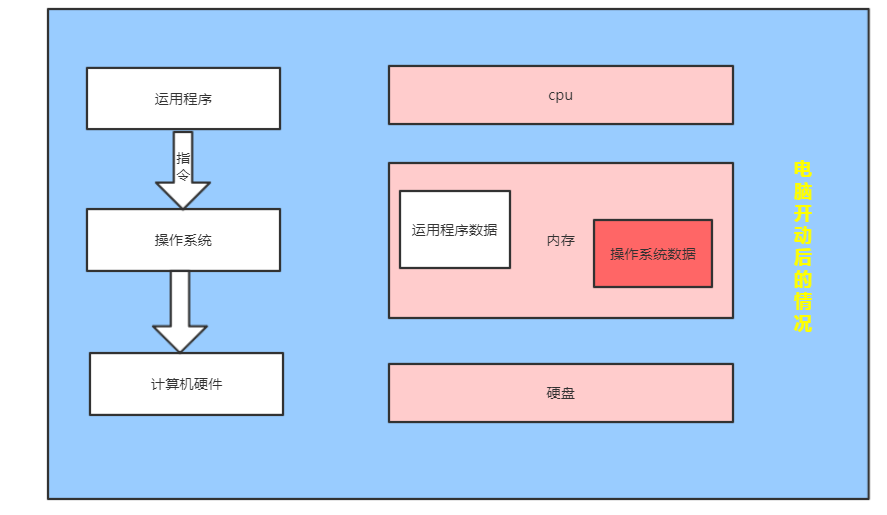
一、计算机简单说明
# 计算机的主要组成部分:cpu, 内存, 硬盘 # cpu :中央处理器,所有的操作都需要cpu完成 # 内存:运行数据的存储地址,关机数据即丢失 # 硬盘 :用于数据存储,关机数据不会丢失
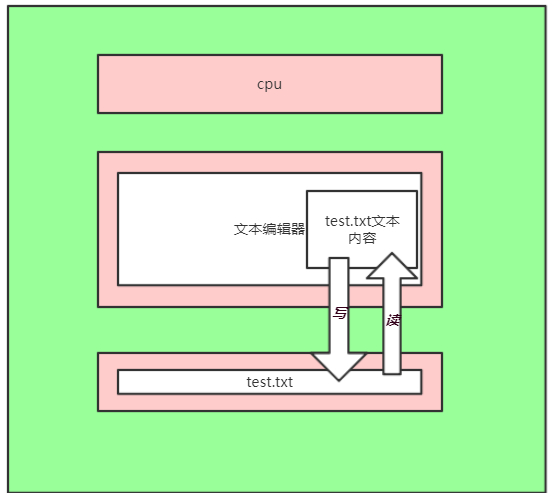
二、文本编辑器读写操作
# 已编写文档举例 # 1、打开文件编辑器 (打开运用程序,将运用程序数据存储值内存) # 2、编写内容 (在内存中编写内容) # 3、保存编写内容至文件 (将内存中的内容保存至硬盘文件) # 4、再次打开文件修改内容 (编辑器将硬盘文件读到内存中)
三、字符编码介绍
3.1 什么是字符编码?
# 通俗的来说,字符编码就是按照某种格式某种规定将字符存储在计算机中。 # 我们都知道计算机只能识别二进制(即0和1)的数字,但是计算机发展到今天我们都有了个人的笔记本,可是我们发现我们的电脑除了0-9的数字外还有中文,英文,这是怎么回事呢? # 很显然我们0和1数字向语言的一个转变的过程,中间一定发生什么。
#字符--------(翻译)---------二进制数 #这个翻译就是一个字符如何对应一个特定的二进制数的表中,这个标准就是字符编码
3.2 字符编码发展史
3.2.1 早期ASCII码
计算机最早由美国人发明的,所以最早的也是美国的ascll码,如图
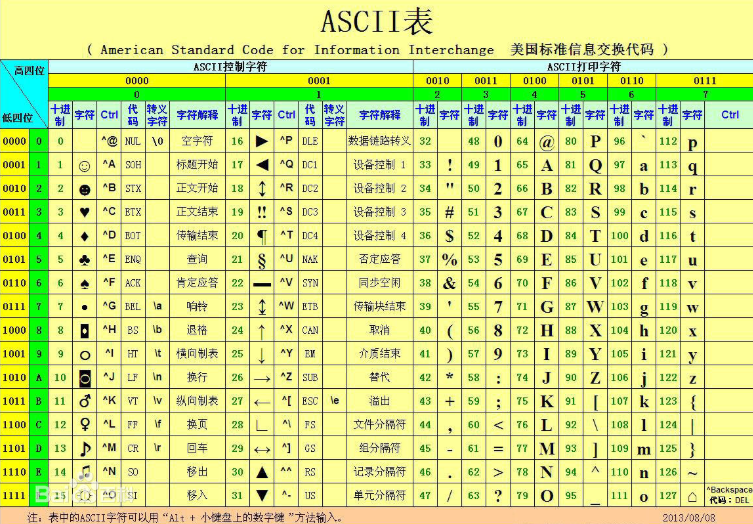
首先看一下高四位和低四位:在这张表中,
字符 0 对应的高四位 0011 低四位 0000 即 00110000
字符 A 对应高四位 0100 低四位 0001 即 01000001
由此可以得出 美国的ascii码一个字符即代表一个8位的二进制数字,即一个字节代表8位二进制数(1bytes = 8bits )
注意:一个四位的二进制可以表示一个一位的16进制数,也就是说一个8位的二进制一个表示成一个2位的16进制,所以你可能看到的都是16进制的
3.2.2 世界各国编码
gb2312:
我们看到美国的ascll码,所有的字符只占了128个(0-127),而8位的二进制一共可以占256个,说明还有128 个字符可以使用。但是很抱歉中文常用汉字就需要有3000多个,很明显如果一个字节(8位二进制数) 根本没有办法满足中国需求。怎么办?
一个不行就用两个。gb2312 为兼容ascll码,第一个字节在0-127内的则为美国字符,如果第一个在127-?(这个不知道是多少,反正保留了很多)中,则为中文字符,一个字节可以表示256 个字符,两个则为256*256 ,所以中文常用3000个汉字用二个字节绰绰有余。
GBK:
GBK是在gb2312的基础上扩展出来的.
外国编码:
中国有中国的编码,外国也一定有自己的编码,例如日本的Shift_JIS,韩国的Euc-kr.
3.2.3 万国码 unicode
一个问题: 日本的软件在日本的电脑上可以正常显示(shift-js编码),如果拿到中国来用就会出现乱码(中国的GBK编码无法解码日本的编码字符) 那怎么办呢?
我们可以在中国的电脑上添加日本的shift-js字符编码不就可以正常显示了吗!!!!很好,确实可以这样做,但是如果你再想编写中文的文本就会出问题,因为中文的字符编码不兼容日本的字符编码(因为高位冲突)
所以我们迫切的需要一个即能够兼容中文又能兼容日文的字符编码-------unicode万国码运用而生.unicode 兼容世界所有的字符.但是每一个字符都占用两个字节,生僻字更多.内存中使用该字符编码
3.2.4 可变成长编码utf-8(目前最常用的字符编码,被各国所介绍)
unicode 的出现解决了乱码问题,但有一个新问题,如果你的文本如果通篇都是英文,那么使用unicode 就会比ascii码多一倍的空间,本着节约的原则又出现了“可变长编码utf-8” utf-8 支持万国文字.(unicode 兼容utf-8)
# utf-8:
# 英文占一个字节 # 中文占三个字节
3.3 总结
#总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
四、字符编码运用之文本编辑器
4.1 打开txt文件的三个阶段
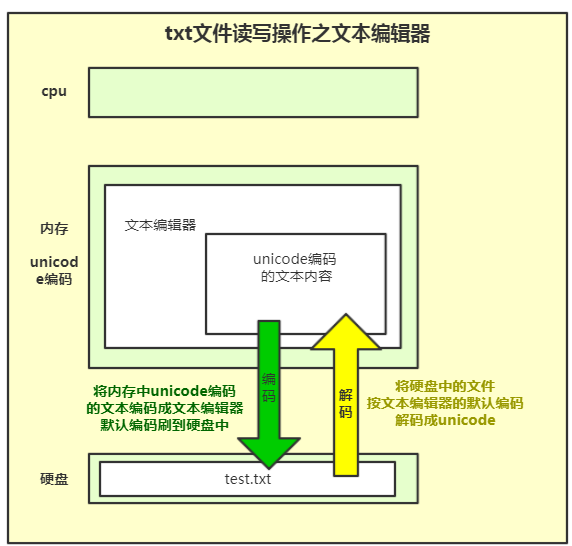
# 阶段一:打开文本编辑器 # 阶段二:将硬盘文件内容已默认的编码转化成unicode万国码存储到内存中 # 阶段三 :文本编辑器中显示内存文本内容
4.2 保存txt文件的二个阶段
# 阶段一: 将内存中的unicode编码的字符转成文本编辑器默认的编码字符 # 阶段二: 转化后刷到硬盘中去
4.3 图解读写txt文件操作
4.4 乱码根源


# 在万国码unicode 出现之前,乱码问题一直存在,但今天我们任然还会在无意识间发现一些中文乱码。 # 例如我们在mac电脑上面编写一个txt的文件,但是拿到windows电脑上就乱了。 # 又例如我们在linux终端上执行文件,可以windows终端上就各种乱码问题 # 再例如我们在windows的文本编辑器上写了中韩两种语言,保存再打开时,中文可以正常显示,韩文确实乱码,这又事什么原因呢? # 其实说那么多,上面的文本编辑关于字符编码解码的过程,你心里应该知道为什么了。 # 原因无外乎两种: # 1、内存中unicode字符 在编码成 其他字符往 硬盘中存的时候,没有找到该字符在另一字符编码中的对应的位置。所以造成了电脑无法识别乱存了一个???的字符 # 2、硬盘文件向内存解码的过程中,原本硬盘文件中的内容是例如是utf-8,但在解码时使用gbk进行解码操作,导致unicode 无法识别,进而出现了乱民问题 # 总结: # 要想保证不乱码: # 1、存时保证内容在默认编码中有对应位置 # 2、读时保证文本的默认编码与存时的编码一致
五、字符编码之python运用
5.1 执行python文件的三个阶段
#已 python test.py 为例 # 阶段一:启动python解释器 # 阶段二:将test.py 文件内容转成unicode 字符编码,加载到内存中 # 阶段三 :python 解释执行内存中的文件内容 # 注意: # 阶段二,test.py 在解码成unicode 编码时,需要按照某种字符解码。 # python2 默认 ascii # python3 默认 utf-8 # 如果文件头部分有coding:XXX ,则按照XXX解码,如果没有则按照默认的进行解码操作 # 阶段三,执行代码的过程中,如x='jmz', python 运用程序会开辟两个空间,一个是名称空间,用来存储 x 和'jmz'的内存指向地址,一个是内存空间存储'jmz'。python2和python3 中'jmz' 在内存中的字符编码是不一样的。下面会说明。
5.2 执行test.py文件--图解
1、文本编辑器写一个test.py代码
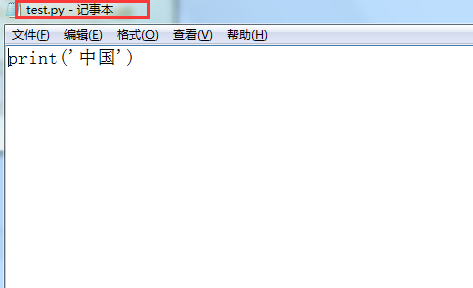
2、python3 解释器执行test.py文件

出现了错误:utf-8 编码无法解析test.py 文件
原因:windows默认是gbk 编码,所以我们要在文件的开头写一个# coding:gbk 就可以了(python解释器会通过文件头来确定使用哪种编码解码文件内容)
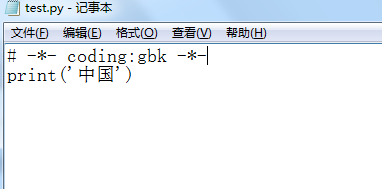
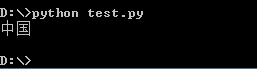
3、在windows终端执行test.py 文件就可以正常显示文字
5.3 python2 与python3 的区别
# python2:默认ascii码 # python3:默认utf-8 #在读取文件时会使用默认编码解码文件内容,文件头如果定义了编码,就使用文件头的编码解码编码。 # python中开辟内存空间时,会将内存中的unicode变量,编码成默认的编码进行存储。 # 也就是 python2 使用ascii 编码存储 # python 3 则不同,它没有编码过程,而是直接以unicode 进行储存的。所以无需编码,解码

5.4 补充
# 1、强烈建议使用python3 # 如果使用python2 请一定要在文件头写上# coding:utf-8, 非英文字符,一定要在变量前加u 如下 name = u'中国人' # 表示已unicode 形式存入内存空间。 # 2、字符编码的转换, # python3 可直接转化成其他编码(因为内存空间中本身存储的就是unicode) # python2 如果变量前+u了,则与python3 一致,如果没有,则需要解码成unicode在编码成其他编码 (python2中内存空间编码不一定是unicode编码字符)