概述:

1 随机数的产生

2 二项分布随机数据的产生

1 clear all; 2 r=binornd(10,0.5) 3 R=binornd(10,0.5,3,4) %产生一个3*4的矩阵
3 泊松分布

1 clear all; 2 r=poissrnd(8) %泊松分布 3 R=poissrnd(8,4,4) %产生一个4*4的矩阵
3 指数分布随机数据的产生

1 clear all; 2 r=exprnd(10) %指数分布 3 R=exprnd(8,4,4) %产生一个4*4的矩阵
4 均匀分布随机数据的产生

1 clear all; 2 r=unifrnd(1,3) %均匀分布 3 R1=unifrnd(1,3,4,4) %产生一个4*4的矩阵 4 R2=unifrnd(1,3,[4 4])
1 clear all; 2 r=unidrnd(10) %离散型均匀分布 3 R1=unidrnd(8,4,4) %产生一个4*4的矩阵 4 R2=unidrnd(8,[4 4])
5 正态分布随机数据的产生

1 clear all; 2 %标准正态分布 3 r=normrnd(0,1) 4 R1=normrnd(0,1,[3 5]) %产生一个3*5的矩阵 5 R2=normrnd(2,4,[3 5])
6 常见离散分布的概率密度函数


1 clear all; 2 x=1:30; 3 y=binopdf(x,300,0.05); 4 figure; 5 plot(x,y,'r*'); 6 title('二项分布(n=300,p=0.05)');
1 clear all; 2 x=1:50; 3 y=poisspdf(x,25); %泊松分布 4 figure; 5 plot(x,y,'r+'); 6 title('泊松分布');
1 clear all; 2 x=1:20; 3 y=geopdf(x,0.5); %几何分布 4 figure; 5 plot(x,y,'rx'); 6 title('几何分布');
1 clear all; 2 n=20; 3 x=1:n; 4 y=unidpdf(x,n); %均匀分布(离散) 5 figure; 6 plot(x,y,'ro'); 7 title('均匀分布(离散)');
7 常见连续分布的概率密度函数

1 clear all; 2 x=-5:0.1:10; 3 y=unifpdf(x,0,5); %均匀分布(连续) 4 figure; 5 plot(x,y,'r:'); 6 title('均匀分布(连续)');
1 clear all; 2 x=0:0.1:20; 3 y=exppdf(x,5); %指数分布 4 figure; 5 plot(x,y,'r:'); 6 title('指数分布');
1 clear all; 2 x=-8:0.1:8; 3 y1=normpdf(x,0,1); %标准正态分布 4 y2=normpdf(x,2,2); %非标准正态分布 5 figure; 6 plot(x,y1,x,y2,':'); 7 legend('标准正态分布','非标准正态分布'); 8 x1=-4:0.1:8; 9 y3=normpdf(x1,2,1); %SIGMA=1 10 y4=normpdf(x1,2,2); %SIGMA=2 11 y5=normpdf(x1,2,3); %SIGMA=3 12 figure; 13 plot(x1,y3,'r-',x1,y4,'b:',x1,y5,'k--'); 14 legend('SIGMA=1','SIGMA=2','SIGMA=3'); 15 y6=normpdf(x1,0,1.5); %MU=0 16 y7=normpdf(x1,2,1.5); %MU=2 17 y8=normpdf(x1,4,1.5); %MU=4 18 figure; 19 plot(x1,y6,'r-',x1,y7,'b:',x1,y8,'k--'); 20 legend('MU=0','MU=2','MU=4');
8 三大抽样分布的概率密度函数

1 clear all; 2 x=0:0.1:15; 3 y1=chi2pdf(x,4); %卡方分布n=4 4 y2=chi2pdf(x,8); %卡方分布n=8 5 figure; 6 hold on; 7 plot(x,y1); 8 plot(x,y2,':'); 9 legend('n=4','n=8'); 10 title('卡方分布');
1 clear all; 2 x=-7:0.1:7; 3 y1=tpdf(x,3); %t分布(n=3) 4 y2=tpdf(x,30); %t分布(n=30) 5 figure; 6 plot(x,y1,'r:',x,y2,'b-'); 7 legend('n=3','n=30'); 8 title('t分布');
1 clear all; 2 x=0.1:0.1:8; 3 y=fpdf(x,5,10); %F分布 4 figure; 5 plot(x,y,'r:'); 6 title('F分布(m=5,n=10)');
9 随机变量的数字特征

9.1 平均值和中位数

1 clear all; 2 A=[1 2 3 4;2 0 1 4] 3 m1=mean(A) %对列元素求算术平均值 4 m2=mean(A,2) %对行元素求算术平均值
9.2忽略NaN(非数)计算算术平均根

1 clear all; 2 A=[1 2 nan 4;2 nan 1 nan] 3 m1=mean(A) 4 m2=nanmean(A) %对列元素求算术平均值 5 m3=nanmean(A,2) %对行元素求算术平均值
9.3 几何平均数
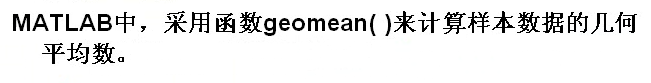
1 clear all; 2 A1=[1 2 3 4] 3 m1=geomean(A1) %向量的几何平均数 4 A2=[1 2 3;2 3 4] 5 m2=geomean(A2) %列元素的几何平均数 6 m3=geomean(A2,2) %行元素的几何平均数
9.4 中位数

1 clear all; 2 A1=[1 2 3 4] 3 m1=median(A1) %向量的中位数 4 A2=[1 2 3;2 3 4;4 1 8] 5 m2=median(A2) %列元素的中位数 6 m3=median(A2,2) %行元素的中位数
10 数据的排序

1 clear all; 2 X=[1 3 4;8 3 5;2 7 4] 3 y1=sort(X) %按列由小到大排序 4 y2=sort(X,2) %按行由小到大排序 5 y3=sort(X,1,'descend') %按列由大到小排序 6 [Y,I]=sort(X) 7 [Y,I]=sort(X,2)
1 clear all; 2 X=[1 3 4;8 3 5;2 7 4] 3 y1=sortrows(X) %按行排序 4 y2=sort(X,2) %按指定的列排序 5 [Y,I]=sort(X)
1 clear all; 2 X1=[1 3 4 10 3 5] 3 y1=range(X1) %向量 4 X2=[1 3 5;2 4 6;8 4 3] 5 y2=range(X2) %矩阵 6 y3=range(X2,2)
1 clear all; 2 X1=[2 5 4 12 3 15] 3 y1=minmax(X1) %向量 4 X2=[1 3 5;2 4 6;8 4 3] 5 y2=minmax(X2) %矩阵
11 期望和方差

1 clear all; 2 X1=rand(1,8) %向量 3 y=mean(X1) 4 X2=rand(4,7) %矩阵 5 Y=mean(X2,2)
1 clear all; 2 A=rand(1,8) %向量 3 y=var(A) 4 B=rand(3,5) %矩阵 5 Y1=var(B) 6 Y2=var(B,1) 7 W=[0.1 0.2 0.3] %系数 8 Y3=var(B,W)
1 clear all; 2 A=[2 3 4 1;1 2 3 2;8 1 2 3] 3 %计算标准差 4 y1=std(A) 5 y2=std(A,0) 6 y3=std(A,1) 7 y4=std(A,1,2)
12 常见分布的期望和方差

1 clear all; 2 n1=100; 3 p1=0.3; 4 [m1,v1]=binostat(n1,p1) 5 n2=logspace(1,4,4) 6 [m2,v2]=binostat(n2,1./n2)
1 clear all; 2 a1=1; 3 b1=5; 4 [m1,v1]=unifstat(a1,b1) 5 a2=1:5; 6 b2=2.*a2; 7 [m2,v2]=unifstat(a2,b2)
1 clear all; 2 n1=2; 3 n2=3; 4 [m1,v1]=normstat(n1,n2) 5 n3=1:4; 6 [m2,v2]=normstat(n3'*n3,n3'*n3)
1 clear all; 2 mu1=2; 3 [m1,v1]=expstat(mu1) 4 mu2=1:5; 5 [m2,v2]=expstat(mu2)
1 clear all; 2 n1=4; 3 [m1,v1]=tstat(n1) 4 n2=5:10; 5 [m2,v2]=tstat(n2)
1 clear all; 2 n1=6; 3 n2=8; 4 [m1,v1]=fstat(n1,n2) 5 n3=5:10; 6 n4=7:12; 7 [m2,v2]=fstat(n3,n4)
13 协方差和相关系数

1 clear all; 2 X1=rand(1,5) 3 c1=cov(X1) 4 X2=rand(1,5) 5 c2=cov(X2) 6 c3=cov(X1,X2) 7 X3=rand(4,4) 8 c4=cov(X3) 9 c5=cov(X3(:,1))
1 clear all; 2 X=[1 2 3;3 4 6;7 4 2] 3 [R1,P1]=corrcoef(X) 4 x=[1 2 3 5 3 2]; 5 y=[2 3 5 3 1 9]; 6 R2=corrcoef(x,y)
14 参数估计

14.1 点估计

14.2 区间估计

1 clear all; 2 X=unifrnd(2,8,20,3) 3 [a,b,aci,bci]=unifit(X,0.05)
1 clear all; 2 X=exprnd(5,20,4) 3 [parmhat1,parmci1]=expfit(X,0.05) 4 [parmhat2,parmci2]=expfit(X,0.01)
1 clear all; 2 X=betarnd(7,5,100,1); 3 [phat,pci]=betafit(X,0.02)
1 clear all; 2 X=normrnd(10,2,20,3) 3 [mu1,sigma1,muci1,sigmaci1]=normfit(X,0.05) 4 [mu2,sigma2,muci2,sigmaci2]=normfit(X,0.01)
15 假设检验

15.1 方差已知时正态总体均值的假设检验

1 clear all; 2 X=[490 513 514 513 511 499 515 512 491]; 3 [H1,P1,CI1,STATS1]=ztest(X,500,10,0.05,0) %ALPHA=0.05 4 [H2,P2,CI2,STATS2]=ztest(X,500,10,0.1,0) %ALPHA=0.1
15.2 方差未知时正态总体均值的假设检验

1 clear all; 2 X=[300 324 305 290 295 291 310 315]; 3 [H,P,CI,STATS]=ttest(X,305,0.05,-1) %ALPHA=0.05
15.3 如果两个正态分布均值差的检验

1 clear all; 2 X=[302 304 305 310 320 299 298 301 315 313]; 3 Y=[305 314 320 315 313 308 318 325 301 312]; 4 [H,P,CI,STATS]=ttest2(X,Y,0.05,-1) %ALPHA=0.05
16 方差分析

16.1 单因素方差分析

1 clear all; 2 X=[62 75 62 79 80;67 85 69 64 70;... 3 45 79 55 69 79;52 76 65 70 86] 4 group=['方案1';'方案2';'方案3';'方案4';'方案5'] 5 [p,a,s]=anova1(X,group)
16.2 双因素方差分析

1 clear all; 2 X=[30 36 35.5 38.5;33.5 36.5 38 39.5;36 37.5 39.5 43]; 3 [p,a,s]=anova2(X)
17 统计图绘制
14.1 正整数的频率表

1 clear all; 2 X=[37.6 47.3;38.2 46.8;45.1 42.4;43.8 40.8]; 3 [p,a,s]=anova2(X,2)
14.2 最小二乘拟合直线

14.3 正态分布概率图

1 clear all; 2 %参数正态分布的随机数据 3 X=normrnd(0,1,100,1) 4 figure 5 H=normplot(X)