http://liuxw0035.blog.163.com/blog/static/67686537201121455058919/
现如今的EBS系统中,为了推进国际化的进程,以及系统向全球化的扩展,在Oracle数据库的编码方式上渐渐从支持中国本土简体中文的ZHS16GBK转向了更趋于国际化的AL32UTF8编码方式。但随之而来在中国就会产生很多问题,例如:
- 其他的外围系统仍然使用简体中文GB2312/ZHS16GBK编码,在接口文件传输时由于编码不一致而产生乱码问题
- Excel不兼容,简体中文版的Excel在读取文本文件时采用的是默认的简体中文编码方式打开,所以已UTF-8编码的文件(如CSV文件)在打开时会产生乱码问题
所以在中国的IT系统,一旦选择采用了AL32UTF8的国际化编码方式之后,了解一些编码方式的区别以及常见问题的解决方法是非常必要的。
编码方式
这里就不深入讨论编码的知识了,简单阐述一下二者的不同之处,见如下表格:
| 编码方式 | 隶属于 | 一个中文字符所占字节 | 说明 |
| ZHS16GBK | ANSI | 2 | 与所有隶属于ANSI的编码兼容 |
| AL32UTF8 | Unicode | 3 | 与所有隶属于Unicode的编码兼容 |
所以二者属于两套字符集衍生出来的,所以并不兼容,需要显示的进行转码才能正常显示。
PLSQL/SQL客户端的配置
客户端配置需要考虑Oracle Client的所支持的语言和注册表中NLS_LANG键值的设置。
- Oracle客户端需要安装兼容64为的32位客户端:win32_11gR2_client,具体请从Oracle官方网站上进行下载;
- NLS_LANG的键值需要设置成“AMERICAN_AMERICA.AL32UTF8” 或者 “SIMPLIFIED CHINESE_CHINA.AL32UTF8”
EBS基础设置
请确保一下表格中列示的配置文件已经设置了正确的值:
| 配置文件名称 | 设置层 | 配置文件值 |
| FND: NATIVE CLIENT ENCODING | SITE | UTF8 |
| ICX: Client IANA Encoding | SITE | Unicode (UTF-8) |
当为文本类型输出格式设置新的打开方式时,请确保“Allow Native Client Encoding”已经勾选。
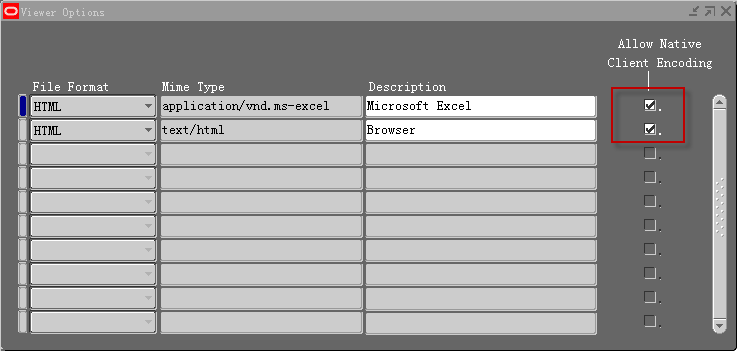
报表类程序(HTML, HTML as EXCEL, PDF)
对于HTML的报表,需要在HTML头上指定encoding为utf-8:<meta http-equiv="Content-Type" content="text/html;charset=utf-8"/>
另外编码方式可以用一下代码动态从系统中获取:
l_encoding := fnd_profile.value('ICX_CLIENT_IANA_ENCODING');
对于PDF输出类报表,以上获取编码方式的方法仍然适用,并填充值XML的头部:
<?xml version="1.0" encoding="utf-8"?>
另外,如果报表输出的中文全部显示成问号“?”,那么这种情况并不是编码方式导致的,而是服务器上缺失了必要的字体文件,在后台运行如下脚本复制字体文件到指定目录下:
#!/bin/sh cp $FND_TOP/resource/ALBAN*.ttf $AF_JRE_TOP/lib/fonts

文件读写及外部接口兼容
1. 文件输出
对于从Oracle生成并输出的文本文件,默认的编码方式肯定是UTF-8(无BOM)的。所以一旦目标系统的编码方式是简体中文的话,那么转码的步骤一定是必须的。我们可以从两个阶段入手进行转码。
第一个阶段是在每一批写入文件的数据在写入文件之前强制利用CONVERT函数进行转码,如:
l_converted_str := CONVERT('你好', 'ZHS32GB18030');
第二个阶段是就是在文件生成之后,利用相对高级的文本编辑器,如Notepad++,对文件进行转码UTF-8 -> ANSI
2. 文件读取
与文件类似,只不过只能利用文本编辑器提前转码之后方能被Oracle处理。
Excel文件输出和Export导出
utf-8格式的csv或分割符文件在excel打开会出现乱码的情况:
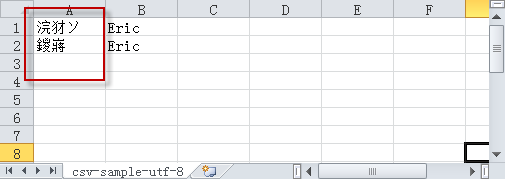
utf-8格式的文本文件
利用文本编辑器进行转码后方能正确显示:
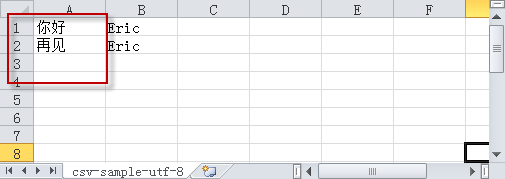
ansi格式的文件
总结
1. 检查配置文件和View Options是否设置正确
2. HTML格式报表记得要动态从系统中获取encoding
3. PDF报表记得安装字体
4. 输出到外部的文件需要进行必要转码操作(convert函数或文本编辑器)