前言
问题:普通套接字实现的服务端的缺陷
一次只能服务一个客户端!


在没有新的套接字来之前,不能处理已经建立连接的套接字的请求
recv 阻塞!
在没有接受到客户端请求数据之前,不能与其他客户端建立连接
可以用非阻塞接口来尝试解决这个问题
IO阻塞与非阻塞
阻塞IO模型
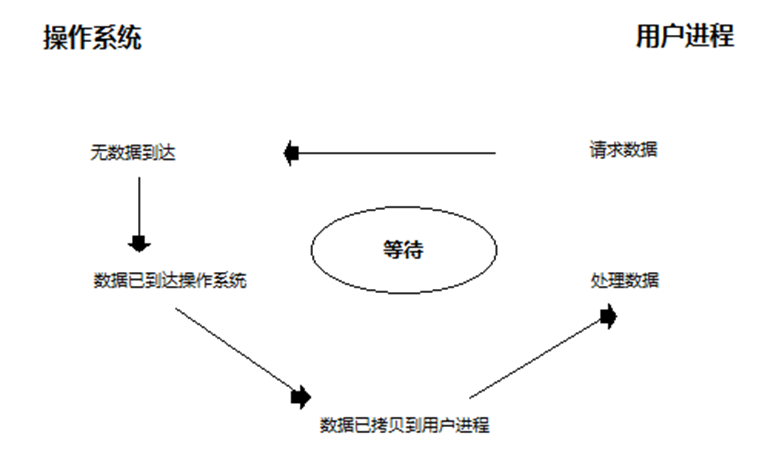
阻塞IO(blocking IO)的特点:就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
什么是阻塞呢?想象这种情形,比如你等快递,但快递一直没来,你会怎么做?有两种方式:
- 快递没来,我可以先去睡觉,然后快递来了给我打电话叫我去取就行了。
- 快递没来,我就不停的给快递打电话说:擦,怎么还没来,给老子快点,直到快递来。
很显然,你无法忍受第二种方式,不仅耽搁自己的时间,也会让快递很想打你。
而在计算机世界,这两种情形就对应阻塞和非阻塞忙轮询。
- 非阻塞忙轮询:数据没来,进程就不停的去检测数据,直到数据来。
- 阻塞:数据没来,啥都不做,直到数据来了,才进行下一步的处理。
非阻塞IO模型

非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有
非阻塞如何利用
- 宁可用 while True ,也不要阻塞发呆!
- 只要资源没到,就先做别的事!
服务器端
import socket CONN_ADDR = ('127.0.0.1', 9999) conn_list = [] # 连接列表 sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM) # 开启socket sock.setblocking(False) # 设置为非阻塞 sock.bind(CONN_ADDR) # 绑定IP和端口到套接字 sock.listen(5) # 监听,5表示客户端最大连接数 print('start listen') while True: try: conn, addr = sock.accept() # 被动接受TCP客户的连接,等待连接的到来,收不到时会报异常 print('connect by ', addr) conn_list.append(conn) conn.setblocking(False) # 设置非阻塞 except BlockingIOError as e: pass tmp_list = [conn for conn in conn_list] for conn in tmp_list: try: data = conn.recv(1024) # 接收数据1024字节 if data: print('收到的数据是{}'.format(data.decode())) conn.send(data) else: print('close conn',conn) conn.close() conn_list.remove(conn) print('还有客户端=>',len(conn_list)) except IOError: pass
客户端
import socket client = socket.socket() client.connect(('127.0.0.1', 9999)) while True: msg = input(">>>") if msg != 'q': client.send(msg.encode()) data = client.recv(1024) print('收到的数据{}'.format(data.decode())) else: client.close() print('close client socket') break
输出结果

非阻塞IO模型优点:实现了同时服务多个客户端,能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在“”同时“”执行)。
但是非阻塞IO模型绝不被推荐
非阻塞IO模型缺点:不停地轮询recv,占用较多的CPU资源。
对应BlockingIOError的异常处理也是无效的CPU花费 !
如何解决:多路复用IO
多路复用IO
把socket交给操作系统去监控,相当于找个代理人(select), 去收快递。快递到了,就通知用户,用户自己去取。
阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作,所以才叫做多路复用
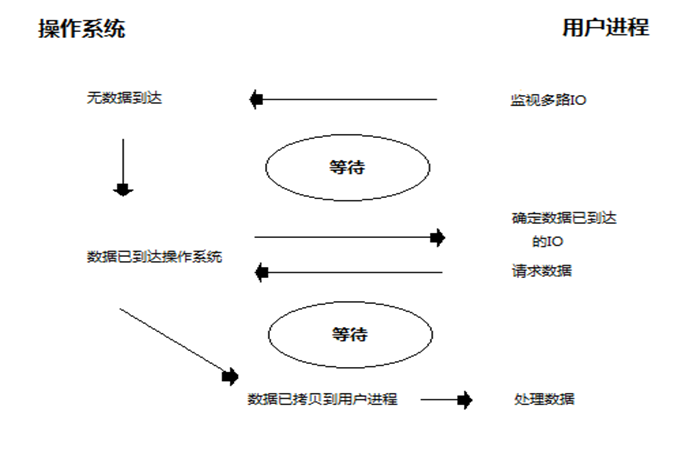
使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数的额外操作,感觉效率更差。
但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,
即可达到在同一个线程内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
epoll是目前Linux上效率最高的IO多路复用技术。
epoll是惰性的事件回调,惰性事件回调是由用户进程自己调用的,操作系统只起到通知的作用。
epoll实现并发服务器,处理多个客户端
import socket import selectors # 注册一个epllo事件 # 1. socket # 2.事件可读 # 3.回调函数 把一个函数当成变量传到函数里 def recv_data(conn): data = conn.recv(1024) if data: print('接收的数据是:%s' % data.decode()) conn.send(data) else: e_poll.unregister(conn) conn.close() def acc_conn(p_server): conn, addr = p_server.accept() print('Connected by', addr) # 也有注册一个epoll e_poll.register(conn,selectors.EVENT_READ,recv_data) CONN_ADDR = ('127.0.0.1', 9999) server = socket.socket() server.bind(CONN_ADDR) server.listen(6) # 表示一个客户端最大的连接数 # 生成一个epllo选择器实例 I/O多路复用,监控多个socket连接 e_poll = selectors.EpollSelector() # window没有epoll使用selectors.DefaultSelector()实现多路复用 e_poll.register(server, selectors.EVENT_READ, acc_conn) # 事件循环 while True: # 事件循环不断地调用select获取被激活的socket events = e_poll.select() #print(events) """[(SelectorKey(fileobj= < socket.socket laddr = ('127.0.0.1',9999) >,……data = < function acc_conn at 0xb71b96ec >), 1)] """ for key, mask in events: call_back = key.data #print(key.data) call_back(key.fileobj)
输出结果
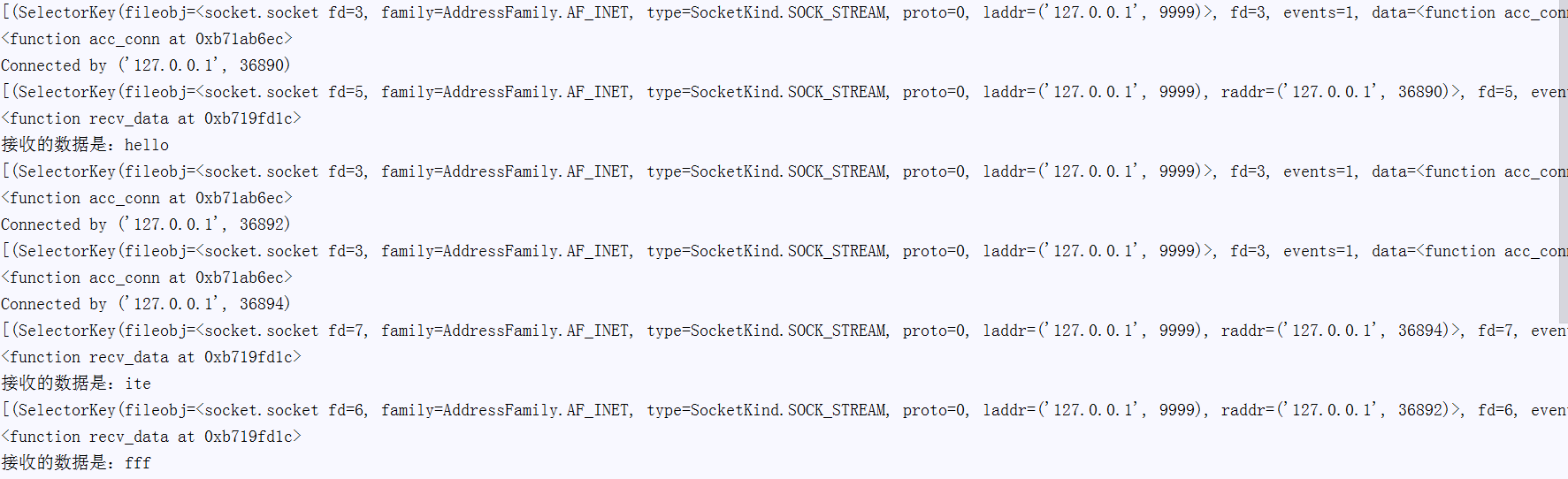
多路复用模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,