1.集群规划
hadoop有三个重要的进程为NN(NameNode)、2NN(SecondaryNameNode)、RM(ResourceManager)
其中由于2NN需要做editlog和fsimage的合并占用的内存空间大致相等,为了性能NN和2NN要再两台机器上。
启动情况如下
hadoop102:DataNode NodeManager NameNode
hadoop103:DataNode NodeManager ResourceManager
hadoop104:DataNode NodeManager SecondaryNameNode
2.配置集群-在一台机器上
①配置core-site.xml -NN
[root@hadoop102 hadoop-2.7.2]# vim etc/hadoop/core-site.xml
sent 55,165 bytes received 587 bytes 12,389.33 bytes/sec
total size is 249,362,889 speedup is 4,472.72
------------------- hadoop104 --------------
sending incremental file list
hadoop-2.7.2/etc/hadoop/core-site.xml
hadoop-2.7.2/etc/hadoop/hdfs-site.xml
hadoop-2.7.2/etc/hadoop/mapred-site.xml
hadoop-2.7.2/etc/hadoop/yarn-site.xml
hadoop-2.7.2/grep_1_input/
hadoop-2.7.2/grep_1_input/capacity-scheduler.xml
hadoop-2.7.2/grep_1_input/core-site.xml
hadoop-2.7.2/grep_1_input/hadoop-policy.xml
hadoop-2.7.2/grep_1_input/hdfs-site.xml
hadoop-2.7.2/grep_1_input/httpfs-site.xml
hadoop-2.7.2/grep_1_input/kms-acls.xml
hadoop-2.7.2/grep_1_input/kms-site.xml
hadoop-2.7.2/grep_1_input/yarn-site.xml
hadoop-2.7.2/grep_1_output/
hadoop-2.7.2/grep_1_output/._SUCCESS.crc
hadoop-2.7.2/grep_1_output/.part-r-00000.crc
hadoop-2.7.2/grep_1_output/_SUCCESS
hadoop-2.7.2/grep_1_output/part-r-00000
hadoop-2.7.2/wdcnt_1_input/
hadoop-2.7.2/wdcnt_1_input/wc.input
hadoop-2.7.2/wdcnt_1_output/
hadoop-2.7.2/wdcnt_1_output/._SUCCESS.crc
hadoop-2.7.2/wdcnt_1_output/.part-r-00000.crc
hadoop-2.7.2/wdcnt_1_output/_SUCCESS
hadoop-2.7.2/wdcnt_1_output/part-r-00000
sent 55,161 bytes received 579 bytes 15,925.71 bytes/sec
total size is 249,362,889 speedup is 4,473.68
4.机器单点模式启动
①第一次启动格式化NameNode
[root@hadoop102 hadoop-2.7.2]# hadoop namenode -format
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
21/01/22 22:25:58 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
......
②hadoop102启动NameNode
[root@hadoop102 hadoop-2.7.2]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop102.out
[root@hadoop102 hadoop-2.7.2]# cat /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop102.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3766
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 3766
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@hadoop102 hadoop-2.7.2]# jps | grep -v Jps
4067 NameNode
③hadoop102、hadoop103、hadoop104启动DataNode
[root@hadoop102 hadoop-2.7.2]# hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop102.out
[root@hadoop102 hadoop-2.7.2]# cat /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop102.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3766
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 3766
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@hadoop102 hadoop-2.7.2]# jps |grep -v Jps
4208 DataNode
4067 NameNode
④hadoop104启动SecondaryNameNode
[root@hadoop104 ~]# hadoop-daemon.sh start secondarynamenode
starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop104.out
[root@hadoop104 ~]# cat /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop104.out
ulimit -a for user root
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 3766
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 3766
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
[root@hadoop104 ~]# jps |grep -v Jps
3031 DataNode
3198 SecondaryNameNode
至此hdfs启动成功。yarn启动同理
访问http://hadoop102:50070,可以看到启动成功


5.集群模式启动
集群模式启动包含群起hdfs和群起yarn。
在一台机器执行群起脚本启动整个机器需要ssh远程登录,需要配置免密登录。
①配置ssh免密登录
当前用户家目录创建.ssh - 700(如无创建,若执行过远程登录改目录可能已经存在,便不需要创建)
[root@hadoop104 ~]# cd ~
[root@hadoop104 ~]# pwd
/root
[root@hadoop104 ~]# ls -al |grep .ssh
[root@hadoop104 ~]# mkdir .ssh
[root@hadoop104 ~]# chmod 700 .ssh/
[root@hadoop104 ~]# ls -al |grep .ssh
drwx------. 2 root root 6 Jan 22 22:46 .ssh
[root@hadoop104 ~]# cd .ssh/
[root@hadoop104 .ssh]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:Cc+QvIjZ0RRkEca50tO99mFdOAizcaHPVhEcIJecx+s root@hadoop104
The key's randomart image is:
+---[RSA 2048]----+
| oO= ..+B+o |
| o. ++= +. |
| ..o ..* o.o |
| +.o+*..oo..+ .|
| o o...S .+o o |
| o.o E |
| . o . |
| . |
| |
+----[SHA256]-----+
[root@hadoop104 .ssh]# ls
id_rsa id_rsa.pub
将公钥拷贝到要远程登录的机器hadoop103
[root@hadoop104 .ssh]# ssh-copy-id hadoop103
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop103 (192.168.28.103)' can't be established.
ECDSA key fingerprint is SHA256:hGOYAoHB0cW3VKOa9ptXdgQG6sAvRga277ej56ZVvaY.
ECDSA key fingerprint is MD5:c5:2a:e2:65:47:95:cb:eb:f5:d4:15:66:c4:7d:5a:cc.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop103's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop103'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop104 .ssh]# ssh hadoop103
Last login: Fri Jan 22 20:46:23 2021 from hadoop1
[root@hadoop103 ~]#
此时可以hadoop102免密登录hadoop103,再将公钥拷贝到hadoop102,其余两台同理。
②配置slaves
[root@hadoop102 hadoop-2.7.2]# cd /opt/module/hadoop-2.7.2/
[root@hadoop102 hadoop-2.7.2]# vim etc/hadoop/slaves
hadoop102
hadoop103
hadoop104
分发配置到hadoop103、hadoop104
[root@hadoop102 hadoop-2.7.2]# xsync /opt/module/hadoop-2.7.2/etc/hadoop/slaves
③停止所有hdfs进程,删除data和log,格式化NameNode
[root@hadoop102 hadoop-2.7.2]# jps
4208 DataNode
4067 NameNode
5172 Jps
[root@hadoop102 hadoop-2.7.2]# hadoop-daemon.sh stop datanode
stopping datanode
[root@hadoop102 hadoop-2.7.2]# hadoop-daemon.sh stop namenode
stopping namenode
[root@hadoop102 hadoop-2.7.2]#
[root@hadoop103 ~]# jps
3910 Jps
3035 DataNode
[root@hadoop103 ~]# hadoop-daemon.sh stop datanode
stopping datanode
[root@hadoop103 ~]# jps
3972 Jps
[root@hadoop103 ~]#
[root@hadoop104 ~]# jps
3031 DataNode
3198 SecondaryNameNode
4095 Jps
[root@hadoop104 ~]# hadoop-daemon.sh stop datanode
stopping datanode
[root@hadoop104 ~]# hadoop-daemon.sh stop secondarynamenode
stopping secondarynamenode
[root@hadoop104 ~]# jps
4190 Jps
[root@hadoop104 ~]#
[root@hadoop102 hadoop-2.7.2]# rm -rf data/ logs/
[root@hadoop103 hadoop-2.7.2]# rm -rf data/ logs/
[root@hadoop104 hadoop-2.7.2]# rm -rf data/ logs/
[root@hadoop102 hadoop-2.7.2]# hdfs namenode -format
④启动hdfs - hadoop102 在NameNode上启动hdfs
[root@hadoop102 hadoop-2.7.2]# start-dfs.sh
Starting namenodes on [hadoop102]
hadoop102: Error: JAVA_HOME is not set and could not be found.
hadoop102: Error: JAVA_HOME is not set and could not be found.
hadoop103: Error: JAVA_HOME is not set and could not be found.
hadoop104: Error: JAVA_HOME is not set and could not be found.
Starting secondary namenodes [hadoop104]
hadoop104: Error: JAVA_HOME is not set and could not be found.
[root@hadoop102 hadoop-2.7.2]#
此时报错便是未修改hadoop-env、yarn-env.sh、mapred-env.sh中java_home引起的
ps:是不是因为远程登录ssh不能使用${JAVA_HOME}呢?
将hadoop-env、yarn-env.sh、mapred-env.sh中添加
export JAVA_HOME=/opt/module/jdk1.8.0_144
并分发
格式化再次启动
[root@hadoop102 hadoop-2.7.2]# start-dfs.sh
Starting namenodes on [hadoop102]
hadoop102: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-hadoop102.out
hadoop103: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop103.out
hadoop102: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop102.out
hadoop104: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-hadoop104.out
Starting secondary namenodes [hadoop104]
hadoop104: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-secondarynamenode-hadoop104.out
[root@hadoop102 hadoop-2.7.2]# jps
6198 NameNode
6538 Jps
6335 DataNode
[root@hadoop103 hadoop-2.7.2]# jps
4369 Jps
4285 DataNode
[root@hadoop104 hadoop-2.7.2]# jps
4691 Jps
4645 SecondaryNameNode
4538 DataNode
⑤启动yarn - hadoop103 在ResourceManager上启动yarn
[root@hadoop103 hadoop-2.7.2]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-hadoop103.out
hadoop104: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop104.out
hadoop102: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop102.out
hadoop103: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-hadoop103.out
[root@hadoop102 hadoop-2.7.2]# jps
6706 Jps
6198 NameNode
6585 NodeManager
6335 DataNode
[root@hadoop103 hadoop-2.7.2]# jps
4423 ResourceManager
4536 NodeManager
4285 DataNode
4830 Jps
[root@hadoop104 hadoop-2.7.2]# jps
4865 Jps
4645 SecondaryNameNode
4742 NodeManager
4538 DataNode
⑥一些控制台
hdfs管理:
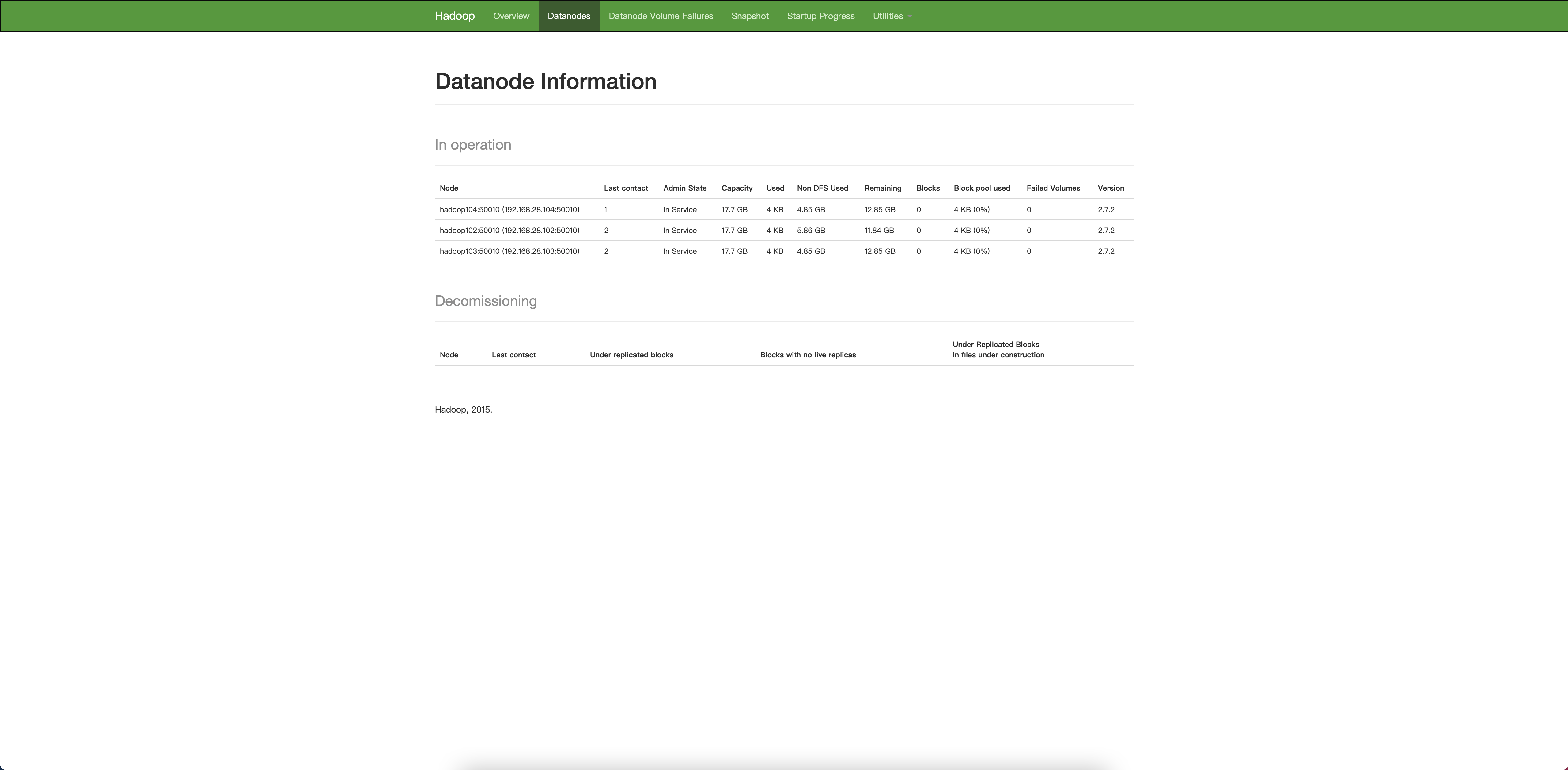
hadoop102:50070

yarn管理:
hadoop103:8088
jobhistory:
hadoop103:19888
启动 - jobhistory:mr-jobhistory-daemon.sh start historyserver