日常排雷:mysql之数据量越小,查询越慢
同样的sql ,在不同的数据库上,执行效率不一致
现象:
mysql版本5.7
数据库引擎 innoDB
测试与开发两个数据库上,表结构完全一致、索引一致
数据量有稍微不同
大致sql类似:select b.code from A as h LEFT JOIN B as b on b.h_id=h.id limit 0,20 ;
实际sql(公司数据隐私):有900行,n张表关联,子查询、in、exists 、order by 啥都有 ~~~
开发环境数据库上的数据情况
A表的数据为4w条左右
B表的数据为23条
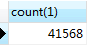
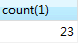

查询时间0.068秒
测试环境数据库上的数据情况
A表的数据为4w条左右
B表的数据为5条
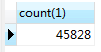


查询时间15.703秒
A表 id 为主键索引
B表为 h_id 普通索引
EXPLAIN select b.code from A as h LEFT JOIN B as b on b.h_id=h.id limit 0,20 ;
执行一看
"表B数据为5条" 的数据库,不走索引,使用了Block Nested Loop 算法

"表B数据为23条" 的数据库,走了索引

原来数据量小,还会影响查询速度,使查询速度变慢 ???


为了验证是否是成本计算产生的问题,对 “B表数据为5条” 的数据库对应的表 insert 了18条数据,再查询,立即秒出 0.06秒


果然算法才是精髓啊~~
那么为啥不走索引会相差这么大,再看下上面提及的 不走索引,直接使用了Block Nested Loop 算法,
不走索引的情况下,会对A表的全表数据进行关联匹配,之后再进行limit 0,20。-->>那不就是查全表了吗,数据量一大不害死人。。。。
走索引的情况下,先 limit 0,20的前20条数据,进行关联匹配,
这就是最终原因吧
以后别说,加了索引,查询怎么还没快点啊,先看下执行计划再说~~
原来走不走索引,不是你说了算,你建了索引,mysql数据库还不一定就会走,还得经过一次cost计算,择出最优索引方案,然而这个最优方案不一定是适合所有场景~~