下载中间件
下载器中间件是介于Scrapy的request/response处理的钩子框架。 是用于全局修改Scrapy request和response的一个轻量、底层的系统
编写您自己的下载器中间件
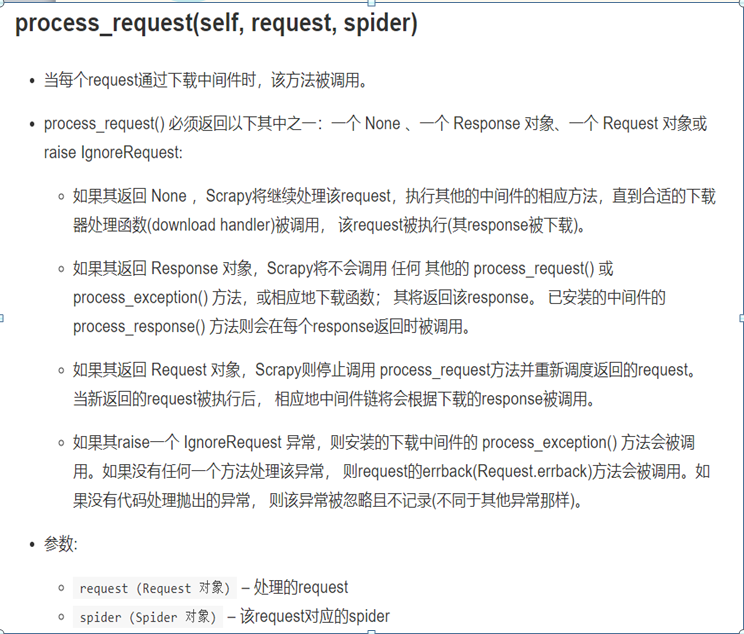
每个中间件组件是一个定义了以下一个或多个方法的Python类

使用中间件随机选择头部信息
1. 创建项目
scrapy startproject chinaarea
2. 创建爬虫文件
scrapy genspider airs "www.aqistudy.cn"
class AirsSpider(scrapy.Spider): name = 'airs' allowed_domains = ['aqistudy.cn'] baseUrl = 'https://www.aqistudy.cn/historydata/' start_urls = [baseUrl] def parse(self, response): yield scrapy.Request(url='https://www.baidu.com',callback=self.parse)
3.创建下载中间件
from chinaarea.settings import USER_AGENTS as ua_list import random class UserAgentMiddleware(object): """ 给每个请求随机选取user_Agent """ def process_request(self,request, spider): user_agent = random.choice(ua_list) request.headers['USER_AGENTS'] = user_agent # request.meta['proxy'] 设置代理 print('request: ', request.headers['USER_AGENTS'] ) print('*'*30)
4.设置setting
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3192.0 Safari/537.36Name"
]
DOWNLOADER_MIDDLEWARES = {
'chinaarea.middlewares.UserAgentMiddleware': 543,
}
爬取天气网
编写item
import scrapy class ChinaareaItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass # 城市 city = scrapy.Field() # 日期 date = scrapy.Field() # 空气质量指数 aqi = scrapy.Field() # 空气质量等级 level = scrapy.Field() # pm2.5 pm2_5 = scrapy.Field() # pm10 pm10 = scrapy.Field() # 二氧化硫 so2 = scrapy.Field() # 一氧化碳 co = scrapy.Field() # 二氧化氮 no2 = scrapy.Field() # 臭氧 o3 = scrapy.Field() # 数据源 source = scrapy.Field() # utctime utc_time = scrapy.Field()
编写spider
from chinaarea.items import ChinaareaItem class AirSpider(scrapy.Spider): name = 'airs' allowed_domains = ['aqistudy.cn'] base_url = "https://www.aqistudy.cn/historydata/" start_urls = [base_url] def parse(self, response): print("正在爬取城市信息...") url_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/@href').extract()[10:11] city_list = response.xpath('//div[@class="all"]/div[@class="bottom"]//a/text()').extract()[10:11] for city, url in zip(city_list, url_list): link = self.base_url + url yield scrapy.Request(url=link, callback=self.parse_month, meta={"city":city}) def parse_month(self, response): print("正在爬取城市月份...") url_list = response.xpath("//tr/td/a/@href").extract()[0:2] for url in url_list: url = self.base_url + url yield scrapy.Request(url=url, meta={"city":response.meta['city']}, callback=self.parse_day) def parse_day(self, response): print("爬取最终数据...") node_list = response.xpath('//tr') node_list.pop(0) for node in node_list: item = ChinaareaItem() item['city'] = response.meta['city'] item['date'] = node.xpath('./td[1]/text()').extract_first() item['aqi'] = node.xpath('./td[2]/text()').extract_first() item['level'] = node.xpath('./td[3]//text()').extract_first() item['pm2_5'] = node.xpath('./td[4]/text()').extract_first() item['pm10'] = node.xpath('./td[5]/text()').extract_first() item['so2'] = node.xpath('./td[6]/text()').extract_first() item['co'] = node.xpath('./td[7]/text()').extract_first() item['no2'] = node.xpath('./td[8]/text()').extract_first() item['o3'] = node.xpath('./td[9 ]/text()').extract_first() yield item
编写Middleware
from selenium import webdriver import time import scrapy class SeleniumMiddleware(object): def process_request(self, request, spider): self.driver = webdriver.Chrome() if request.url != "https://www.aqistudy.cn/historydata/": self.driver.get(request.url) time.sleep(2) html = self.driver.page_source self.driver.quit() return scrapy.http.HtmlResponse(url=request.url, body=html, encoding="utf-8", request=request)
编写pipeline
import json from datetime import datetime class ChinaareaPipeline(object): def process_item(self, item, spider): item['source'] = spider.name item['utc_time'] = str(datetime.utcnow()) return item class AreaJsonPipeline(object): def open_spider(self, spider): self.file = open("area.json", "w") def process_item(self, item, spider): content = json.dumps(dict(item), ensure_ascii=False) + " " self.file.write(content) return item def close_spider(self, spider): self.file.close()
.设置setting
'chinaarea.middlewares.SeleiumMiddleware': 200,
ITEM_PIPELINES = {
'chinaarea.pipelines.ChinaareaPipeline':200,
'chinaarea.pipelines.AreaJsonPipeline': 300,
}
