这是一篇行人重识别的综述文章,作为我该方向入门的基础读物
Title: Person Re-identification: Past, Present and Future [PDF]
Authors: Liang Zheng, Yi Yang, Alexander G. Hauptmann
Affiliation: the Centre for Quantum Computation and Intelligent Systems, University of Technology at Sydney, NSW, Australia.
Date: Oct 2016
摘要
过去的行人重识别算法主要是手工设计特征+小规模的评价,现今是大规模数据+深度学习。这篇文章将行人重识别分成了基于图像和基于视频两类,每类分别按照手工设计(hand-craft)和深度学习方法进行介绍。除此之外还将介绍两个与现实更紧密的任务:端到端的重识别和大的gallery下的快速重识别。论文的安排:1)介绍行人重识别的历史,以及其与分类和检索的关系;2)广泛调查关于人工设计和大规模数据集的方法,包括基于图像和基于视频的重识别;3)介绍了关键的未来方向,包括端到端和大规模gallery下的快速检索;4)简要总结一些重要但尚未发展的问题。
1. 介绍
定义: “In video surveillance, when being presented with a person-of-interest (query), person re-ID tells whether this person has been observed in another place (time) by another camera.”
技术上讲,一个可用的行人重识别系统分为三个部分:person detection, person tracking, and person retrieval. 前两个又被看作是单独的计算机视觉任务,所以一般把行人重识别问题看作是person retrieval模块。这篇文章如果不额外说明也是这样。
1.2 行人重识别的简短历史回顾
行人重识别起源于多摄像头追踪问题。这篇文章(15年)之前的里程碑式的成果如下图:
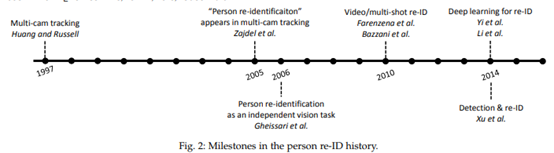
多摄像头追踪(1997)。最开始行人重识别是和多摄像头追踪一并处理的。
针对专门的“行人重识别”的多摄像头追踪(2005)。
基于图像(实际上是视频帧)的、作为独立任务的行人重识别(2006)。
基于视频的行人重识别(2010)。
基于深度学习的行人重识别(2014,两篇文章)(两篇都用Siamese network)。
端到端的基于图像的行人重识别(2014)。
1.3 行人重识别和分类、检索的关系

2. 基于图像的行人重识别
行人重识别问题多数被视为单张图像的检索问题。定义 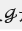 是包含了N章图像的gallery (database),表示为 。这些图像属于N个不同的identities(每个identity仅有一张图像?)。给定一张查询(query)图像 ,则:
是包含了N章图像的gallery (database),表示为 。这些图像属于N个不同的identities(每个identity仅有一张图像?)。给定一张查询(query)图像 ,则:

其中, 是q的identity,
是q的identity,  表示相似性。
表示相似性。
2.1 人工设计的系统
很明显上述公式有两个不可缺少的部分,即图像描述(image description)和距离度量(distance metrics)。
2.1.1 行人描述(翻译为主)
在行人描述中,最常用的特征是颜色,而纹理特征则没那么常见。在[13]中,行人前景从背景中分割出来,并为每个身体部位计算出对称轴。根据人体结构,计算出加权颜色直方图(WH)、最大稳定颜色区域(MSCR)和反复出现的高结构图像块(the recurrent high-structured patches,RHSP)。WH为对称轴附*的像素指定较大的权重,并在每个部分生成颜色直方图。MSCR检测稳定的颜色区域并提取颜色、区域和形心等特征。RHSP则是一种纹理特征,它捕获反复出现的纹理图斑。Gheissari等人[11]提出了一种检测稳定前景区域的时空分割方法。对于局部区域,计算HS直方图和边缘直方图。后者编码主要的局部边界方向和边缘两侧的RGB比率。Gray和Tao[24]在亮度通道上使用8个颜色通道(RGB、HS和YCBCR)和21个纹理过滤器,并将行人划分为水*条纹。许多后来的文章[25]、[26]、[27]使用了与[24]相同的特征集。类似地,Mignon等人[28]根据RGB、YUV和HSV通道以及水*条纹中的LBP纹理柱状图构建特征向量。
与上面描述的早期工作相比,人工设计的特征在*几年的文章中或多或少类似[20]、[29]、[30]、[31]、[32]。在赵等人的一系列工作中 ([30]、[33]、[34]),从每个10×10图像块样本中提取出32维LAB颜色直方图和128维SIFT描述向量,每个样本的步长为5个像素;该特征也用在[35]中。对于一张查询图像(query),采用邻接约束搜索的方法来搜索gallery图像中纬度相*的水*条带。DAS等[36]根据[12]中提出的轮廓,在头部、躯干和腿部应用HSV柱状图。李等 [31]还从图像块中提取局部颜色描述符,但使用高斯变化?[37]对其进行聚合以捕获空间信息,后续工作有[38]。Pedagadi等人[39]在使用PCA进行降维之前从hsv和yuv空间中提取了颜色直方图和图像力矩(moment)。刘等人 [40]提取每个局部图块的hsv柱状图、梯度柱状图和lbp柱状图。为了提高RGB值对光度变化的鲁棒性,Yang等人[41]yinru用于全局行人颜色描述的基于突出颜色名称的颜色描述符(the salient color names based color descriptor , SCNCD),还分析了背景和不同颜色空间的影响。在[20]中,Liao等人提出了局部最大发生率(LOMO)描述符,包括颜色和SILTP直方图。在同一水*条中的bins经过最大池化,并且在对数变换之前建立三尺度金字塔模型。LOMO后来被[42 ],[43 ]所采用,陈等人〔32〕使用了类似的特征集。在[44]中,Zheng等人提出了提取每个局部图块的11维颜色名称描述符[45]并通过词袋库(bow)模型将其聚合成全局向量的方法。在[46]中提出了一种层次高斯特征来描述颜色和纹理线索,该特征通过多个高斯分布对每个区域进行建模。每个分布表示区域内的一个图像块。
除了直接使用low-level的颜色和纹理特征之外,另一个不错的选择是基于属性的特征,可以将其视为low-level的表达。与低层描述符相比,属性对图像翻译更加鲁棒。在[47]中,Layne等人在Viper数据集上注释15个与服装和soft biometrics特征相关的二进制属性。low-level的颜色和纹理特征用于训练属性分类器。属性加权后,生成的向量被集成到SDALF [13]框架中,与其他视觉特征融合。Liu等人[48]改进潜在的Dirichlet分配(LDA)模型,使用带注释的属性过滤掉带噪声的LDA topics。Liu等人 [49]提出无监督地发现一些具有共同属性的行人prototypes,并根据prototypes自适应地确定不同查询人的特征权重。最*的一些作品借用外部数据进行属性学习。在[50]中,Su等人将同一人不同摄像机的二元语义属性嵌入到连续的低阶属性空间中,使得属性向量对匹配的识别性更强。Shi等 [51]建议从现有的样式摄影术数据集中(fashion photography datasets)学习一些属性,包括颜色、纹理和类别标签。这些属性在监视视频中直接用于行人重识别,并获得不错的结果。最*,Li等人[52]收集了一个具有丰富注释的行人属性大规模数据集,以便于属性化的Re-ID方法。
2.1.2 距离度量学习(Distance Metric Learning)
手工设计的行人重识别系统里,距离度量是成功的关键,因为高维视觉特征通常不捕获样本方差下的不变因素。文献[53]对距离尺度学习有详细的介绍,这些尺度学习方法可以分类成监督学习对比非监督学习、全局学习对比局部学习等等。通常情况下,行人重识别问题大部分的工作落在监督、全局的距离度量学习范围内。
全局度量学习的基本思想是将同一类的向量更靠使不同类的距离变大。最常用的是马氏距离(Mahalanobis distance functions):
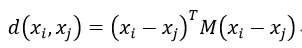
其中, M是半正定矩阵(半正定矩阵是正定矩阵的推广。实对称矩阵A称为半正定的,如果二次型X'AX半正定,即对于任意不为0的实列向量X,都有X'AX≥0.)。
在行人重识别问题中,目前最流行的度量学习方法,即KISSME[55]就是基于上式。在该方法[55]中,对 是否相似的决定被表述为似然比检验(likelihood ratio test)。向量对的差异为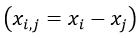 并且差值空间被假设成服从0均值的高斯分布。[55]表明,Mahalanobis距离度量可以从对数似然比检验中自然推导出来,在实践中,将主成分分析(PCA)应用于数据点,以消除尺寸相关性。
并且差值空间被假设成服从0均值的高斯分布。[55]表明,Mahalanobis距离度量可以从对数似然比检验中自然推导出来,在实践中,将主成分分析(PCA)应用于数据点,以消除尺寸相关性。
并且差值空间被假设成服从0均值的高斯分布。[55]表明,Mahalanobis距离度量可以从对数似然比检验中自然推导出来,在实践中,将主成分分析(PCA)应用于数据点,以消除尺寸相关性。
*年来,Hirzer等人[58]建议放宽正性约束,该约束为矩阵m提供了足够的*似值,计算成本更低。chen等人 [38]在马哈拉诺比距离之外添加一个双线性相似性,这样就可以对跨图块相似性(cross-patch similarities)进行建模。在[31 ]中,全局距离度量与局部自适应阈值规则相耦合,该局部自适应阈值规则另外包含 的正交信息。在[59]中,Liao等人建议用一个正半定约束进行保持,并建议对正样本和负样本进行不同的加权。Yang等人 [60]同时考虑图像对之间的差异性和共性,表明不同对的协方差矩阵可以从相似对的协方差矩阵中推断出来,这使得学习过程可扩展到大型数据集。
除了学习距离度量之外,一些工作还关注学习判别子空间(discriminative subspaces)。Liao等[20]提出学习投影到低维子空间的映射w,并以类似于线性判别分析(LDA)的方式解决交叉视图数据,
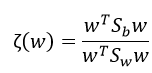
其中,sb和sw分别是类间散射矩阵和类内散射矩阵。然后,使用KISSME在生成的子空间中学习距离函数。为了学习W,Zhang等人[42]进一步使用空Foley-Sammon转换来学习一个判别性的空空间,它满足类内零散射和类间正散射。对于降维,Pedagadi等人[39]依次结合无监督PCA(主成分分析)和监督的局部Fisher判别分析,保留了局部邻域结构。在[28]中,提出了成对约束分量分析(PCCA),它学习线性映射函数,以便能够直接处理高维数据,而ITML和KISSME应先进行降维。在[62]中,熊等人进一步提出了现有两种子空间投影方法的改进版本,即正则化PCCA[28]和内核LFDA[39]。
除了使用马哈拉诺比距离(公式2)的方法外,一些方法还使用其他学习工具,如支持向量机(SVM)或boosting。Prosser等人[25]建议学习一组弱Ranksvms,然后将其组装成更强的Ranker。在[63]中,采用结构支持向量机在决策层组合不同的颜色描述符。在[43]中,张等人学习每个训练标识的特定SVM,并将每个测试图像映射到从其视觉特征推断出的权重向量。Gray和Tao[24]提出使用Adabost算法来选择并将许多不同类型的简单特征组合成一个单一的相似函数。
2.2 基于图像的深度学习系统
基于CNN的深度与学习模型用于行人重识别的开篇之作是[15],[16]。一般来说,在这个community里两类CNN模型最常用:一类是用于图像分类和图像检测的分类模型;另一类是使用图像对(image pairs)[65]或三张图像(triplet)[66]作为输入的siamese模型。深度学习方法的主要瓶颈在于缺乏训练数据。大多数的re-ID数据集都是每个indentity只有2张图像,比如VIPeR[24],因此当前的CNN方法都集中在siamese模型。[15]将输入图像划分成三张带有重叠区的水*子图像,后者经过两个卷积层和一个融合它们的全连接层,然后输出输入图像的一个特征矢量。两个特征矢量之间的相似性用余弦距离计算。[16]的结构设计有所不同,其增加了一个块匹配层(patch matching layer),它通过对两张图像不同水*条带卷积响应进行相乘得到,本质上类似于ACS[30]。随后,Ahmed等人[69]通过计算交叉输入邻域差分特征(cross-input neighborhood difference features)改进了siamese模型,他们将一个输入图像的特征与另一个图像相邻位置的特征进行了比较。[16]用同纬度(水*高度)的子图像的乘积来计算相似性,Ahmed等人[69]则使用差来计算。Wu等人[70]使用小尺寸的卷积核来加深网络,称之为”PersonNet”。 Varior等人[71]将LSTM融进了siamese模型中,使得图像块能被序列化处理从而空间连接可以被记忆,提升了深度特征的判别能力。Varior等人在[72]中提出当一对测试图像被送入网络后,在每一个卷积层之后插入门函数(gating function)来捕捉有效地、细微的模式。该方法在多个benchmarks上都达到了state-of-the-art accuracy,但是缺点也很明显,即输入网络前必须在gallery上先配对图像,在大数据集上显然是time inefficient。同[72]类似,Liu等人在[73]中合并了一个soft attention based model和siamese模型,使得网络能够自适应地注意输入图像对的重要的局部区域。然而这种方法依然受限于计算效率。上述文献都使用图像对,Cheng等人在[74]中设计了一个可以输入三张图像的triplet loss:经过第一卷积层之后,对每个图像分割四个重叠的主体部分,并在fc层中与全局部分融合。Su等人在[75]中提出了三阶段的学习过程,包括使用一个独立的数据集来进行属性预测和在带ID标签的训练集上进行属性triplet loss的训练。
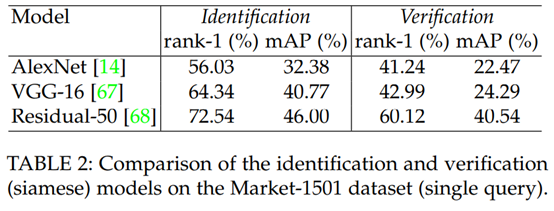
siamese模型的一个缺点是它没有充分利用re-ID标注。siamese模型只需要考虑成对的或者三个的图像。判断一个图像对是否相似(即是否属于同一个indentity)在reID问题中是弱标签(weak label)。另一种可能有效的策略包括使用分类/鉴别(classification/identification)方式,因为其充分利用了re-ID标签。[76]将多个数据集的identities集合起来共同构成训练集,并且softmax loss被用在分类网络上。结合每个全连接层神经元的impact score和基于impact score的域引导(domain guided)的dropout,学习到的通用的embeddings产生了具有竞争力的Re-ID accuracy。在大数据集如PRW[77]和MARS[21]上,不用仔细挑选样本,分类模型实现了不错的表现。然而,identification loss的收敛需要每个ID对应更多的训练用例。改论文提供了一些典型方法在Market-1501[44]数据集上验证(Verification)与确认(Validation)效果的baselines。验证(Verification)是一对一,确认(Validation)一对多。所有的网络都用默认参数,并且在ImageNet数据集上预训练。图像都被缩放到224*224,。学习率初始值是0.001,每个epoch乘以0.1。共36个epoch。可以看到identification模型比Verification模型要表现更优,并且residual-50模型达到了最*几篇文章的同等水*[71],[72],[75]。
上述方法都是用端到端的方式学习深度特征(输入图像),也有其他方法利用low-level的特征作为输入。[79]将low-level的描述符,包括SIFT和颜色直方图,聚合成一个单独的Fisher向量[80]用于每张图像。混合网络在输入的Fisher向量上建立全连接层,并以线性判别分析(LDA)为目标函数,生成具有低类内方差和高类间方差的嵌入(embeddings)。Wu等人[81]提出将fc特征和一个low-level特征向量用concatenate方式合并起来,然后在SoftMax损失层之前再连接另一个fc层。此方法使用手工设计的特征来约束FC特征。
2.3 数据集与评价
2.3.1 数据集
文章发表的较早,此处略过。行人重识别的汇总网站:https://github.com/NEU-Gou/awesome-reid-dataset
2.3.2 评价指标
在评估重识别算法时,通常使用累积匹配特性(Cumulative Matching Characteristics, CMC)曲线。CMC表示查询identity出现在不同大小的候选列表中的概率。无论gallery中有多少个ground truth匹配,CMC计算中只计算第一个匹配。因此,基本上只有当每个query只存在一个ground truth时,CMC才是准确的评估方法。在实践中,当人们更关心返回排名第一的ground truth匹配时,这种度量是可以接受的。

然而为了研究的完整性,当gallery中存在多个ground truth时,Zheng等人[44]建议使用*均精度(mAP)进行评估。其动机是一个完美的重识别系统应该能够将所有的真匹配项返回给用户。可能的情况是两个系统在发现第一个ground truth方面有同样的能力,但具有不同的检索召回能力。在这种情况下,CMC没有足够的识别能力,但MAP有足够的识别能力。因此,MAP与CMC一起用于Market-1501数据集,其中每个查询都存在来自多个摄像头的多个ground truth。随后mAP也被后续文章采用。
2.3.3 历年重识别精度
由于文章发表时间较早,该部分略过。
额外参考:
1. https://bbs.csdn.net/topics/392326863
3. 基于视频的行人重识别
文献中的行人重识别问题一般是单一图像(single shot)进行探索,但*年来,由于数据丰富性的提高,基于视频的RE-ID已经成为一种流行的研究方法。基于视频的re-id问题,与公式1有类似的公式,不同的是图像q和g被两组边界框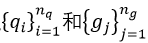 取代,其中
取代,其中  和
和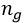 是每个视频序列中各自边界框的数量。边界框特征一样重要,基于视频的方法也特别关注多镜头匹配方案和时间信息的集成。
是每个视频序列中各自边界框的数量。边界框特征一样重要,基于视频的方法也特别关注多镜头匹配方案和时间信息的集成。
3.1 人工设计的系统
最初的尝试是2010年的两次试验[12]、[13],二者都是手工制作的系统。他们基本上使用基于颜色的描述符,还可以选择使用前景分割来检测行人。它们使用与基于图像的重识别方法相似的图像特征,其中主要区别在于匹配函数。如第1.2节所述,两种方法通常将两组边界框特征之间的最小欧几里得距离计算为集合相似性。从本质上讲,这种方法应该被划分为“多镜头”的人识别,其中两组帧之间的相似性起着至关重要的作用。这种多镜头匹配策略后来被 [97]、[98]采用。在[86]中,多镜头图像的协方差特征被用来训练判别boosting模型。在[99]中,surf本地特性用于检测和描述短视频序列中的兴趣点,这些视频序列又在kd树中索引,以加快匹配速度。在[11]中,生成一个时空图来识别用于前景分割的时空稳定区域。然后,随着时间的推移,使用聚类方法计算局部描述,以提高匹配性能。Cong等[100]利用视频序列中的多种几何结构,构建具有基于颜色特征的更紧凑的空间描述符。Karaman等人[101]提议使用条件随机场(CRF)将约束纳入空间和时间域。在[102]中,颜色和选定的人脸图像用于在帧上构建模型,捕获特征外观及其随时间的变化。Karanam等 [103]使用一个人的多个镜头,并将probe feature表达为gallery中同一个人的线性组合。一个identy的多个镜头也可以用来增强身体部位的调整。在[85]中,为了寻找精确的part-to-part对应关系,Cheng等人提出了一种迭代算法,通过改进part检测器,使图像结构在每次迭代后的拟合更加精确。[104]估计了行人姿势,具有相同姿势的帧具有更高的匹配置信度。
上述方法通常基于多个镜头构建外观模型,最*的趋势是在模型中加入时间线索。Wang等[105]提出使用时空描述符重识别行人,其特征包括Hog3D[106]和gait energy image(GEI)[107]。通过设计一个流动能量剖面(flow energy profile, FEP),可以检测步行周期,从而利用局部最小/最大值周围的帧来提取运动特征。最后,通过识别视频排序模型,选择和匹配可靠的时空特征。在[108]中,Liu等人建议将视频序列分解成一系列表示身体动作的单元,这些动作对应于特定action primitives,从中提取Fisher向量,以最终表示人。高等。[109]利用行人的周期性特征,将步行周期划分为若干段,这些段由temporally aligned pooling描述。在[110]中,提出了一种新的时空描述方法,该方法基于密集计算的多向梯度和丢弃短时间内发生的噪声运动(?不知道怎么翻)。
在匹配视频时,距离度量学习也很重要。[111]提出了一种集验证方法,使用transfer ranking来判断query是否匹配属于同一identity的多张图像中的其中一张。在[89]中,提出的局部匹配模型的多镜头扩展使最佳匹配对的距离最小化,并减少了交叉视图转换的次数。在[112]中,Zhu等人提出同时学习视频内、视频间距离度量,使视频表示更紧凑,并区分不同identity的视频。You等 [113]提出了一种top-push距离学习方法,通过选择识别特征来优化视频识别中的顶级(top-rank)匹配。
3.2 基于视频的深度学习系统
在基于视频的Re-ID问题中,数据量通常比基于图像的数据集大,因为每个tracklet包含许多帧(表4)。

基于视频和基于图像的重识别的基本区别在于,对于具有多个图像的每个匹配单元(视频序列),应在视频池化(pooling)后的采用多匹配策略(multi-match strategy)或单匹配策略。多匹配策略在早期研究中被使用[12],[13],它会消耗更高的计算成本,并且在大型数据集上可能存在问题。另一方面,基于池化的方法将帧级特性聚合为一个全局向量,这具有更好的可伸缩性(scalability)。因此,当前基于视频的Re-ID方法通常涉及池化步骤。此步骤可以是最大池化[21]、*均池化[114]或全连接层[115]。在Zheng等人的系统[21]中,时间信息没有被明确捕获;相反,同一个identity的帧被用作训练样本,以训练以Softmax为损失的分类CNN模型。帧特征通过最大池化聚合,从而在三个数据集上产生具有竞争力的准确性。这些方法被证明是有效的,但仍有很多改进空间。关于这一点,Re-ID社区可以借鉴action/event recognition社区的想法。例如,Xu等人[116]建议直接进行CNN特征转移,将caffenet的第5个卷积层中的柱特征聚合成Fisher向量[80]或VLAD[117]。Fernando等人[118]提出了一个learning-to-rank模型来捕捉帧特征是如何随视频时间演变的,这产生了视频时间动态的描述符(video descriptors of video-wide temporal dynamics)。Wang等 [119]在CNN模型中嵌入一个多级编码层,生成不同序列长度的视频描述符。
另一个好的实践方法是在最终表达中注入时间信息 。在手工设计的系统中,Wang等人[105]和Liu等人[108]在iLID-VID和PRID-2011数据集上使用纯时空特征,并获得了具有竞争里的精度。然而,[21]发现MARS数据集上的时空特征没有足够的识别力,因为多个行人在同一台相机下可能具有相似的Walling motion(作者笔误,walking motion?),并且同一个人的运动特征在不同的相机中也可能不一样。在[21]中指出,在大型视频重识别系统中,外观特征至关重要。这就是说,这项调查呼吁人们关注最*的几篇研究[114]、[115]、[120],他们以外观特征(如CNN、color和lbp)为起点,输入RNN网络,以捕捉帧之间的时间流。在[114]中,通过CNN模型从连续视频帧中提取特征,然后通过循环的最后一层进行反馈,从而允许时间步骤(time-steps)之间的信息流。然后使用max或average pooling组合这些功能,以生成视频的外观特征。所有这些结构都被纳入了一个siamese网络。在[120]中使用了类似的体系结构。他们的区别是双重的。首先,在[120]中使用了一种特殊的RNN类型——门循环单元(Gated Recurrent Unit, GRU)。第二,在[114]中采用了识别损失(identification loss),有利于损失收敛和性能提高。这两项工作[114],[120]使用siamese网络进行损失计算,Yan等人[115]和Zheng等[21]则使用标识模型(identification model),将每个输入视频分类为各自的身份标识(identity)。在[115]中,手工制作的低级功能(如颜色和lbp)被送入多个lstm,lstm输出连接到一个softmax层。在行为识别方面,Wu等人[121]提出从视频中提取外观和时空特征,构建混合网络融合这两种特征。本文综述注意到,外观和时空模型的判别组合可能是未来视频重识别研究的有效解决方案。
3.3 数据集和评价
见2.3.1
4 未来:检测、跟踪和行人重识别
4.1前期工作
虽然行人重识别源于多摄像机跟踪,但目前已成为一个独立的研究课题。本文将Re-ID视为一个重要的未来方向,将行人检测和跟踪作为一个场景(事实上却是发展成了一个重要方向)。具体来说是考虑端到端的Re-ID系统,将原始视频作为输入,集成行人检测和跟踪,以及行人重识别为一体。
(到论文发表时)大多数Re-ID工作都基于两个假设:第一,给定行人边界框的gallery;第二,边界框是手工绘制的,即具有完美的检测质量。然而,在实际中,这两个假设并不成立。一方面,gallery大小随探测器阈值的变化而变化。较低的阈值产生更多的边界框(较大的gallery、较高的召回率和较低的准确率),反之亦然。当检测召回率/准确度因阈值不同而发生变化时,重识别的准确性就不能保持稳定。另一方面,当使用行人探测器时,边界框中通常存在检测错误,例如未对准、漏检和假警报。此外,当使用行人追踪器时,跟踪错误可能导致轨迹内的异常帧,即背景或具有不同身份的行人。因此,行人检测和跟踪的质量可能直接影响到Re-ID的准确性,这在Re-ID社区中很少被讨论。下面将回顾一些致力于这个方向的工作。
在解决第二个问题的最初尝试中,几个数据集包括 CUHK03 [16]、Market-1501[44]和MARS [21],这些数据集不假设完美的检测/跟踪输出,更接*实际应用。例如,Li等人[16]表示在CUHK03上,使用检测到的边界框进行重标识的精度低于使用手绘边界框获得的精度。后来的研究也报告了这一观察结果[42],[127]。这些发现与实际应用密切相关。在MARS上,跟踪误差(图8)和探测误差都会出现,但跟踪误差如何影响REID的准确度仍不清楚。

尽管数据集通过引入检测/跟踪错误而取得进展,但它们并未明确评估检测/跟踪如何影响重识别,这为端到端的重识别系统中大量现有工作中如何选择检测器/跟踪器提供了关键的见解。据我们所知,Xu等人[18]在2014提出了关于端到端行人重识别的第一项工作。它们使用术语“commonness”来描述图像边界框与行人的相似性,而术语“uniqueness”则表示gallery边界框与query之间的相似性。commonness和uniqueness在指数函数中的乘积进行融合。这种方法通过消除虚假背景检测的影响而起作用。尽管Xu等人[18]考虑到检测对Re-ID的影响,其局限性在于缺乏全面的基准和对gallery动态问题的考虑。
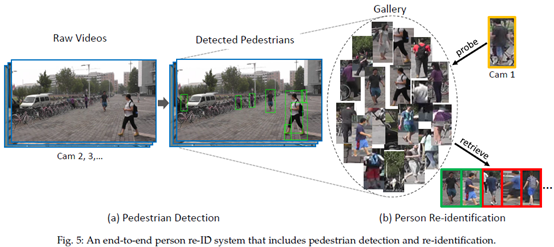
2016年,Xiao等人[128]和Zheng等[77]同时引入基于大规模数据集的端到端REID系统。这两个研究工作都采用原始视频帧和查询边界框作为输入(图5)。首先需要对原始帧执行行人检测,生成的边界框将形成Re-ID gallery。然后就转变成了经典的行人重识别问题。这个过程,在[18],[128]中称为“人员搜索(person search)”,不再局限于Re-ID(图5(b)):它同样关注检测模块(图5(a))。这条流程的一个非常重要的方面是,如果具有相同的一组Re-ID特征,一个更好的行人探测器往往会产生更高的Re-ID精度。在[77],[128]中,person re-identification in the wild, PRW和大规模人员搜索(large-scale person search, LSPS)数据集上分别实现了extensive baselines。另一个有趣的话题是行人检测是否有助于人的重新识别。在[18],[77]中,检测信心被整合到最终的重新识别分数中。在[128]中,行人检测和RE-ID在一个类似于faster R-CNN[129]的CNN模型中被联合考虑,而在[77]中,当在一个预先在R-CNN模型[130]上训练用于行人检测的CNN模型上进行微调时,ID-discriminative embedding (IDE)被证明是优越的。这些方法提供了关于弱标记检测数据如何帮助提高Re-ID准确性的初步见解。
然而,在所谓的“端到端”系统[18]、[77]、[128]中,没有提到行人跟踪,我们也不知道任何现有的工作/数据集涉及到解决跟踪对RE-ID的影响。这项工作将其视为将检测、跟踪和检索集成到一个框架中的“最终”目标,并评估每个模块对整体Re-ID性能的影响。因此,此调查呼吁边界框注释的大型数据集,以用于这三项任务。