这一篇博客以代码为主,主要是来介绍如果使用keras构建一个DCGAN,然后基于DCGAN,做一个自动生成动漫头像。训练过程如下(50轮的训练过程)“

关于DCGAN或者GAN的相关知识,可以参考GAN网络入门教程。建议先了解相关知识,再来看这一篇博客。
项目地址:GitHub
使用前准备
首先的首先,我们肯定是需要数据集的,这里使用的数据集来自kaggle——Anime Faces。里面有21551张动漫头像的图片。大家可以到kaggle上面去下载数据集,或者说到我的github上去下载数据集(求个 ⭐ 不过分吧)。部分数据如下:

如果自己电脑计算机资源不是很强的话,比如我,一个mx250小水管(玩玩lol还是可以的,训练这个模型可能要等到下辈子),推荐大家去注册一个kaggle或者colab账号去白嫖GPU资源(1080,2080的玩家请随意)。不过个人更加的推荐kaggle,因为感觉它的资源分配是可见的,且可以后台运行。
数据集
数据集是动漫图片,我们可以将图片的像素点的值变成([-1,1])之间,具体代码如下:
# 数据集的位置
avatar_img_path = "./data"
import imageio
import os
import numpy as np
def load_data():
"""
加载数据集
:return: 返回numpy数组
"""
all_images = []
for image_name in os.listdir(avatar_img_path):
# 加载图片
image = imageio.imread(os.path.join(avatar_img_path,image_name))
all_images.append(image)
all_images = np.array(all_images)
# 将图片数值变成[-1,1]
all_images = (all_images - 127.5) / 127.5
# 将数据随机排序
np.random.shuffle(all_images)
return all_images
img_dataset = load_data()
然后定义展示图片的方法:
import matplotlib.pyplot as plt
def show_images(images,index = -1):
"""
展示并保存图片
:param images: 需要show的图片
:param index: 图片名
:return:
"""
plt.figure()
for i, image in enumerate(images):
ax = plt.subplot(5, 5, i+1)
plt.axis('off')
plt.imshow(image)
plt.savefig("data_%d.png"%index)
plt.show()
- 展示数据集中的部分图片:
show_images(img_dataset[0: 25])

定义参数
这里我们只定义两个参数,图片的shape代表生成的图片是(64 imes 64)的RGB图片,以及noise的大小是100:
# noise的维度
noise_dim = 100
# 图片的shape
image_shape = (64,64,3)
构建网络
首先导入tensorflow中的keras库,如下:
from tensorflow.keras.models import Sequential,Model
from tensorflow.keras.layers import UpSampling2D, Conv2D, Dense, BatchNormalization, LeakyReLU, Input,Reshape, MaxPooling2D, Flatten, AveragePooling2D, Conv2DTranspose
from tensorflow.keras.optimizers import Adam
下图中的网络结构参照了kaggle中的Anime face generation with DCGAN (beginner)。
构建G网络
生成器网络,我们按照如下的结构进行构建: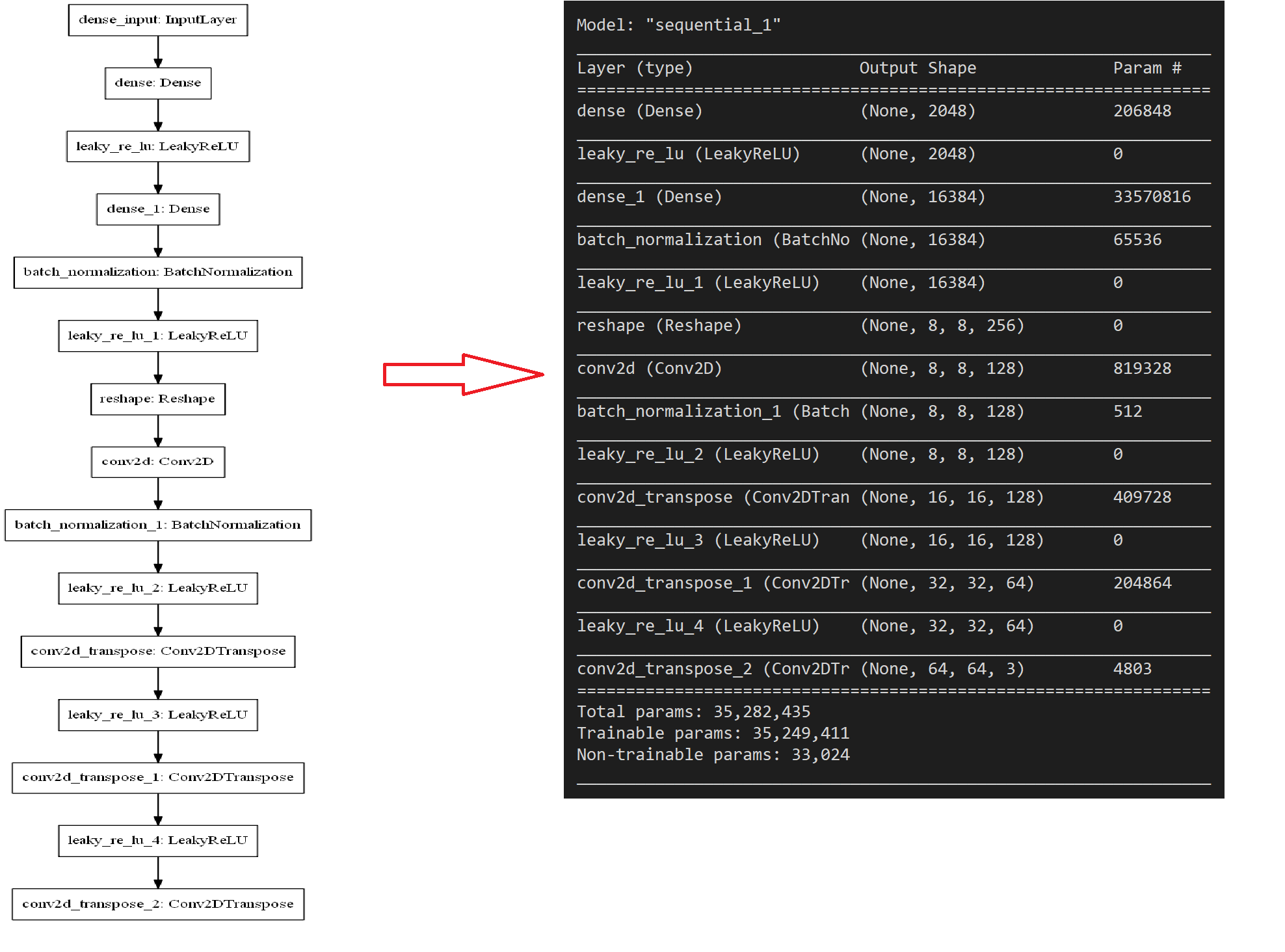
原理是我们通过全连接层将nosise的向量放大,然后在再使用反卷积等操作将其逐渐变成shape为((64,64,3))的图片。
def build_G():
"""
构建生成器
:return:
"""
model = Sequential()
# 全连接层 100 -> 2048
model.add(Dense(2048,input_dim = noise_dim))
# 激活函数
model.add(LeakyReLU(0.2))
# 全连接层 2048 -> 8 * 8 * 256
model.add(Dense(8 * 8 * 256))
# DN层
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
# 8 * 8 * 256 -> (8,8,256)
model.add(Reshape((8, 8, 256)))
# 卷积层 (8,8,256) -> (8,8,128)
model.add(Conv2D(128, kernel_size=5, padding='same'))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
# 反卷积层 (8,8,128) -> (16,16,128)
model.add(Conv2DTranspose(128, kernel_size=5, strides=2, padding='same'))
model.add(LeakyReLU(0.2))
# 反卷积层 (16,16,128) -> (32,32,64)
model.add(Conv2DTranspose(64, kernel_size=5, strides=2, padding='same'))
model.add(LeakyReLU(0.2))
# 反卷积层 (32,32,64) -> (64,64,3) = 图片
model.add(Conv2DTranspose(3, kernel_size=5, strides=2, padding='same', activation='tanh'))
return model
G = build_G()
可以发现,(G)网络并没有compile这一步,这是因为(G)网络的权重优化并不是直接优化的,而是通过GAN网络进行间接优化的。
构建D网络
D网络的结构示意图如下:
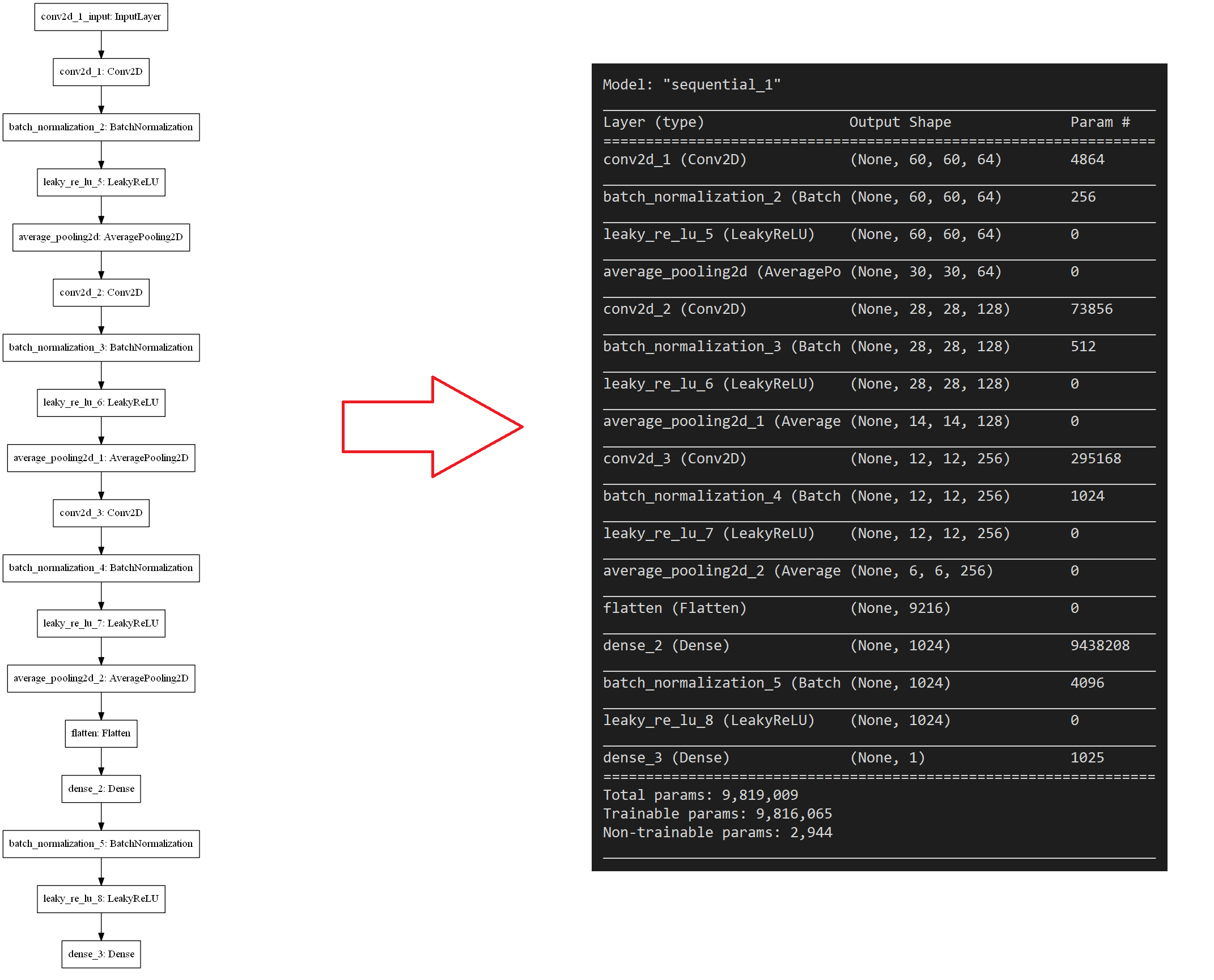
判别器网络就是一个寻常的CNN网络:
def build_D():
"""
构建判别器
:return:
"""
model = Sequential()
# 卷积层
model.add(Conv2D(64, kernel_size=5, padding='valid',input_shape = image_shape))
# BN层
model.add(BatchNormalization())
# 激活层
model.add(LeakyReLU(0.2))
# 平均池化层
model.add(AveragePooling2D(pool_size=2))
# 卷积层
model.add(Conv2D(128, kernel_size=3, padding='valid'))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(AveragePooling2D(pool_size=2))
model.add(Conv2D(256, kernel_size=3, padding='valid'))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(AveragePooling2D(pool_size=2))
# 将输入展平
model.add(Flatten())
# 全连接层
model.add(Dense(1024))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
# 最终输出1(true img) 0(fake img)的概率大小
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=Adam(learning_rate=0.0002, beta_1=0.5))
return model
D = build_D()
构建GAN网络
由前面的博客,我们知道,GAN网络由G网络和D网络组成,GAN网络的input为nosie,输出为图片真假的概率。因此它的网络结构示意图如下所示:

def build_gan():
"""
构建GAN网络
:return:
"""
# 冷冻判别器,也就是在训练的时候只优化G的网络权重,而对D保持不变
D.trainable = False
# GAN网络的输入
gan_input = Input(shape=(noise_dim,))
# GAN网络的输出
gan_out = D(G(gan_input))
# 构建网络
gan = Model(gan_input,gan_out)
# 编译GAN网络,使用Adam优化器,以及加上交叉熵损失函数(一般用于二分类)
gan.compile(loss='binary_crossentropy',optimizer=Adam(learning_rate=0.0002, beta_1=0.5))
return gan
GAN = build_gan()
关于GAN的小trick
我们会将真实的图片的lable标记为1,fake图片的lable标记为0,但是我们训练的时候可以使lable的值在一定的范围内浮动。关于更多的trick,可以参考这篇[GANs training tricks](https://zhuanlan.zhihu.com/p/76717276)。
def sample_noise(batch_size):
"""
随机产生正态分布(0,1)的noise
:param batch_size:
:return: 返回的shape为(batch_size,noise)
"""
return np.random.normal(size=(batch_size, noise_dim))
def smooth_pos_labels(y):
"""
使得true label的值的范围为[0.7,1.2]
:param y:
:return:
"""
return y - 0.3 + (np.random.random(y.shape) * 0.5)
def smooth_neg_labels(y):
"""
使得fake label的值的范围为[0.0,0.3]
:param y:
:return:
"""
return y + np.random.random(y.shape) * 0.3
训练
开始训练之前,我们还介绍一个函数,load_batch,因为我们训练图片不可能说一次将图片全部进行训练而是分批次进行训练(full batch需要大量的内存空间),而load_batch函数就行按批次加载图片。
def load_batch(data, batch_size,index):
"""
按批次加载图片
:param data: 图片数据集
:param batch_size: 批次大小
:param index: 批次序号
:return:
"""
return data[index*batch_size: (index+1)*batch_size]
然后我们就需要定义(train)函数了:
def train(epochs=100, batch_size=64):
"""
训练函数
:param epochs: 训练的次数
:param batch_size: 批尺寸
:return:
"""
# 判别器损失
discriminator_loss = 0
# 生成器损失
generator_loss = 0
# img_dataset.shape[0] / batch_size 代表这个数据可以分为几个批次进行训练
n_batches = int(img_dataset.shape[0] / batch_size)
for i in range(epochs):
for index in range(n_batches):
# 按批次加载数据
x = load_batch(img_dataset, batch_size,index)
# 产生noise
noise = sample_noise(batch_size)
# G网络产生图片
generated_images = G.predict(noise)
# 产生为1的标签
y_real = np.ones(batch_size)
# 将1标签的范围变成[0.7 , 1.2]
y_real = smooth_pos_labels(y_real)
# 产生为0的标签
y_fake = np.zeros(batch_size)
# 将0标签的范围变成[0.0 , 0.3]
y_fake = smooth_neg_labels(y_fake)
# 训练真图片loss
d_loss_real = D.train_on_batch(x, y_real)
# 训练假图片loss
d_loss_fake = D.train_on_batch(generated_images, y_fake)
discriminator_loss = d_loss_real + d_loss_fake
# 产生为1的标签
y_real = np.ones(batch_size)
# 训练GAN网络,input = fake_img ,label = 1
generator_loss = GAN.train_on_batch(noise, y_real)
print('[Epoch {0}]. Discriminator loss : {1}. Generator_loss: {2}.'.format(i, discriminator_loss, generator_loss))
# 随机产生(25,100)的noise
test_noise = sample_noise(25)
# 使用G网络生成25张图偏
test_images = G.predict(test_noise)
# show 预测 img
show_images(test_images,i)
开始训练:
train(epochs=500, batch_size=32)
最后就进入到了漫长的等待结果的时间了。
总结
项目地址:GitHub