1.XML解析技术概述
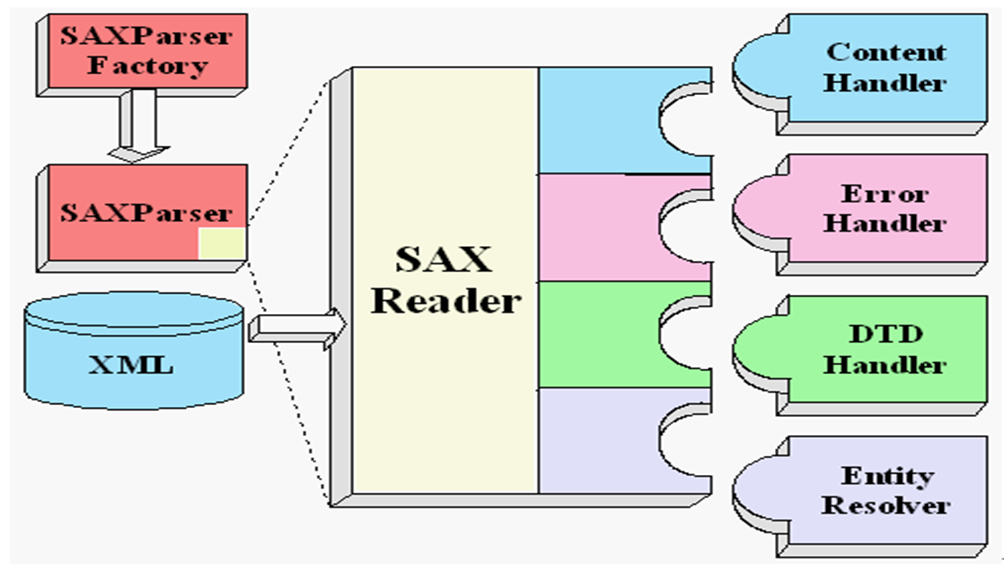
SAXParserFactory spf = SAXParserFactory.newInstance();
SAXParser sp = spf.newSAXParser();
XMLReader xmlReader = sp.getXMLReader();
xmlReader.setContentHandler(new BookParserHandler());
xmlReader.parse("book.xml");
1.2.DOM4J解析XML文档
1).读取XML文件,获得document对象
SAXReader reader = new SAXReader();
Document document = reader.read(new File("input.xml"));
2).解析XML形式的文本,得到document对象.
String text = "<members></members>";
Document document
= DocumentHelper.parseText(text);
3).主动创建document对象.
Document document
= DocumentHelper.createDocument();
//创建根节点
Element root = document.addElement("members");
节点对象
Element root = document.getRootElement();
Element element=node.element(“书名");
String text=node.getText();
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();) {
Element elm = (Element) it.next();
// do something
}
for(Iterator it=root.elementIterator();it.hasNext();){
Element element = (Element) it.next();
// do something
}
Element ageElm = newMemberElm.addElement("age");
element.setText("29");
//childElm是待删除的节点,parentElm是其父节点
parentElm.remove(childElm);
Element contentElm = infoElm.addElement("content");
contentElm.addCDATA(diary.getContent());
Element root=document.getRootElement();
//属性名name
Attribute attribute=root.attribute("size");
String text=attribute.getText();
Attribute attribute=root.attribute("size");
root.remove(attribute);
Element root=document.getRootElement();
for(Iterator it=root.attributeIterator();it.hasNext();){
Attribute attribute = (Attribute) it.next();
String text=attribute.getText();
System.out.println(text);
}
newMemberElm.addAttribute("name", "sitinspring");
Attribute attribute=root.attribute("name");
attribute.setText("sitinspring");
XMLWriter writer = new XMLWriter(new FileWriter("output.xml"));
writer.write(document);
writer.close();
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定XML编码
format.setEncoding("GBK");
XMLWriter
writer = new XMLWriter(newFileWriter("output.xml"),format);
writer.write(document);
writer.close();
1.2.2.Dom4j在指定位置插入节点
Element aaa = DocumentHelper.createElement("aaa");
aaa.setText("aaa");
List list = root.element("书").elements();
list.add(1, aaa);
//更新document
1.2.3.字符串与XML的转换
String text = "<members>
<member>sitinspring</member></members>";
Document document
= DocumentHelper.parseText(text);
SAXReader reader = new SAXReader();
Document document = reader.read(new
File("input.xml"));
Element root=document.getRootElement();
String docXmlText=document.asXML();
String
rootXmlText=root.asXML();
Element memberElm=root.element("member");
String memberXmlText=memberElm.asXML();