谷歌出品。这篇文章是通过学习目标的结构和动力学特征来预测视频中的目标,从而实现非监督。利用识别关键点技术,将目标像素级别之间的关系提升到关键点之间的关系,更加接近语义特征,确定目标结构。通过VRNN算法确定从关键点特征中得到的动力学特征。
《摘要》
从无监督视频中学习到目标的结构和动力学特征是一个挑战,提出论文的方法,基于图像的特征点表达学习到特征点的动力学模型,之后的图像帧从学习到的关键点和参考图像帧(第一帧)中重建。论文提出方法的优点在于,能稳定学习和避免空间上的像素级的错误混合。并且有利于之后进一步的目标级别研究。
《介绍》
视频能提供丰富的信息去学习到存在的动力学,但是想学到动力学的表达又很难,很有挑战。
论文通过预测无监督视频的未来帧来理解视频,要做到这个有两个挑战,1、视频中动作随机性大,做像素级别的预测难;2、像素级别的重建无法保证之后的高级别的任务,如跟踪、运动预测和运动控制。
接着又开始介绍论文的方法来应对挑战,从单帧图像中编码处关键点,然后从关键点中学习动力学。论文的贡献是:1、提出无监督视频预测任务新的结构和优化方法,一个结构话的内部表达。2、在视频预测中超过了现有水平。3、为需要目标级别理解的任务提高了效果。
《相关工作》
有四个方面,Unsupervised learning of keypoints、Stochastic sequence prediction、Unsupervised video prediction、Video prediction with spatially structured representations
具体每个解析 略
《结构》
论文模型由两部分构成:关键点检测子(从每帧图片预测低维度的关键点表达),动力学模型(预测在关键点空间的动力学)
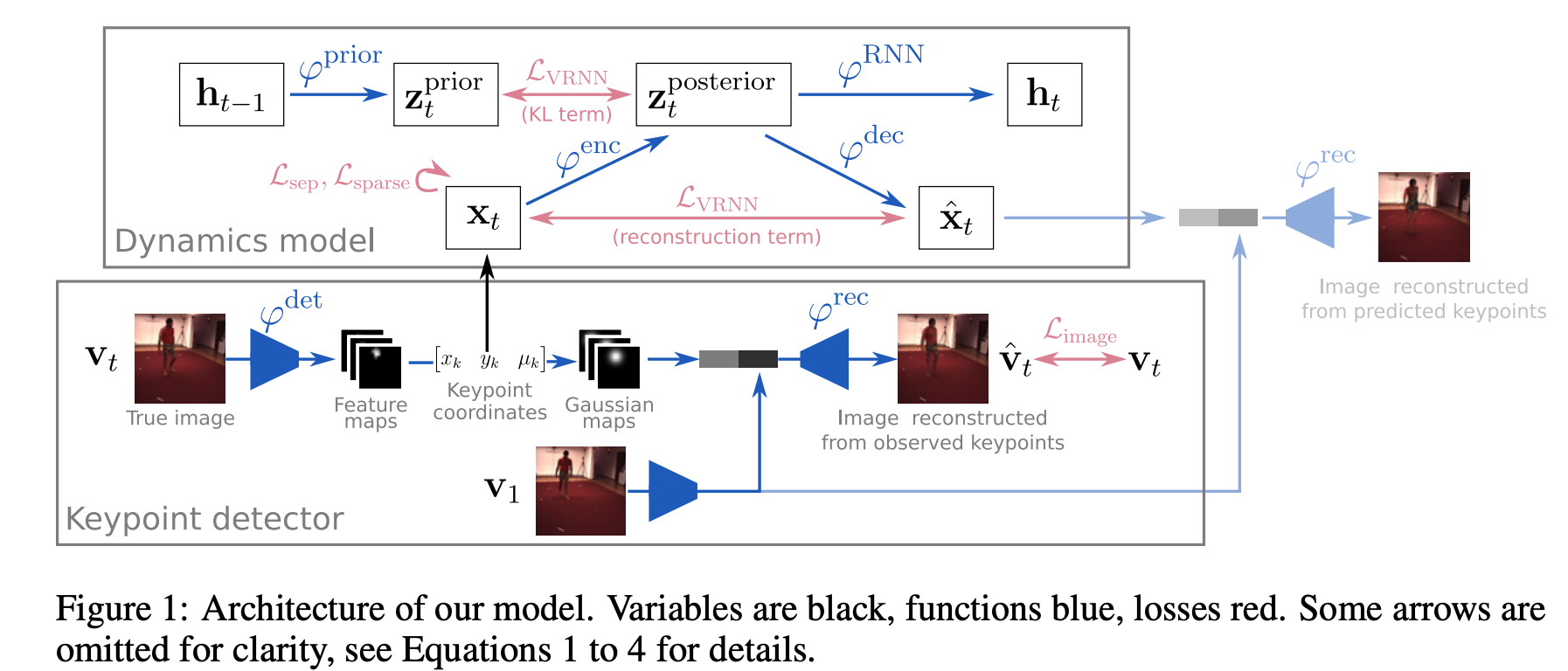
无监督关键点检测子:目标是学习一个可以捕捉每帧图像目标空间结构一系列关键点的关键点检测子,检测子是一个卷积神经网络,可产生K个特征图,每个关键点一个特征图,通过将每一个特征图归一化并压缩到一个二维坐标来计算特征图的空间期望。表明模型需要该特征图的最大期望值。
在图像重建的时候,学习到的生成器从关键点表达上重建特征图。生成器通过视频序列的第一帧捕捉静态的场景外貌。关键点检测子和生成器形成一个自动编码结构,该结构还有一个表达瓶颈可以编码关键点表达。
是为了将关键点应用于网络,每个关键点才需要被转化为高斯形状的blob。
第一帧的特征图也会被用于之后帧,帮助绘制之后帧的背景,
随机动力学模型:
学习视频中的动力学模型,使用VRNN网络模型,动力学模型的核心是一个基于关键点坐标的潜在的置信度z。VRNN模型的先验置信是靠之前的时间信息,所以可以在观察当前帧之前预测当前关键点。
《训练》
略
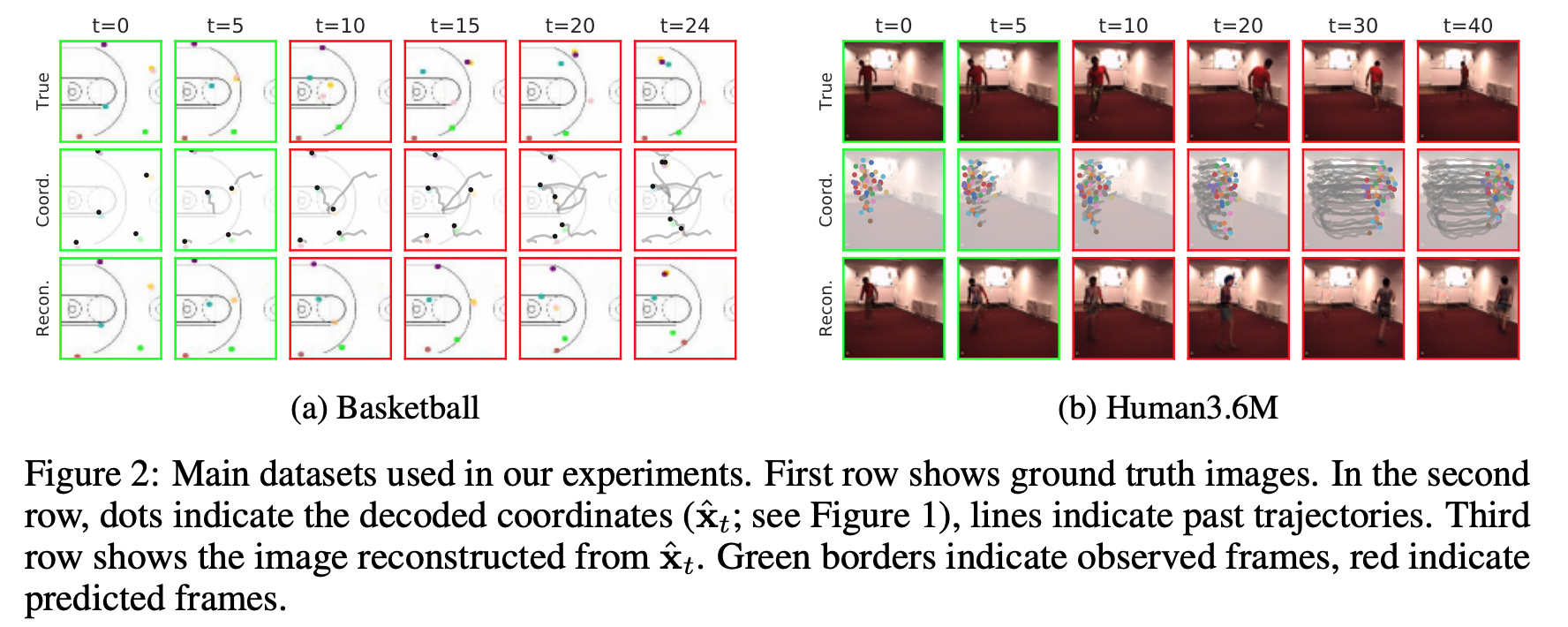
《结果》
略
《讨论》
略