通过词频,对文章进行自动摘要(Automatic summarization)
摘要呢分为人工摘要和自动摘要。自动摘要呢,就是要找到那些包含信息最多的句子。有些句子包含信息多,有些句子包含信息少,自动摘要就是要找到那些包含信息最多的句子。
句子信息用关键词来衡量。如果包含的关键词越多,就说明这个句子越重要。有一个概念呢,就是用簇cluster表示关键词的聚集。所谓的簇就是包含多个关键词的句子片段。
当然了,我们称被框起来的部分是一个簇,只要管家此的距离小于门槛值,他们就被认为处于同一个簇之中,专家的建议门槛是4或5.也就是说两个关键词之间有5个以上的其他词,就可以把两个关键词分在两个簇。
在对每一个簇,都计算他的重要性分值

下以这个图为例有
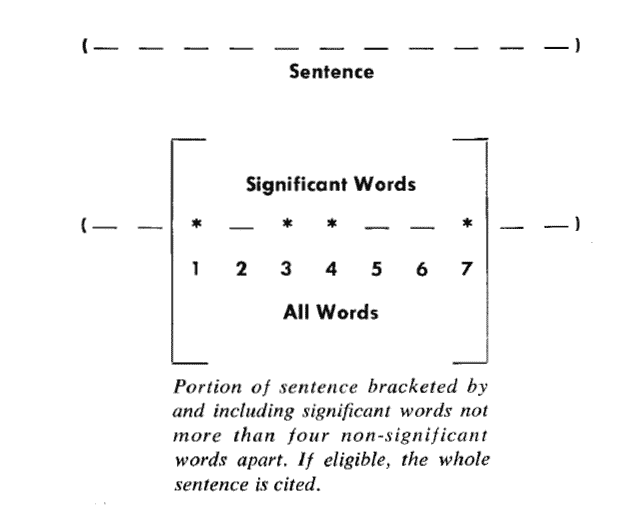
其中的簇一共有7个词,其中4个是关键词。因此,它的重要性分值等于 ( 4 x 4 ) / 7 = 2.3。然后,找出包含分值最高的簇的句子(比如5句),把它们合在一起,就构成了这篇文章的自动摘要。
Luhn的这种算法后来被简化,不再区分"簇",只考虑句子包含的关键词。下面就是一个例子(采用伪码表示),只考虑关键词首先出现的句子。
Summarizer(originalText, maxSummarySize):
// 计算原始文本的词频,生成一个数组,比如[(10,'the'), (3,'language'), (8,'code')...]
wordFrequences = getWordCounts(originalText)
// 过滤掉停用词,数组变成[(3, 'language'), (8, 'code')...]
contentWordFrequences = filtStopWords(wordFrequences)
// 按照词频进行排序,数组变成['code', 'language'...]
contentWordsSortbyFreq = sortByFreqThenDropFreq(contentWordFrequences)
// 将文章分成句子
sentences = getSentences(originalText)
// 选择关键词首先出现的句子
setSummarySentences = {}
foreach word in contentWordsSortbyFreq:
firstMatchingSentence = search(sentences, word)
setSummarySentences.add(firstMatchingSentence)
if setSummarySentences.size() = maxSummarySize:
break
// 将选中的句子按照出现顺序,组成摘要
summary = ""
foreach sentence in sentences:
if sentence in setSummarySentences:
summary = summary + " " + sentence
return summary
伪代码中貌似没有考虑句子重复的问题。