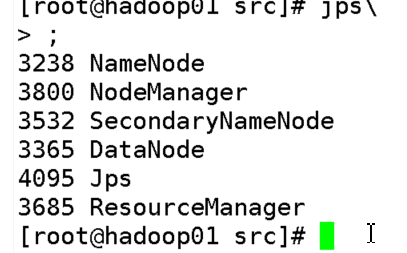
如果以上hadoop相关进程不全,先执行stop-all.sh停掉所有服务,然后start-all.sh重新启动。
Hive的启动:
进入hive的bin目录,执行./hive

1.3 基础操作
1.3.1 创建数据库
Create database db1;
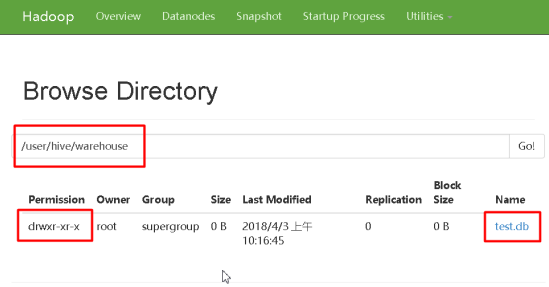
结论一:hive中的数据库在HDFS中就是/user/hive/warehouse目录下的一级以数据库名+.db命名的文件夹
1.3.2 创建表
create table tb_user (id int,name string) ;
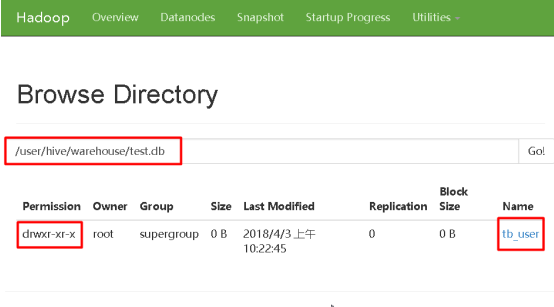
结论二:hive中的表在HDFS中就是在对应数据库文件夹下的一个文件夹。
1.3.3 插入数据
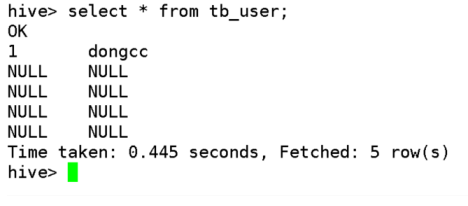
insert into table tb_user values(1,'dongcc');
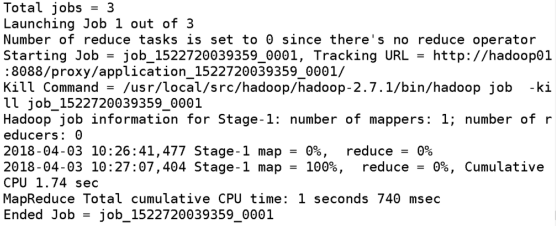
结论三:hive在必要时会将HQL翻译成MR来执行。

结论四:hive中的数据以文件的形式存放在HDFS中对应表的目录下。
1.3.4 载入数据
Load data local inpath ‘文件路径’ into table tb_user;
1.3.5 创建带有分隔符的表
create table tb_book (id int ,name string) row format delimited fields terminated by ' ';
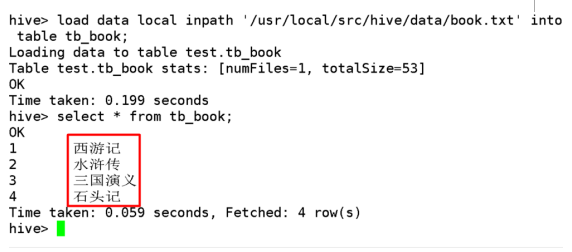
1.3.6 Default数据库
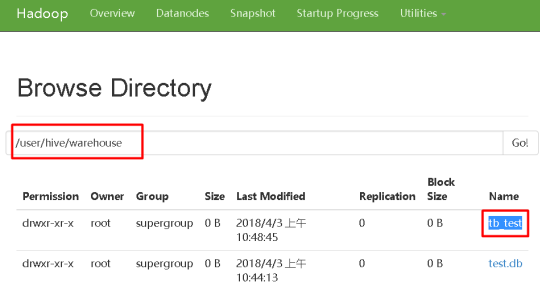
结论五:default数据库在HDFS中将数据直接存放在/user/hive/warehouse目录下。
1.3.7 可能遇到的问题
Hive启动不了
检查JAVA_HOME和HADOOP_HOME是否配置成功。如果没有问题并报错:Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
解决办法:
指定HADOOP_HOME路径
cd /usr/local/src/hive/apache-hive-1.2.0-bin/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
增加HADOOP_HOME

HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.7.1
Hive启动报错Safe mode
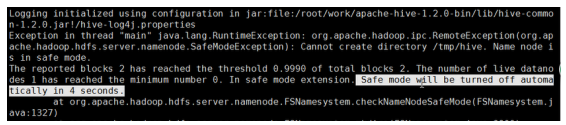
Hadoop在启动时有个安全模式,其在启动时有些工作要做,元数据的处理,DataNode的等待等过程。需要一段时间,遇到时需要等一段时间,耐心稍微等一会。过会自动就会好。
如果长时间还报错,还在安全模式。可以手工设置退出安全模式。
[root@hadoop01 bin]# pwd
/usr/local/src/hadoop/hadoop-2.7.1/bin
[root@hadoop01 bin]# ./hadoop dfsadmin -safemode leave
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Safe mode is OFF
[root@hadoop01 bin]#
参数value的说明如下:
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束
1.4 Hive元数据库的替换
元数据:hive中记录维护数据库,表,数据之间关系的数据。
Hive中的元数据存在传统的关系型数据库中。Derby数据库。
Derby基于文件,他只会维护hive启动目录下的元数据,更换启动目录后原来的数据丢失。
Hive官方提供了一些替换Derby的备选方案,oracle(收费) , mysql(免费)
1.4.1 替换元数据库为mysql
- 修改配置文件hive-site.xml
-
 hive-site.xml
hive-site.xml<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.220.1:3306/hive?createDatabaseIfNotExist=true</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> </configuration>
将配置文件修改后并不能成功启动hive,报错如下:

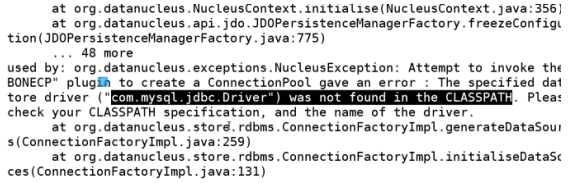
原因,我们并没有给hive相关的驱动包。
2.导入驱动包
直接将mysql驱动包上传到hive的lib目录中即可
但是再次尝试启动仍然报错,

没有访问权限,解决办法:开启mysql外部访问权限。
3.开启mysql外部访问权限
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges; #更新权限
如果上面修改后还提示权限错误,修改指定机器
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
flush privileges;
4.再次启动hive
1.4.2 Hive元数据库字符集必须为latin1
修改元数据库hive字符集为latin1:
登录到我们使用过的mysql中
Mysql> ALTER DATABASE hive DEFAULT CHARACTER SET latin1;

1.5 元数据信息

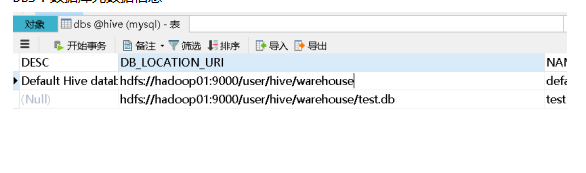
DBS:数据库元数据信息
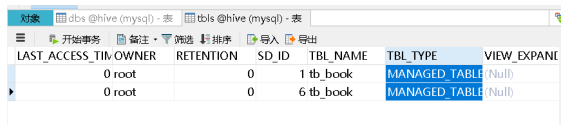
TBLS:表的元数据信息
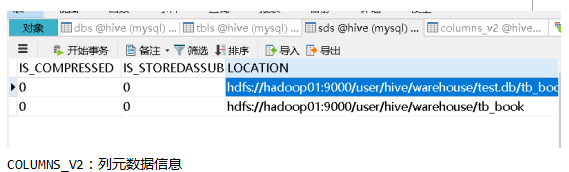
SDS:表的详细信息
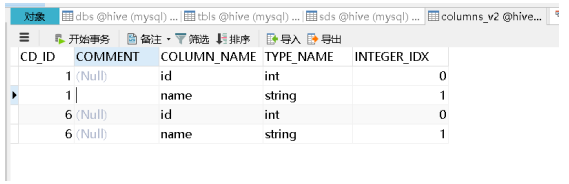
COLUMNS_V2:列元数据信息
1.6 Hadoop常用命令
启动:start-all.sh
关闭:stop-all.sh
格式化:hdfs namenode -format
创建目录:hadoop fs -mkdir /user
上传文件:hadoop fs -put ‘文件路径’ /user
删除文件:hadoop fs -rm /user/book.txt
删除目录:hadoop fs -rm -r /user
1.7 内部表和外部表
1.7.1 内部表(托管表):先有表后有数据
创建内部表:
Create table tb_book (id int ,name string)row format delimited fields termianted by ‘ ’;
加载数据:
load data local inpath '/usr/local/src/hive/data/book.txt' into table tb_book;
内部表在直接向HDFS中上传文件时,能够正确管理。
删除内部表:
Drop table tb_book;
元数据信息会被删除,HDFS中的相关目录和数据也会被删除。
1.7.2 外部表:先有数据后有表
准备数据:
Hadoop fs -mkdir /data
Hadoop fs -put ‘文件路径’ /data
创建外部表:
create external table ext_book(id int, name string) row format delimited fields terminated by ' ' location '/data';
直接加载数据到HDFS中,hive是可以正常维护的。
删除外部表
Drop table tb_stu;
元数据会被删除,但是HDFS中的文件不会被删除。
1.8 分区表
分区表,实现了数据仓库中面向主题的设计模式。
1.8.1 创建单级分区表
create table tb_book (id int,name string) partitioned by (country string) row format delimited fields terminated by ' ';
1.8.2 载入数据
load data local inpath '/usr/local/src/hive/data/ch.txt' overwrite into table tb_book partition (country='ch');
1.8.3 查看数据

发现结果集多了一列ch
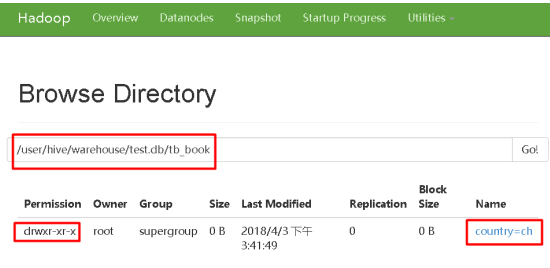
Hive中的分区表中的分区其实就是表目录下的一个文件夹。

手动加载数据到HDFS中即使按照他的规则创建了相关目录也没有能够正确维护。
我们需要修改表,添加对应的分区信息元数据。
1.8.4 添加分区信息
Alter table tb_book add partition (country=’ch’);
1.8.4.1 按分区查询数据
Select * from tb_book where country = ‘ch’;
1.8.5 创建多级分区表
create table tb_book2 (id int,name string) partitioned by (country string,gender string) row format delimited fields terminated by ' ';
加载数据
load data local inpath '/usr/local/src/hive/data/jp_male.txt' overwrite into table tb_book2 partition (country='jp',gender='male');
查询数据
Select * from tb_book2 where country = ‘ch’ and gender = ‘male’;
1.9 分桶表
分桶通过hash模余的方式,提取部分数据作为测试数据。
1.9.1 创建分桶表
create table tb_teacher(id int,name string) clustered by (id) into 4 buckets row format delimited fields terminated by ',';
1.9.2 从其他表中查出数据插入分桶表
insert overwrite table tb_teacher select * from tb_tmp;
1.9.3 数据取样
Select * from table_name tablesample (bucket x out of y on id);
其中x为第几个桶,不能大于总桶数, y为选取数据的步长(几个桶取一次数据)。Y应为桶数的因数或倍数,当y大于桶数时,选取结果非整桶抽取,而是抽取每桶中的y除以桶数分之一,即:1/(y/桶数)
Hive还支持用百分比的方式进行取样,但是该数据取出的是前百分之多少,不具备代表性。
select * from tb_tmp tablesample (50 percent);