(一)Python基础学习
Num01:python的基本数据类型
①字符串:可进行拼接和截取
②数字:int,float,complex(复数)
涉及到格式转换:int(x)转换为整数,float(x)转换为浮点数,complex(x)将x转换为一个复数,实部为x,虚部为0
运算注意:a/b得到的是一个浮点数,a//b得到的是:整数除法返回向下取整后的结果。a**b代表:a的b次幂
③列表(list)
形如:list=['Python','Web','Script']可对其进行访问和修改与删除
删除:del list[2]就将Script删除掉


a=[0,1,2,3,4] a[0]=9 b=[5,6,7,8] del b[2] print(a[:3]) print(b)
输出:
[9, 1, 2]
[5, 6, 8]
④Tuple(元组)
形如:tup1 = ('Google', 'Runoob', 1997, 2000)
我们不能修改里面的元素值,但可以进行访问和与其他的字符串进行拼接,元组有一些内置函数:len(tuple)计算元组的元素个数,max,min返回元组中的最大值和最小值。
⑤字典(Dictionary)
含有key和value,和map是一样的
# #字典;键与值的集合 dict = {} dict['one'] = "1 - 菜鸟教程" dict[2] = "2 - 菜鸟工具" tinydict = {'name': 'runoob', 'code': 1, 'site': 'www.runoob.com'} print(dict['one']) # 输出键为 'one' 的值 print(dict[2]) # 输出键为 2 的值 print(tinydict) # 输出完整的字典 print(tinydict.keys()) # 输出所有键 print(tinydict.values()) # 输出所有值 print(dict.keys()) # 输出所有键 print(dict.values()) # 输出所有值 print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
输出:
1 - 菜鸟教程
2 - 菜鸟工具
{'name': 'runoob', 'code': 1, 'site': 'www.runoob.com'}
dict_keys(['name', 'code', 'site'])
dict_values(['runoob', 1, 'www.runoob.com'])
dict_keys(['one', 2])
dict_values(['1 - 菜鸟教程', '2 - 菜鸟工具'])
我叫 小明 今年 10 岁!
Num02:while和if,elif,else与随机数的使用
一个猜数字的demo
#while和if elif和随机数的使用 k=random.randint(0,100) print(k) num=-1 while(num!=k): num = int(input("请输入你猜的数字: ")) if(num==k): print("恭喜你猜对了!") break elif(num>k): print("猜大了!") else: print("猜小了")
判断平年还是闰年
#判断闰年与平年 year = int(input("输入一个年份: ")) if (year % 4) == 0: if (year % 100) == 0: if (year % 400) == 0: print("{0} 是闰年".format(year)) # 整百年能被400整除的是闰年 else: print("{0} 不是闰年".format(year)) else: print("{0} 是闰年".format(year)) # 非整百年能被4整除的为闰年 else: print("{0} 不是闰年".format(year))
Num03:函数的使用
斐波那契数列求解:
def fic(k): if(k==1): return 1 elif(k==2): return 1 else: return fic(k-1)+fic(k-2) c=int(input("请输入要查询的第几个斐波那契数: ")) print(fic(c))
Num04:面向对象编程
1.封装
class Big(): def __init__(self,name,age): self.name=name self.age=age def detail(self): print(self.name) print(self.age) obj1=Big('Tom','18') obj1.detail()
通过封装的形似定义了一个Big类,在该类中可以通过各种函数来定义Big的各种行为和特性,这就是面向对象编程所需要的,会使对象的操作简单,有条理化。
2.继承
继承:子继承了父的某些特性
猫:喵喵叫、吃、喝、拉、撒
狗:旺旺叫、吃、喝、拉、撒
我们将他们共同的特性整合到一起
建立一个Animal:吃喝拉撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
class Animal: def eat(self): print("%s 吃" %self.name) def drink(self): print("%s 喝" %self.name) def shit(self): print("%s 拉" %self.name) def prr(self): print("%s 撒" %self.name) class Cat(Animal): def __init__(self,name): self.name=name def cry(self): print('喵喵叫') class Dog(Animal): def __init__(self,name): self.name=name def cry(self): print('汪汪叫') c1=Cat('我家的小白猫') c1.eat() c1.cry() d1=Dog('胖子家的小黑狗') d1.eat() d1.cry()
Num05:简单的入门级爬虫实验
爬取我的博客园的第一篇博客的时间和标题
分三步走:
第一步:获取页面
首先导入import requests,使用requests.get(link,headers=headers)获取网页
注意:用requests的headers伪装成浏览器访问,我们要获得的信息在response.text里(就是网页的内容代码)
第二步:提取想要的数据
这里会用到BeautifulSoup这个库对爬下来的页面进行解析,将html代码转化为soup对象,接下来用find去寻找自己的数据
第三步:存储数据
存储到本地的txt文件,将获取的信息写入txt里,这里要特别注意格式encoding='utf-8',否则到txt里的东西会乱码
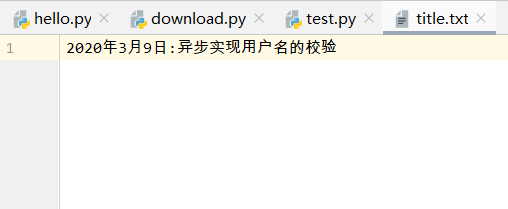
from bs4 import BeautifulSoup import requests, sys import random #1.获取网页代码 url = 'https://www.cnblogs.com/xiaofengzai/' #请求地址 headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}#创建头部信息 response = requests.get(url,headers = headers) #发送网络请求 #print(response.text) #2.提取想要的数据 soup=BeautifulSoup(response.text,"html.parser") title=soup.find("a",class_="postTitle2").text.strip() print(title) time=soup.find("div",class_="dayTitle").a.text.strip() print(time) #3.写入到文件里 with open("title.txt","a+",encoding='utf-8') as f: f.write(time+":"+title) f.close()
txt内容
| 日期 | 开始时间 | 结束时间 | 中断时间 | 净时间 | 活动 |
| 3/11 | 10:50 | 11:20 | 5 | 25 | 学习python的基本数据 |
| 3/11 | 14:00 | 15:30 | 10 | 80 | 学习python的语法,函数以及面向对象 |
| 3/11 | 16:00 | 17:30 | 5 | 85 | 对Python进行实战测试,巩固知识 |
| 3/11 | 20:30 | 21:30 | 10 | 50 | 学习简单的爬虫并动手进行练习 |
| 3/11 | 21:40 | 22:30 | 0 | 50 | 写博客,总结 |
今日有效总代码量(Python):180行,总学习时间:290分钟