参考:https://blog.csdn.net/u013719780/article/details/48901183
异常点检测方法
一、基本概念
异常对象被称作离群点。异常检测也称偏差检测和例外挖掘。
常见的异常成因:数据来源于不同的类(异常对象来自于一个与大多数数据对象源(类)不同的源(类)的思想),自然变异,以及数据测量或收集误差。
异常检测的方法:
(1)基于模型的技术:首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;如果模型是簇的集合,则异常是不显著属于任何簇的对象;在使用回归模型时,异常是相对远离预测值的对象。
(2)基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
(3)基于密度的技术:仅当一个点的局部密度显著低于它的大部分近邻时才将其分类为离群点。
二、异常点检测的方法
1、统计方法检测离群点
统计学方法是基于模型的方法,即为数据创建一个模型,并且根据对象拟合模型的情况来评估它们。大部分用于离群点检测的统计学方法都是构建一个概率分布模型,并考虑对象有多大可能符合该模型。离群点的概率定义:离群点是一个对象,关于数据的概率分布模型,它具有低概率。这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。异常检测的混合模型方法:对于异常检测,数据用两个分布的混合模型建模,一个分布为普通数据,而另一个为离群点。
聚类和异常检测目标都是估计分布的参数,以最大化数据的总似然(概率)。聚类时,使用EM算法估计每个概率分布的参数。然而,这里提供的异常检测技术使用一种更简单的方法。初始时将所有对象放入普通对象集,而异常对象集为空。然后,用一个迭代过程将对象从普通集转移到异常集,只要该转移能提高数据的总似然(其实等价于把在正常对象的分布下具有低概率的对象分类为离群点)。(假设异常对象属于均匀分布)。异常对象由这样一些对象组成,这些对象在均匀分布下比在正常分布下具有显著较高的概率。
优缺点:(1)有坚实的统计学理论基础,当存在充分的数据和所用的检验类型的知识时,这些检验可能非常有效;(2)对于多元数据,可用的选择少一些,并且对于高维数据,这些检测可能性很差。
2、基于邻近度的离群点检测。
一个对象是异常的,如果它远离大部分点。这种方法比统计学方法更一般、更容易使用,因为确定数据集的有意义的邻近性度量比确定它的统计分布更容易。一个对象的离群点得分由到它的k-最近邻的距离给定。离群点得分对k的取值高度敏感。如果k太小(例如1),则少量的邻近离群点可能导致较低的离群点得分;如果K太大,则点数少于k的簇中所有的对象可能都成了离群点。为了使该方案对于k的选取更具有鲁棒性,可以使用k个最近邻的平均距离。
优缺点:(1)简单;(2)缺点:基于邻近度的方法需要O(m2)时间,大数据集不适用;(3)该方法对参数的选择也是敏感的;(4)不能处理具有不同密度区域的数据集,因为它使用全局阈值,不能考虑这种密度的变化。
3、基于密度的离群点检测。
从基于密度的观点来说,离群点是在低密度区域中的对象。一个对象的离群点得分是该对象周围密度的逆。基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。需要小心的选择d,如果d太小,则许多正常点可能具有低密度,从而具有高离群点得分。如果d太大,则许多离群点可能具有与正常点类似的密度(和离群点得分)。使用任何密度定义检测离群点具有与基于邻近度的离群点方案类似的特点和局限性。特殊地,当数据包含不同密度的区域时,它们不能正确的识别离群点。
为了正确的识别这种数据集中的离群点,我们需要与对象邻域相关的密度概念,也就是定义相对密度。常见的有两种方法:(1)使用基于SNN密度的聚类算法使用的方法;(2)用点x的密度与它的最近邻y的平均密度之比作为相对密度。
使用相对密度的离群点检测(局部离群点要素LOF技术):首先,对于指定的近邻个数(k),基于对象的最近邻计算对象的密度density(x,k) ,由此计算每个对象的离群点得分;然后,计算点的邻近平均密度,并使用它们计算点的平均相对密度。这个量指示x是否在比它的近邻更稠密或更稀疏的邻域内,并取作x的离群点得分(这个是建立在上面的离群点得分基础上的)。
优缺点:
(1)给出了对象是离群点的定量度量,并且即使数据具有不同的区域也能够很好的处理;
(2)与基于距离的方法一样,这些方法必然具有O(m2)的时间复杂度。对于低维数据使用特定的数据结构可以达到O(mlogm);
(3)参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
4、基于聚类的技术
一种利用聚类检测离群点的方法是丢弃远离其他簇的小簇。这个方法可以和其他任何聚类技术一起使用,但是需要最小簇大小和小簇与其他簇之间距离的阈值。这种方案对簇个数的选择高度敏感。使用这个方案很难将离群点得分附加到对象上。一种更系统的方法,首先聚类所有对象,然后评估对象属于簇的程度(离群点得分)(基于原型的聚类可用离中心点的距离来评估,对具有目标函数的聚类技术该得分反映删除对象后目标函数的改进(这个可能是计算密集的))。基于聚类的离群点:一个对象是基于聚类的离群点,如果该对象不强属于任何簇。离群点对初始聚类的影响:如果通过聚类检测离群点,则由于离群点影响聚类,存在一个问题:结构是否有效。为了处理该问题,可以使用如下方法:对象聚类,删除离群点,对象再次聚类(这个不能保证产生最优结果)。还有一种更复杂的方法:取一组不能很好的拟合任何簇的特殊对象,这组对象代表潜在的离群点。随着聚类过程的进展,簇在变化。不再强属于任何簇的对象被添加到潜在的离群点集合;而当前在该集合中的对象被测试,如果它现在强属于一个簇,就可以将它从潜在的离群点集合中移除。聚类过程结束时还留在该集合中的点被分类为离群点(这种方法也不能保证产生最优解,甚至不比前面的简单算法好,在使用相对距离计算离群点得分时,这个问题特别严重)。
对象是否被认为是离群点可能依赖于簇的个数(如k很大时的噪声簇)。该问题也没有简单的答案。一种策略是对于不同的簇个数重复该分析。另一种方法是找出大量小簇,其想法是(1)较小的簇倾向于更加凝聚,(2)如果存在大量小簇时一个对象是离群点,则它多半是一个真正的离群点。不利的一面是一组离群点可能形成小簇而逃避检测。
优缺点:
(1)基于线性和接近线性复杂度(k均值)的聚类技术来发现离群点可能是高度有效的;
(2)簇的定义通常是离群点的补,因此可能同时发现簇和离群点;
(3)产生的离群点集和它们的得分可能非常依赖所用的簇的个数和数据中离群点的存在性;
(4)聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
异常检测算法--Isolation Forest
参考:https://www.cnblogs.com/fengfenggirl/p/iForest.html
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结。
iTree
提到森林,自然少不了树,毕竟森林都是由树构成的,看Isolation Forest(简称iForest)前,我们先来看看Isolation Tree(简称iTree)是怎么构成的,iTree是一种随机二叉树,每个节点要么有两个女儿,要么就是叶子节点,一个孩子都没有。给定一堆数据集D,这里D的所有属性都是连续型的变量,iTree的构成过程如下:
- 随机选择一个属性Attr;
- 随机选择该属性的一个值Value;
- 根据Attr对每条记录进行分类,把Attr小于Value的记录放在左女儿,把大于等于Value的记录放在右孩子;
- 然后递归的构造左女儿和右女儿,直到满足以下条件:
- 传入的数据集只有一条记录或者多条一样的记录;
- 树的高度达到了限定高度;

iTree构建好了后,就可以对数据进行预测啦,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点;对于一个包含n条记录的数据集,其构造的树的高度最小值为log(n),最大值为n-1,论文提到说用log(n)和n-1归一化不能保证有界和不方便比较,用一个稍微复杂一点的归一化公式:
,
s(x,n)s(x,n)就是记录x在由n个样本的训练数据构成的iTree的异常指数,s(x,n)s(x,n)取值范围为[0,1],越接近1表示是异常点的可能性高,越接近0表示是正常点的可能性比较高,如果大部分的训练样本的s(x,n)都接近于0.5,说明整个数据集都没有明显的异常值。
随机选属性,随机选属性值,一棵树这么随便搞肯定是不靠谱,但是把多棵树结合起来就变强大了;
iForest
iTree搞明白了,我们现在来看看iForest是怎么构造的,给定一个包含n条记录的数据集D,如何构造一个iForest。iForest和Random Forest的方法有些类似,都是随机采样一一部分数据集去构造每一棵树,保证不同树之间的差异性,不过iForest与RF不同,采样的数据量PsiPsi不需要等于n,可以远远小于n,论文中提到采样大小超过256效果就提升不大了,明确越大还会造成计算时间的上的浪费,为什么不像其他算法一样,数据越多效果越好呢,可以看看下面这两个个图,
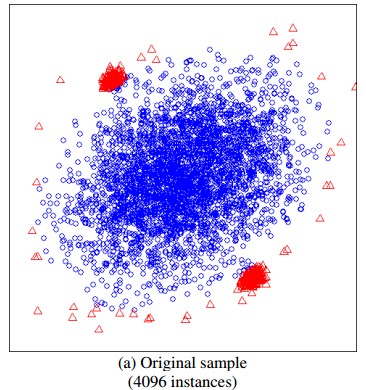

左边是元素数据,右边是采样了数据,蓝色是正常样本,红色是异常样本。可以看到,在采样之前,正常样本和异常样本出现重叠,因此很难分开,但我们采样之和,异常样本和正常样本可以明显的分开。
除了限制采样大小以外,还要给每棵iTree设置最大高度l=ceiling(logΨ2)l=ceiling(log2Ψ),这是因为异常数据记录都比较少,其路径长度也比较低,而我们也只需要把正常记录和异常记录区分开来,因此只需要关心低于平均高度的部分就好,这样算法效率更高,不过这样调整了后,后面可以看到计算h(x)h(x)需要一点点改进,先看iForest的伪代码:

IForest构造好后,对测试进行预测时,需要进行综合每棵树的结果,于是
E(h(x))E(h(x))表示记录x在每棵树的高度均值,另外h(x)计算需要改进,在生成叶节点时,算法记录了叶节点包含的记录数量,这时候要用这个数量SizeSize估计一下平均高度,h(x)的计算方法如下:

处理高维数据
在处理高维数据时,可以对算法进行改进,采样之后并不是把所有的属性都用上,而是用峰度系数Kurtosis挑选一些有价值的属性,再进行iTree的构造,这跟随机森林就更像了,随机选记录,再随机选属性。
只使用正常样本
这个算法本质上是一个无监督学习,不需要数据的类标,有时候异常数据太少了,少到我们只舍得拿这几个异常样本进行测试,不能进行训练,论文提到只用正常样本构建IForest也是可行的,效果有降低,但也还不错,并可以通过适当调整采样大小来提高效果。