转自:https://www.cnblogs.com/poerli/p/6429673.html
测试用CGI,名字为test.py,放在apache的cgi-bin目录下:
#!/usr/bin/Python
import cgi
def main():
print "Content-type: text/html
"
form = cgi.FieldStorage()
if form.has_key("ServiceCode") and form["ServiceCode"].value != "":
print "<h1> Hello",form["ServiceCode"].value,"</h1>"
else:
print "<h1> Error! Please enter first name.</h1>"
main()
python发送post和get请求
get请求:
使用get方式时,请求数据直接放在url中。
方法一、
import urllib
import urllib2
url = "http://192.168.81.16/cgi-bin/python_test/test.py?ServiceCode=aaaa"
req = urllib2.Request(url)
print req
res_data = urllib2.urlopen(req)
res = res_data.read()
print res
方法二、
import httplib
url = "http://192.168.81.16/cgi-bin/python_test/test.py?ServiceCode=aaaa"
conn = httplib.HTTPConnection("192.168.81.16")
conn.request(method="GET",url=url)
response = conn.getresponse()
res= response.read()
print res
post请求:
使用post方式时,数据放在data或者body中,不能放在url中,放在url中将被忽略。
方法一、
import urllib
import urllib2
test_data = {'ServiceCode':'aaaa','b':'bbbbb'}
test_data_urlencode = urllib.urlencode(test_data)
requrl = "http://192.168.81.16/cgi-bin/python_test/test.py"
req = urllib2.Request(url = requrl,data =test_data_urlencode)
print req
res_data = urllib2.urlopen(req)
res = res_data.read()
print res
方法二、
import urllib
import httplib
test_data = {'ServiceCode':'aaaa','b':'bbbbb'}
test_data_urlencode = urllib.urlencode(test_data)
requrl = "http://192.168.81.16/cgi-bin/python_test/test.py"
headerdata = {"Host":"192.168.81.16"}
conn = httplib.HTTPConnection("192.168.81.16")
conn.request(method="POST",url=requrl,body=test_data_urlencode,headers = headerdata)
response = conn.getresponse()
res= response.read()
print res
对python中json的使用不清楚,所以临时使用了urllib.urlencode(test_data)方法;
模块urllib,urllib2,httplib的区别
httplib实现了http和https的客户端协议,但是在python中,模块urllib和urllib2对httplib进行了更上层的封装。
介绍下例子中用到的函数:
1、HTTPConnection函数
httplib.HTTPConnection(host[,port[,stict[,timeout]]])
这个是构造函数,表示一次与服务器之间的交互,即请求/响应
host 标识服务器主机(服务器IP或域名)
port 默认值是80
strict 模式是False,表示无法解析服务器返回的状态行时,是否抛出BadStatusLine异常
例如:
conn = httplib.HTTPConnection("192.168.81.16",80) 与服务器建立链接。
2、HTTPConnection.request(method,url[,body[,header]])函数
这个是向服务器发送请求
method 请求的方式,一般是post或者get,
例如:
method="POST"或method="Get"
url 请求的资源,请求的资源(页面或者CGI,我们这里是CGI)
例如:
url="http://192.168.81.16/cgi-bin/python_test/test.py" 请求CGI
或者
url="http://192.168.81.16/python_test/test.html" 请求页面
body 需要提交到服务器的数据,可以用json,也可以用上面的格式,json需要调用json模块
headers 请求的http头headerdata = {"Host":"192.168.81.16"}
例如:
test_data = {'ServiceCode':'aaaa','b':'bbbbb'}
test_data_urlencode = urllib.urlencode(test_data)
requrl = "http://192.168.81.16/cgi-bin/python_test/test.py"
headerdata = {"Host":"192.168.81.16"}
conn = httplib.HTTPConnection("192.168.81.16",80)
conn.request(method="POST",url=requrl,body=test_data_urlencode,headers = headerdata)
conn在使用完毕后,应该关闭,conn.close()
3、HTTPConnection.getresponse()函数
这个是获取http响应,返回的对象是HTTPResponse的实例。
4、HTTPResponse介绍:
HTTPResponse的属性如下:
read([amt]) 获取响应消息体,amt表示从响应流中读取指定字节的数据,没有指定时,将全部数据读出;
getheader(name[,default]) 获得响应的header,name是表示头域名,在没有头域名的时候,default用来指定返回值
getheaders() 以列表的形式获得header
例如:
date=response.getheader('date');
print date
resheader=''
resheader=response.getheaders();
print resheader
列形式的响应头部信息:
[('content-length', '295'), ('accept-ranges', 'bytes'), ('server', 'Apache'), ('last-modified', 'Sat, 31 Mar 2012 10:07:02 GMT'), ('connection', 'close'), ('etag', '"e8744-127-4bc871e4fdd80"'), ('date', 'Mon, 03 Sep 2012 10:01:47 GMT'), ('content-type', 'text/html')]
date=response.getheader('date');
print date
取出响应头部的date的值。
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地。
类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的内容发送到服务器端, 然后读取服务器端的响应资源。
在Python中,我们使用urllib2这个组件来抓取网页。
urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。
它以urlopen函数的形式提供了一个非常简单的接口。
最简单的urllib2的应用代码只需要四行。
我们新建一个文件urllib2_test01.py来感受一下urllib2的作用:
import urllib2
response = urllib2.urlopen('http://www.baidu.com/')
html = response.read()
print html
按下F5可以看到运行的结果:
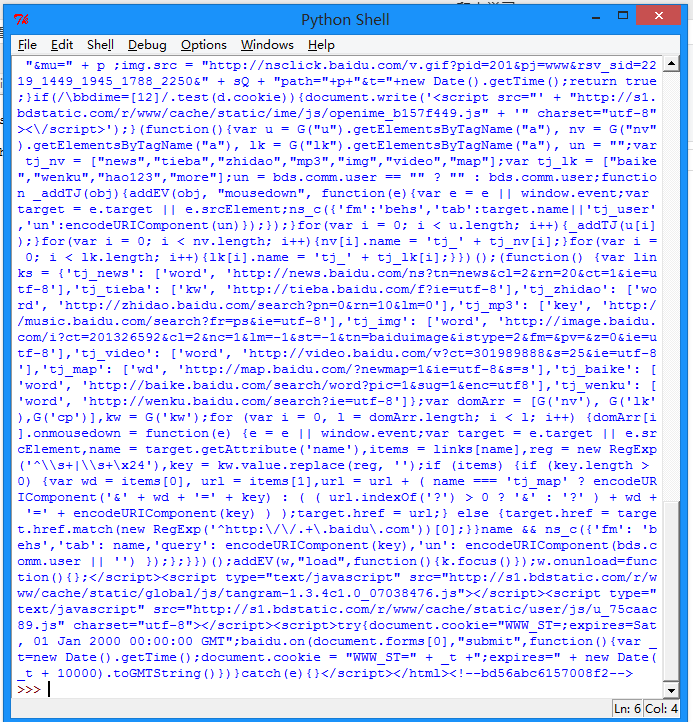
我们可以打开百度主页,右击,选择查看源代码(火狐OR谷歌浏览器均可),会发现也是完全一样的内容。
也就是说,上面这四行代码将我们访问百度时浏览器收到的代码们全部打印了出来。
这就是一个最简单的urllib2的例子。
除了"http:",URL同样可以使用"ftp:","file:"等等来替代。
HTTP是基于请求和应答机制的:
客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求。
在它最简单的使用形式中你将用你要请求的地址创建一个Request对象,
通过调用urlopen并传入Request对象,将返回一个相关请求response对象,
这个应答对象如同一个文件对象,所以你可以在Response中调用.read()。
我们新建一个文件urllib2_test02.py来感受一下:
import urllib2
req = urllib2.Request('http://www.baidu.com')
response = urllib2.urlopen(req)
the_page = response.read()
print the_page
可以看到输出的内容和test01是一样的。
urllib2使用相同的接口处理所有的URL头。例如你可以像下面那样创建一个ftp请求。
req = urllib2.Request('ftp://example.com/')
在HTTP请求时,允许你做额外的两件事。
1.发送data表单数据
这个内容相信做过Web端的都不会陌生,
有时候你希望发送一些数据到URL(通常URL与CGI[通用网关接口]脚本,或其他WEB应用程序挂接)。
在HTTP中,这个经常使用熟知的POST请求发送。
这个通常在你提交一个HTML表单时由你的浏览器来做。
并不是所有的POSTs都来源于表单,你能够使用POST提交任意的数据到你自己的程序。
一般的HTML表单,data需要编码成标准形式。然后做为data参数传到Request对象。
编码工作使用urllib的函数而非urllib2。
我们新建一个文件urllib2_test03.py来感受一下:
import urllib
import urllib2
url = 'http://www.someserver.com/register.cgi'
values = {'name' : 'WHY',
'location' : 'SDU',
'language' : 'Python' }
data = urllib.urlencode(values) # 编码工作
req = urllib2.Request(url, data) # 发送请求同时传data表单
response = urllib2.urlopen(req) #接受反馈的信息
the_page = response.read() #读取反馈的内容
如果没有传送data参数,urllib2使用GET方式的请求。
GET和POST请求的不同之处是POST请求通常有"副作用",
它们会由于某种途径改变系统状态(例如提交成堆垃圾到你的门口)。
Data同样可以通过在Get请求的URL本身上面编码来传送。
import urllib2
import urllib
data = {}
data['name'] = 'WHY'
data['location'] = 'SDU'
data['language'] = 'Python'
url_values = urllib.urlencode(data)
print url_values
name=Somebody+Here&language=Python&location=Northampton
url = 'http://www.example.com/example.cgi'
full_url = url + '?' + url_values
data = urllib2.open(full_url)
这样就实现了Data数据的Get传送。
2.设置Headers到http请求
有一些站点不喜欢被程序(非人为访问)访问,或者发送不同版本的内容到不同的浏览器。
默认的urllib2把自己作为“Python-urllib/x.y”(x和y是Python主版本和次版本号,例如Python-urllib/2.7),
这个身份可能会让站点迷惑,或者干脆不工作。
浏览器确认自己身份是通过User-Agent头,当你创建了一个请求对象,你可以给他一个包含头数据的字典。
下面的例子发送跟上面一样的内容,但把自身模拟成Internet Explorer。
(多谢大家的提醒,现在这个Demo已经不可用了,不过原理还是那样的)。
import urllib
import urllib2
url = 'http://www.someserver.com/cgi-bin/register.cgi'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
values = {'name' : 'WHY',
'location' : 'SDU',
'language' : 'Python' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
the_page = response.read()
以上就是python利用urllib2通过指定的URL抓取网页内容的全部内容,非常简单吧,希望对大家能有所帮助