本文由 伯乐在线 - yanhaijing 翻译。未经许可,禁止转载!
英文出处:flippinawesome。欢迎加入翻译小组。
在JavaScript中,可以通过两种方式创建数组,Array构造函数和 [] 便捷方式, 其中后者为首选方法。数组对象继承自Object.prototype,对数组执行typeof操作符返回‘object’而不是‘array’。然而执行[] instanceof Array返回true。此外,还有类数组对象使问题更复杂,如字符串对象,arguments对象。arguments对象不是Array的实例,但却有个length属性,并且值能通过索引获取,所以能像数组一样通过循环操作。
在本文中,我将重温一些数组原型的方法,并探索这些方法的用法。
- 循环.forEach
- 断言.some和.every
- .join和.concat的区别
- 栈和队列.pop,.push,.shift和.unshift
- 模型映射.map
- 查询.filter
- 排序.sort
- 计算.reduce和.reduceRight
- 复制.slice
- 万能的.splice
- 查找.indexOf
- in操作符
- 走进.reverse
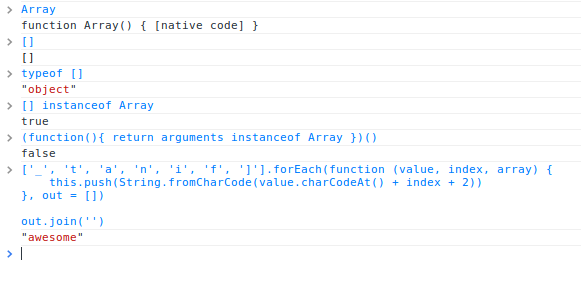
如果你想测试上面的例子,您可以复制并粘贴到您的浏览器的控制台中。
循环.forEach
这是JavaScript原生数组方法中最简单的方法。不用怀疑,IE7和IE8不支持此方法。
forEach方法需要一个回调函数,数组内的每个元素都会调用一次此方法,调用时会传入的三个参数如下:
- value 当前操作的数组元素
- index 当前操作元素的数组索引
- array 当前数组的引用
此外,可以传递可选的第二个参数,作为每个调用函数的上下文(this)。
|
1
2
3
4
5
6
|
['_', 't', 'a', 'n', 'i', 'f', ']'].forEach(function (value, index, array) { this.push(String.fromCharCode(value.charCodeAt() + index + 2))}, out = [])out.join('')// <- 'awesome' |
.join函数我将在下文提及,上面例子中,它将数组中的不同元素拼接在一起,类似于如下的效果:out[0] + ” + out[1] + ” + out[2] + ” + out[n]。
我们不能用break中断forEach循环,抛出异常是不明智的方法。幸运的是,我们有其他的方法中断操作。
断言.some和.every
如果你曾经用过.NET的枚举,这些方法的名字和.Any(x => x.IsAwesome) 和 .All(x => x.IsAwesome)非常相似。
这些方法和.forEach类似,需要一个包含value,index,和array三个参数的回调函数,并且也有一个可选的第二个上下文参数。MDN对.some的描述如下:
some将会给数组里的每一个元素执行一遍回调函数,直到有一个回调函数返回true为止。如果找到目标元素,some立即返回true,否则some返回false。回调函数只对已经指定值的数组索引执行;它不会对已删除的或未指定值的元素执行。
|
1
2
3
4
5
6
7
8
9
10
11
|
max = -Infinitysatisfied = [10, 12, 10, 8, 5, 23].some(function (value, index, array) { if (value > max) max = value return value < 10})console.log(max)// <- 12satisfied// <- true |
注意,当回调函数的value < 10 条件满足时,中断函数循环。.every的工作行为类似,但中断的条件是回调函数返回false而不是true。
.join和.concat的区别
.join方法经常和.concat混淆。.join(分隔符)方法创建一个字符串,会将数组里面每个元素用分隔符连接。如果没有提供分隔符,默认的分隔符为“,”。.concat方法创建一个新数组,其是对原数组的浅拷贝(注意是浅拷贝哦)。
- .concat 的标志用法:array.concat(val, val2, val3, valn)
- .concat 返回一个新数组
- array.concat()没有参数的情况下,会返回原数组的浅拷贝
浅拷贝意味着新数组和原数组保持相同的对象引用,这通常是好事。例如:
|
1
2
3
4
5
6
7
8
9
|
var a = { foo: 'bar' }var b = [1, 2, 3, a]var c = b.concat()console.log(b === c)// <- falseb[3] === a && c[3] === a// <- true |
栈和队列.pop,.push,.shift和.unshift
每个人都知道向数组添加元素用.push。但你知道一次可以添加多个元素吗?如下[].push(‘a’, ‘b’, ‘c’, ‘d’, ‘z’)。
.pop方法和.push成对使用,它返回数组的末尾元素并将元素从数组移除。如果数组为空,返回void 0(undefined)。使用.push和.pop我们能轻易模拟出LIFO(后进先出或先进后出)栈。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
function Stack () { this._stack = []}Stack.prototype.next = function () { return this._stack.pop()}Stack.prototype.add = function () { return this._stack.push.apply(this._stack, arguments)}stack = new Stack()stack.add(1,2,3)stack.next()// <- 3 |
相反,我们可以用.unshift 和 .shift模拟FIFO(先进先出)队列。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
function Queue () { this._queue = []}Queue.prototype.next = function () { return this._queue.shift()}Queue.prototype.add = function () { return this._queue.unshift.apply(this._queue, arguments)}queue = new Queue()queue.add(1,2,3)queue.next()// <- 1 |
用.shift或.pop能很容易遍历数组元素,并在操作过程中清空数组。
|
1
2
3
4
5
6
7
8
|
list = [1,2,3,4,5,6,7,8,9,10]while (item = list.shift()) { console.log(item)}list// <- [] |
模型映射.map
map 方法会按顺序给原数组中的每个元素(必须有值)都调用一次 callback 函数.callback 每次执行后的返回值组合起来形成一个新数组. callback函数只会在有值的索引上被调用; 那些从来没被赋过值或者使用delete删除的索引则不会被调用。——MDN
Array.prototype.map方法和上面我们提到的.forEach,.some和.every有相同的参数:.map(fn(value, index, array), thisArgument)。
|
1
2
3
4
5
6
7
8
|
values = [void 0, null, false, '']values[7] = void 0result = values.map(function(value, index, array){ console.log(value) return value})// <- [undefined, null, false, '', undefined × 3, undefined] |
undefined × 3 值解释.map不会在没被赋过值或者使用delete删除的索引上调用,但他们仍然被包含在结果数组中。map在遍历或改变数组方面非常有用,如下所示:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
// 遍历[1, '2', '30', '9'].map(function (value) { return parseInt(value, 10)})// 1, 2, 30, 9[97, 119, 101, 115, 111, 109, 101].map(String.fromCharCode).join('')// <- 'awesome'// 一个映射新对象的通用模式items.map(function (item) { return { id: item.id, name: computeName(item) }}) |
查询.filter
filter对每个数组元素执行一次回调函数,并返回一个由回调函数返回true的元素 组成的新数组。回调函数只会对已经指定值的数组项调用。
用法例子:.filter(fn(value, index, array), thisArgument)。把它想象成.Where(x => x.IsAwesome) LINQ expression(如果你熟悉C#),或者SQL语句里面的WHERE。考虑到.filter仅返回callback函数返回真值的值,下面是一些有趣的例子。没有传递给回调函数测试的元素被简单的跳过,不会包含进返回的新数组里。
|
1
2
3
4
5
6
7
8
9
|
[void 0, null, false, '', 1].filter(function (value) { return value})// <- [1][void 0, null, false, '', 1].filter(function (value) { return !value})// <- [void 0, null, false, ''] |
排序.sort(比较函数)
如果未提供比较函数,元素会转换为字符串,并按字典序排序。例如,在字典序里,“80”排在“9”之前,但实际上我们希望的是80在9之后(数字排序)。
像大部分排序函数一样,Array.prototype.sort(fn(a,b))需要一个包含两个测试参数的回调函数,并且要产生以下三种返回值之一:
- 如果a在b前,则返回值小于零(< 0)
- 如果a和b是等价的,则返回值等于零(=== 0)
- 如果a在b后,则返回值大于零(> 0)
|
1
2
3
4
5
6
7
|
[9,80,3,10,5,6].sort()// <- [10, 3, 5, 6, 80, 9][9,80,3,10,5,6].sort(function (a, b) { return a - b})// <- [3, 5, 6, 9, 10, 80] |
计算.reduce和.reduceRight
首先reduce函数不是很好理解,.reduce从左到右而.reduceRight从右到左循环遍历数组,每次调用接收到目前为止的部分结果和当前遍历的值,整个操作最终返回一个合计的返回值。
两种方法都有如下典型用法:.reduce(callback(previousValue, currentValue, index, array), initialValue)。
previousValue是上一次被调用的回调函数的返回值,initialValue是开始时previousValue被初始化的值。currentValue 是当前被遍历的元素值,index是当前元素在数组中的索引值。array是对调用.reduce数组的简单引用。
一个典型的用例,使用.reduce的求和函数。
|
1
2
3
4
5
6
7
8
|
Array.prototype.sum = function () { return this.reduce(function (partial, value) { return partial + value }, 0)};[3,4,5,6,10].sum()// <- 28 |
上面提到如果想把数组连成一个字符串,可以使用.join。当数组的值是对象的情况下,除非对象有能返回其合理值的valueof或toString方法,否则.join的表现和你期望的不一样。然而,我们可以使用.reduce作为对象的字符串生成器。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
function concat (input) { return input.reduce(function (partial, value) { if (partial) { partial += ', ' } return partial + value }, '')}concat([ { name: 'George' }, { name: 'Sam' }, { name: 'Pear' }])// <- 'George, Sam, Pear' |
复制.slice
和.concat类似,调用.slice缺省参数时,返回原数组的浅拷贝。slice函数需要两个参数,一个是开始位置和一个结束位置。
Array.prototype.slice能被用来将类数组对象转换为真正的数组。
|
1
2
|
Array.prototype.slice.call({ 0: 'a', 1: 'b', length: 2 })// <- ['a', 'b'] |
除此之外,另一个常见用途是从参数列表中移除最初的几个元素,并将类数组对象转换为真正的数组。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
function format (text, bold) { if (bold) { text = '<b>' + text + '</b>' } var values = Array.prototype.slice.call(arguments, 2) values.forEach(function (value) { text = text.replace('%s', value) }) return text}format('some%sthing%s %s', true, 'some', 'other', 'things')// <- <b>somesomethingother things</b> |
万能的.splice
.splice是我最喜欢的原生数组函数之一。它允许你删除元素,插入新元素,或在同一位置同时进行上述操作,而只使用一个函数调用。注意和.concat和.slice不同的是.splice函数修改原数组。
|
1
2
3
4
5
6
7
8
|
var source = [1,2,3,8,8,8,8,8,9,10,11,12,13]var spliced = source.splice(3, 4, 4, 5, 6, 7)console.log(source)// <- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12 ,13]spliced// <- [8, 8, 8, 8] |
你可能已经注意到,它也返回被删除的元素。这在你想遍历数组的某一个区段并且删除时派上用场。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
var source = [1,2,3,8,8,8,8,8,9,10,11,12,13]var spliced = source.splice(9)spliced.forEach(function (value) { console.log('removed', value)})// <- removed 10// <- removed 11// <- removed 12// <- removed 13console.log(source)// <- [1, 2, 3, 8, 8, 8, 8, 8, 9] |
查找.indexOf
通过.indexOf,我们可以查找数组元素的位置。如果没有匹配元素则返回-1。我发现我用的很多的一个模式是连续比较,例如a === ‘a’ || a === ‘b’ || a === ‘c’,或者即使只有两个结果的比较。在这种情况下,你也可以使用.indexOf,像这样:['a', 'b', 'c'].indexOf(a) !== -1。
注意,对于对象来说,只有指向同一个对象的引用才能被识别出。第二个参数是开始查询的起始位置。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
var a = { foo: 'bar' }var b = [a, 2]console.log(b.indexOf(1))// <- -1console.log(b.indexOf({ foo: 'bar' }))// <- -1console.log(b.indexOf(a))// <- 0console.log(b.indexOf(a, 1))// <- -1b.indexOf(2, 1)// <- 1 |
如果你想从后向前搜索,.lastIndexOf能派上用场。
in操作符
在面试中新手容易犯的错误是混淆.indexOf和in操作符,如下:
|
1
2
3
4
5
6
7
|
var a = [1, 2, 5]1 in a// <- true, 但 是因为 2!5 in a// <- false |
问题的关键是in操作符通过检索对象的键(key)来寻值,而不是搜索值。当然,这在性能上比.indexOf快得多。
|
1
2
3
4
|
var a = [3, 7, 6]1 in a === !!a[1]// <- true |
in操作符类似于将键值转换为布尔值。!!表达式通常被开发者用来双重取非一个值(转化为布尔值)。实际上相当于强制转换为布尔值,迅速地将任何为真的值被转为true,任何为假的值被转换为false。
走进.reverse
这方法将数组中的元素翻转并替换原来的元素。
|
1
2
3
4
|
var a = [1, 1, 7, 8]a.reverse()// [8, 7, 1, 1] |
和复制不同的是,数组本身被更改。在以后的文章中我将展开对这些概念的理解,去看看如何创建一个类似 _ 的库,如Underscore或Lo-Dash。