一、回顾group 查询
group查询就是分组查询,为什么要分组查询?因为我们想按某个维度进行统计。下面来看个图:
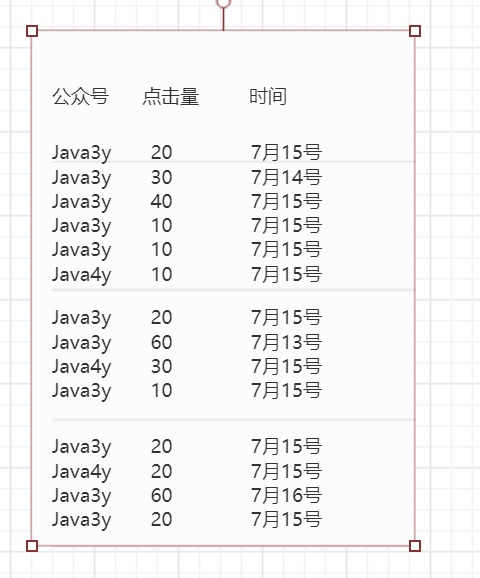
现在我的数据如下
比如说,我想知道:每天Java3y这个公众号的点击量是多少。按我们人工而言,思路很简单:把相同的天数以及公众号名称为Java3y的数据找出来,再将每个点击量相加,就得出了结果了。

步骤
用上SQL我们可能会这样写:
select name,time,sum(pv) as pv
from xxx_table
where name = 'Java3y' group by name,time
1.1 group 查询可能存在的误解
记得有一天,有个群友在群上问了一个问题:

群里边的一个问题
其实他的需求很简单:检索出数据分组后时间最高的记录。但他是这样干的:
-
把先按照时间
order by -
对
order by后的记录进行分组
示例图:
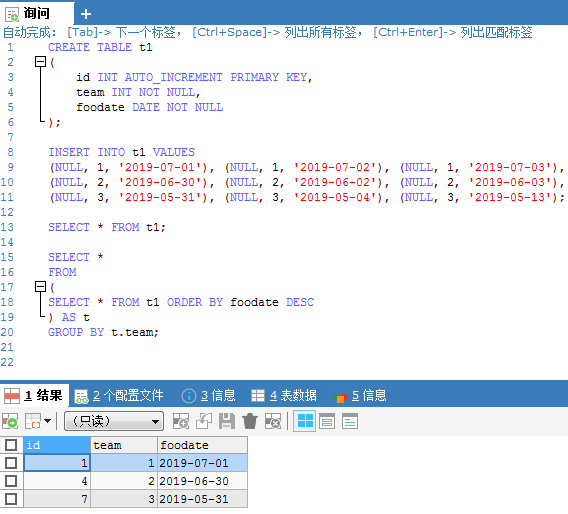
群里面的一个图
1.2 造成这个误解的可能原因
有的工具可以支持这种的写法:
select * from xxx_table group by name
这种写法没有被禁止,并可以得出结果,比如得到的结果是:
Java4y 20 7月15号
Java3y 30 7月15号
这种写法其实是不合理的,要知道的是:使用group by分组统计之后,我们的select 后面只能跟着group by 的字段,或者是聚合函数。

group by规则
因为,我们对数据进行了分组查询,数据的分布情况,我们是不关心的。
记住:先分组,后统计(先把数据归类后,再对相同的数据进行统计)
1.3 group查询最常用的SQL
去重是我们经常会遇到的问题,打个比方说,由于各种原因(不管是业务上还是说是脏数据),现在我有两条重复的数据(除了ID,其余的字段都是相同的):

重复的数据
我这边只希望留下某一条记录作为查询结果就好了,我们可以写下以下的SQL:
select * from user where id in( select min(id) from user where name = 'Java3y' and pv = 20 and time='7-25' group by name,pv,time; )
上面这条SQL是非常非常实用的,除了我说的去重以外,其实我们可以再”思考“一下:
-
上面已经说了,使用
group by分组统计之后,我们的select 后面只能跟着group by 的字段,或者是聚合函数。 -
很多时候我们
group by了以后,还想要查询结果中包含group by之外的字段(一般情况下,我们都不可能将group by 涵盖所有的字段),我们就可以上面那样,将查询后的结果作为子查询,放在外部查询的where 子句后,这样外部查询是可以select 出其他字段的。
(SQL写得比较少的朋友可能没什么感触啊,但我希望上面那种写法大家能够记住,以后一定会遇到类似的情况的)
二、回顾join查询
join查询不知道大家在刚学的时候是怎么理解的,反正我当初好像就挺迷迷糊糊的。我觉得join查询可以简单理解成这样:我想要的查询结果,一张表搞不掂,那我就join另一张表
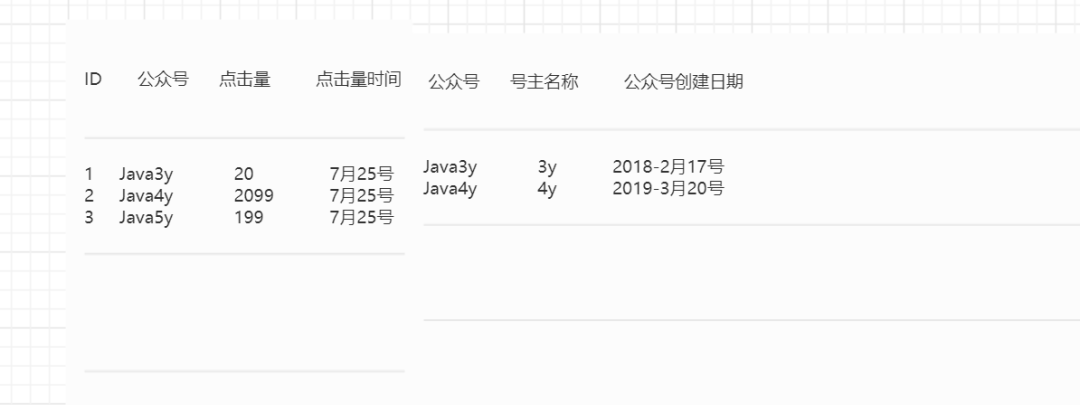
比如说,现在我有两张的表:

第一张表
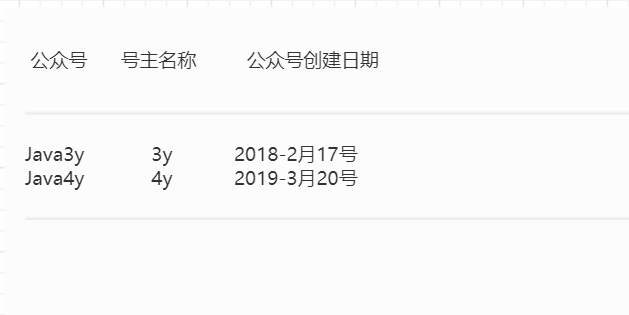
第二张表
现在我想知道在7月25号时:每个公众号的点击量、公众号名称、号主名称、公众号的创建日期
-
显然,我们会发现一张表搞不掂啊,某些数据要依赖于另一张表才能把数据"完整"展示出来
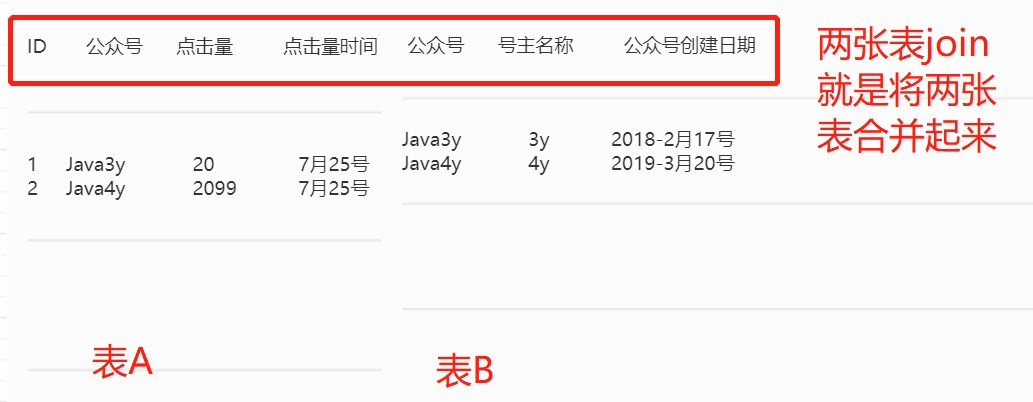 join其实就是一个合并的操作
join其实就是一个合并的操作
那join其实就是把两张表合起来的一个操作:
两张表合并起来以后我们就会发现,这张“大表”就含有这两张表的所有字段啦,那我想要什么都有了!
值得注意的是:在join的时候,会产生笛卡尔积(至于什么是笛卡尔积我这里就不说了,反正我们要记住的是join表时一定要写关联条件去除笛卡尔积)
另外,left join和right join也是我们经常用到,如果我们单纯写join关键字,那会被当成是inner join 。下面我简单解释一下:
-
上面说了,在join的时候一定要写关联条件,如果是
inner join的话,只有符合关联条件的数据才会存在最大表中 -
如果是
left join的话,即便关联条件不符合,左边表的数据一定会存在大表中 -
如果是
right join的话,即便关联条件不符合,右边表的数据一定会存在大表中
看下面的图:
join
此时我们的两张表关联的条件是“公众号” :如果是inner join,那么最后我们的表只有两条记录。如果是left join ,那么最后我们的表有三条数据。如果是right join,那么我们最后的表只有两条数据
三、回顾case when
SQL中的case when then else end用法其实跟我们程序语言中的if-else很是类似,在写SQL的时候也常常会用到。
我用得比较多的语法如下:
CASE WHEN sex = '1' THEN '男' WHEN sex = '2' THEN '女' ELSE '其他' END
在when后面可以跟多个表达式,比如说:
CASE WHEN sex = '1' and name ='Java3y' THEN '男' WHEN sex = '2' and name ='Java4y' THEN '女' ELSE '其他' END
如果要为case when表达式取别名,在end 关键字后边直接加就好了
更多用法详情参考:
四、一些常用的函数
4.1 hive和presto解析json
我这边会有这种情况:将json数据存到MySQL上。我去网上搜了一下以及问了同事,为什么要将json存到MySQL的字段上时,他们的答复都差不多:
-
在MySQL存json数据,这样方便扩展啊。如果那些字段不需要用到索引,改动比较频繁,你又不想改动表的结构,那可以存json。
-
ps:在MySQL 5.7版本以后支持json类型
参考资料:
我这边做报表一般来hive或presto上搞的,所以解析json的也是在那上面。
hive解析json函数:
get_json_object(param1,'$.param2') -- 如果是数组 get_json_object(xjson,'$.[0].param2')
presto 对json的处理函数:
-- 数组 (去除第index个json) json_array_get(xjson,index) -- 单个jsoin对象 json_extract(xjson,'$.param2')
参考资料:
4.2 时间函数
昨天/近7天/本月按照这种指标来查询也是非常常见的:
昨天 SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1 7天 SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名) 近30天 SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名) 本月 SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' ) 上一月 SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1
在presto中使用时间格式,需要明确写出关键字timestamp,比如:
select supplier,count(id)
from xxx_table
where sendtime >= timestamp '2019-06-01'
参考资料:
4.3 其他常用的函数
这里我简单整理一下我最近用过函数:
length --计算字符串长度 concat --连接两个字符串 substring -- 截取字符串 count -- 统计数量 max -- 最大 min -- 最小 sum -- 合计 floor/ceil --...数学函数
再来分享一下最近遇到的一个需求,现在有的数据如下:
【Java3y简单】快乐学习
【Java3y简单】快乐学习渣渣
【Java3y通俗易懂】简单学
【Java3y通俗易懂】简单学芭芭拉
【Java3y平易近人】无聊学
【Java3y初学者】枯燥学
【Java3y初学者】枯燥学呱呱
【Java3y大数据】欣慰学
【Java3y学习】巴拉巴拉学
【Java3y学习】巴拉巴拉学哈哈
【Java3y好】雨女无瓜学
现在我统计出【】括号里边出现的频次,比如说:Java3y通俗易懂出现的频次是多少。当时一直都没想到好的思路,都快要搜“SQL 正则表达式 快速入门”了,请教了一下同事,同事很快就写出来了:
select substring_index(left(title , INSTR(title , '】') -1 ) , '【',-1)
FROM `xxx_table`
哇~,awesome