在机器学习领域通常会根据实际的业务场景拟定相应的不同的业务指标,针对不同机器学习问题如回归、分类、排序,其评估指标也会不同。
一、下面介绍常见的一些概念
表 1 常见的二分类混淆矩阵
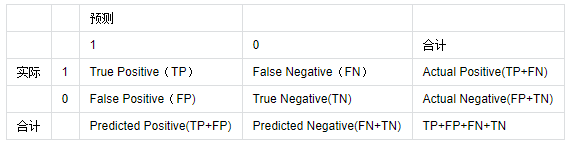
从这个表格中可以引出一些其它的评价指标:
- ACC:classification accuracy,描述分类器的分类准确率
计算公式为:ACC=(TP+TN)/(TP+FP+FN+TN)
- BER:balanced error rate
计算公式为:BER=1/2*(FPR+FN/(FN+TP))
- TPR:true positive rate,描述识别出的所有正例占所有正例的比例
计算公式为:TPR=TP/ (TP+ FN)
- FPR:false positive rate,描述将负例识别为正例的情况占所有负例的比例
计算公式为:FPR= FP / (FP + TN)
- TNR:true negative rate,描述识别出的负例占所有负例的比例
计算公式为:TNR= TN / (FP + TN)
- PPV:Positive predictive value
计算公式为:PPV=TP / (TP + FP)
- NPV:Negative predictive value
计算公式:NPV=TN / (FN + TN)
其中TPR即为敏感度(sensitivity),TNR即为特异度(specificity)。
二、基于混淆矩阵的计算示意图

三、实例解释
下面以医学中糖尿病人的筛查为例对敏感度和特异度进行解释。在这个例子中,我们只将病人血糖水平作为判断是否患有糖尿病的指标。下图为正常人和糖尿病患者血糖水平的统计图:
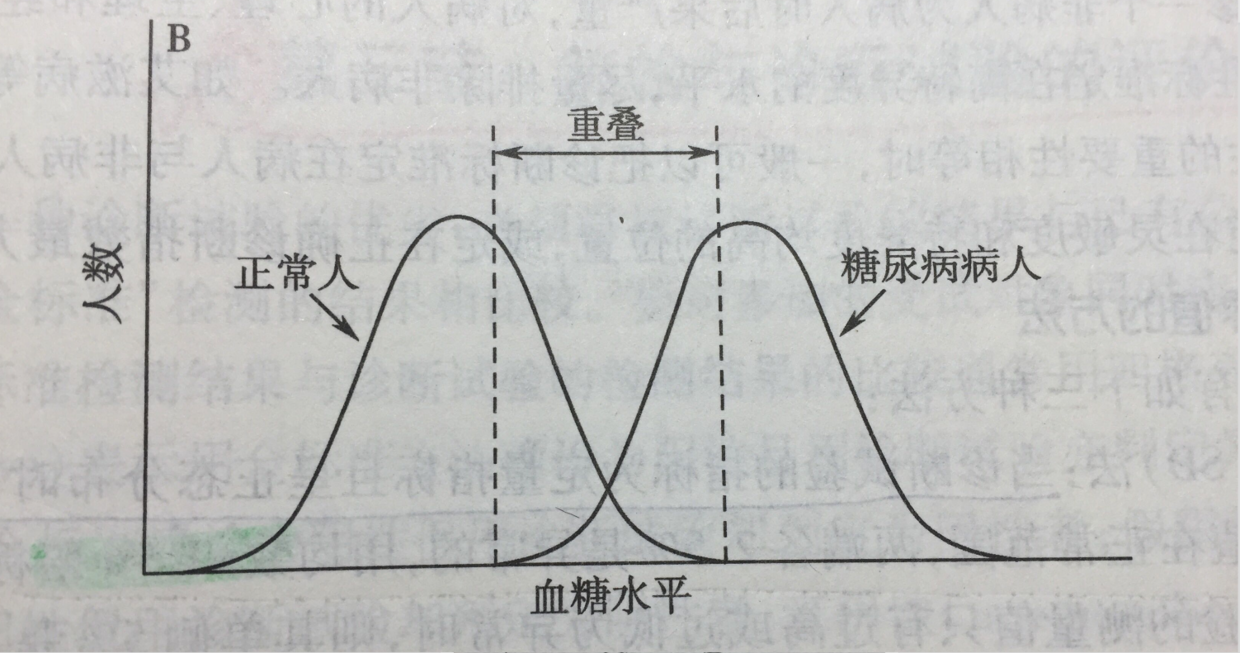
我们发现两个人群中有重叠的部分,这个时候判定标准定的不同,得到的结果就会不同。
如果我们把标准定在最左边的虚线上,则低于这条线的为正常人,高于这条线的包含了两类人:正常人和糖尿病患者。这种时候就是灵敏度最高的时候,即实际有病而被诊断出患病的概率,没有放过一个患病的人。如果将标准定在最右边的虚线上,则是特异度最高的时候,即实际没病而被诊断为正常的概率,没有冤枉一个没病的人。
终上所述,敏感度高=漏诊率低,特异度高=误诊率低。
理想情况下我们希望敏感度和特异度都很高,然而实际上我们一般在敏感度和特异度中寻找一个平衡点,这个过程可以用ROC(Receiver Operating Characteristic)曲线来表示: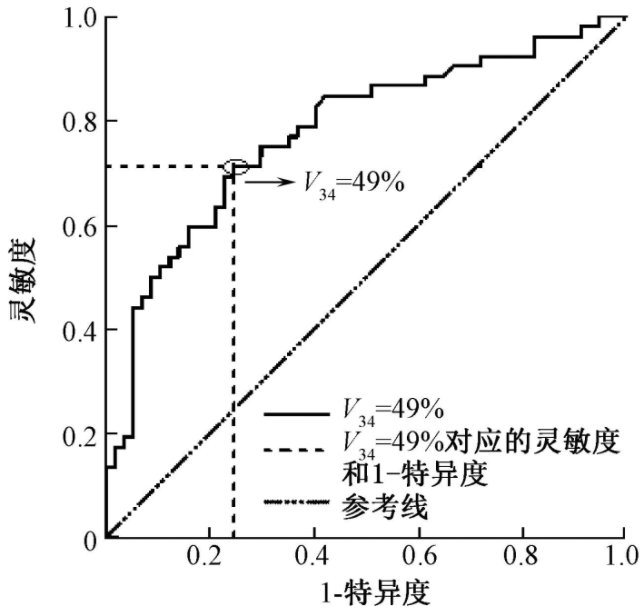
即图中V34点,具有较高的灵敏度和特异度。
四、参考
知识来源:https://blog.csdn.net/A_a_ron/article/details/79051077
知识贵在传播!