前面的话
集合、字典和散列表可以存储不重复的值。在集合中,我们感兴趣的是每个值本身,并把它当作主要元素。在字典中,我们用[键,值]的形式来存储数据。在散列表中也是一样(也是以[键,值]对的形式来存储数据)。但是两种数据结构的实现方式略有不同,本文将详细介绍字典和散列表这两种数据结构
字典
集合表示一组互不相同的元素(不重复的元素)。在字典中,存储的是[键,值]对,其中键名是用来查询特定元素的。字典和集合很相似,集合以[值,值]的形式存储元素,字典则是以[键,值]的形式来存储元素。字典也称作映射
【创建字典】
与Set类相似,ECMAScript 6同样包含了一个Map类的实现,即我们所说的字典
下面将要实现的类就是以ECMAScript 6中Map类的实现为基础的。它和Set类很相似(但不同于存储[值,值]对的形式,我们将要存储的是[键,值]对)
这是我们的Dictionary类的骨架:
function Dictionary() { var items = {}; }
与Set类类似,我们将在一个Object的实例而不是数组中存储元素。 然后,我们需要声明一些映射/字典所能使用的方法
set(key,value):向字典中添加新元素。 remove(key):通过使用键值来从字典中移除键值对应的数据值。 has(key):如果某个键值存在于这个字典中,则返回true,反之则返回false。 get(key):通过键值查找特定的数值并返回。 clear():将这个字典中的所有元素全部删除。 size():返回字典所包含元素的数量。与数组的length属性类似。 keys():将字典所包含的所有键名以数组形式返回。 values():将字典所包含的所有数值以数组形式返回。
【has】
首先来实现has(key)方法。之所以要先实现这个方法,是因为它会被set和remove等其他方法调用。这个方法的实现和之前在Set类中的实现是一样的。使用JavaScript中的in操作符来验证一个key是否是items对象的一个属性。可以通过如下代码来实现:
this.has = function(key) { return key in items; }
【set】
该方法接受一个key和一个value作为参数。我们直接将value设为items对象的key属性的值。它可以用来给字典添加一个新的值,或者用来更新一个已有的值
this.set = function(key, value) { items[key] = value; //{1} }
【remove】
它和Set类中的remove方法很相似,唯一的不同点在于我们将先搜索key(而不是value),然后我们可以使用JavaScript的delete操作符来从items对象中移除key属性
this.remove = function(key) { if (this.has(key)) { delete items[key]; return true; } return false; }
【get】
get方法首先会验证我们想要检索的值是否存在(通过查找key值),如果存在,将返回该值, 反之将返回一个undefined值
this.get = function(key) { return this.has(key) ? items[key] : undefined; };
【values】
首先,我们遍历items对象的所有属性值(行{1})。为了确定值存在,我们使用has函数来验证key确实存在,然后将它的值加入values数组(行{2})。最后,我们就能返回所有找到的值。这个方法以数组的形式返回字典中所有values实例的值:
this.values = function() { var values = {}; for (var k in items) { //{1} if (this.has(k)) { values.push(items[k]); //{2} } } return values; };
【clear】
this.clear = function(){ items = {}; };
【size】
this.size = function(){ return Object.keys(items).length; };
【keys】
keys方法返回在Dictionary类中所有用于标识值的键名。要取出一个JavaScript对象中所有的键名,可以把这个对象作为参数传入Object类的keys方法,如下:
this.keys = function() { return Object.keys(items); };
【items】
下面来验证items属性的输出值。我们可以实现一个返回items变量的方法,叫作getItems:
this.getItems = function() { return items; }
【完整代码】
Dictionary类的完整代码如下所示
function Dictionary(){ var items = {}; this.set = function(key, value){ items[key] = value; //{1} }; this.delete = function(key){ if (this.has(key)){ delete items[key]; return true; } return false; }; this.has = function(key){ return items.hasOwnProperty(key); //return value in items; }; this.get = function(key) { return this.has(key) ? items[key] : undefined; }; this.clear = function(){ items = {}; }; this.size = function(){ return Object.keys(items).length; }; this.keys = function(){ return Object.keys(items); }; this.values = function(){ var values = []; for (var k in items) { if (this.has(k)) { values.push(items[k]); } } return values; }; this.each = function(fn) { for (var k in items) { if (this.has(k)) { fn(k, items[k]); } } }; this.getItems = function(){ return items; } }
【使用Dictionary类】
首先,我们来创建一个Dictionary类的实例,然后给它添加三条电子邮件地址。我们将会使用这个dictionary实例来实现一个电子邮件地址簿。使用我们创建的类来执行如下代码:
var dictionary = new Dictionary(); dictionary.set('Gandalf', 'gandalf@email.com'); dictionary.set('John', 'johnsnow@email.com'); dictionary.set('Tyrion', 'tyrion@email.com');
如果执行了如下代码,输出结果将会是true:
console.log(dictionary.has('Gandalf'));
下面的代码将会输出3,因为我们向字典实例中添加了三个元素:
console.log(dictionary.size());
现在,执行下面的几行代码:
console.log(dictionary.keys()); console.log(dictionary.values()); console.log(dictionary.get('Tyrion'));
输出结果分别如下所示:
["Gandalf", "John", "Tyrion"] ["gandalf@email.com", "johnsnow@email.com", "tyrion@email.com"] tyrion@email.com
最后,再执行几行代码:
dictionary.remove('John');
再执行下面的代码:
console.log(dictionary.keys());
console.log(dictionary.values());
console.log(dictionary.getItems());
输出结果如下所示:
["Gandalf", "Tyrion"] ["gandalf@email.com", "tyrion@email.com"] Object {Gandalf: "gandalf@email.com", Tyrion: "tyrion@email.com"}
移除了一个元素后,现在的dictionary实例中只包含两个元素了
散列表
下面将详细介绍HashTable类,也叫HashMap类,是Dictionary类的一种散列表实现方式
散列算法的作用是尽可能快地在数据结构中找到一个值。如果要在数据结构中获得一个值(使用get方法),需要遍历整个数据结构来找到它。如果使用散列函数,就知道值的具体位置,因此能够快速检索到该值。散列函数的作用是给定一个键值,然后返回值在表中的地址
举个例子,我们继续使用在前面使用的电子邮件地址簿。我们将要使用最常见的散列函数——“lose lose”散列函数,方法是简单地将每个键值中的每个字母的ASCII值相加
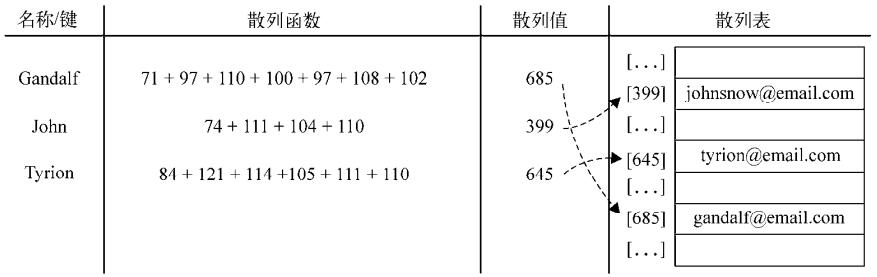
【创建散列表】
我们将使用数组来表示我们的数据结构,从搭建类的骨架开始:
function HashTable(){ var table = []; }
然后,给类添加一些方法。我们给每个类实现三个基础的方法
put(key,value):向散列表增加一个新的项(也能更新散列表)。 remove(key):根据键值从散列表中移除值。 get(key):返回根据键值检索到的特定的值。
在实现这三个方法之前,要实现的第一个方法是散列函数,它是HashTable类中的一个私有方法:
var loseloseHashCode = function (key) { var hash = 0; //{1} for (var i = 0; i < key.length; i++) { //{2} hash += key.charCodeAt(i); //{3} } return hash % 37; //{4} };
给定一个key参数,就能根据组成key的每个字符的ASCII码值的和得到一个数字。所以,首先需要一个变量来存储这个总和(行{1})。然后,遍历key(行{2})并将从ASCII表中查到的每个字符对应的ASCII值加到hash变量中(可以使用JavaScript的String类中的charCodeAt方法——行{3})。最后,返回hash值。为了得到比较小的数值,我们会使用hash值和一个任意数做除法的余数(mod)
【put】
现在,有了散列函数,我们就可以实现put方法了:
this.put = function(key, value) { var position = loseloseHashCode(key); //{5} console.log(position + ' - ' + key); //{6} table[position] = value; //{7} };
首先,根据给定的key和所创建的散列函数计算出它在表中的位置(行{5})。为了便于展示信息,我们将计算出的位置输出至控制台(行{6})。由于它不是必需的,我们也可以将这行代码移除。然后要做的,是将value参数添加到用散列函数计算出的对应的位置上(行{7})
【get】
从HashTable实例中查找一个值也很简单。为此,将会实现一个get方法。首先,我们会使用所创建的散列函数来求出给定key所对应的位置。这个函数会返回值的位置,因此我们所要做的就是根据这个位置从数组table中获得这个值。
this.get = function (key) { return table[loseloseHashCode(key)]; };
【remove】
要从HashTable实例中移除一个元素,只需要求出元素的位置(可以使用散列函数来获取)并赋值为undefined。
对于HashTable类来说,我们不需要像ArrayList类一样从table数组中将位置也移除。由于元素分布于整个数组范围内,一些位置会没有任何元素占据,并默认为undefined值。我们也不能将位置本身从数组中移除(这会改变其他元素的位置),否则,当下次需要获得或移除一个元素的时候,这个元素会不在我们用散列函数求出的位置上
this.remove = function(key) { table[loseloseHashCode(key)] = undefined; };
【完整代码】
HashTable类的完整代码如下所示
function HashTable() { var table = []; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var djb2HashCode = function (key) { var hash = 5381; for (var i = 0; i < key.length; i++) { hash = hash * 33 + key.charCodeAt(i); } return hash % 1013; }; var hashCode = function (key) { return loseloseHashCode(key); }; this.put = function (key, value) { var position = hashCode(key); console.log(position + ' - ' + key); table[position] = value; }; this.get = function (key) { return table[hashCode(key)]; }; this.remove = function(key){ table[hashCode(key)] = undefined; }; this.print = function () { for (var i = 0; i < table.length; ++i) { if (table[i] !== undefined) { console.log(i + ": " + table[i]); } } }; }
【使用HashTable类】
下面执行一些代码来测试HashTable类:
var hash = new HashTable(); hash.put('Gandalf', 'gandalf@email.com'); hash.put('John', 'johnsnow@email.com'); hash.put('Tyrion', 'tyrion@email.com');
执行上述代码,会在控制台中获得如下输出:
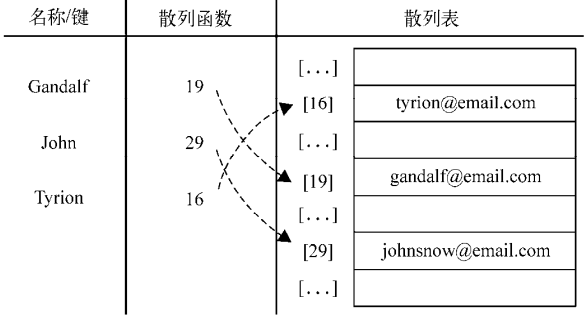
19 - Gandalf 29 - John 16 - Tyrion
下面的图表展现了包含这三个元素的HashTable数据结构:
现在来测试get方法:
console.log(hash.get('Gandalf')); console.log(hash.get('Loiane'));
获得如下的输出:
gandalf@email.com
undefined
由于Gandalf是一个在散列表中存在的键,get方法将会返回它的值。而由于Loiane是一个不存在的键,当我们试图在数组中根据位置获取值的时候(一个由散列函数生成的位置),返回值将会是undefined(即不存在)
然后,我们试试从散列表中移除Gandalf:
hash.remove('Gandalf'); console.log(hash.get('Gandalf'));
由于Gandalf不再存在于表中,hash.get('Gandalf')方法将会在控制台上给出undefined的输出结果
【散列集合】
在一些编程语言中,还有一种叫作散列集合的实现。散列集合由一个集合构成,但是插入、移除或获取元素时,使用的是散列函数。我们可以重用本章中实现的所有代码来实现散列集合,不同之处在于,不再添加键值对,而是只插入值而没有键。例如,可以使用散列集合来存储所有的英语单词(不包括它们的定义)。和集合相似,散列集合只存储唯一的不重复的值
处理冲突
有时候,一些键会有相同的散列值。不同的值在散列表中对应相同位置的时候,我们称其为冲突。例如,我们看看下面的代码会得到怎样的输出结果:
var hash = new HashTable(); hash.put('Gandalf', 'gandalf@email.com'); hash.put('John', 'johnsnow@email.com'); hash.put('Tyrion', 'tyrion@email.com'); hash.put('Aaron', 'aaron@email.com'); hash.put('Donnie', 'donnie@email.com'); hash.put('Ana', 'ana@email.com'); hash.put('Jonathan', 'jonathan@email.com'); hash.put('Jamie', 'jamie@email.com'); hash.put('Sue', 'sue@email.com'); hash.put('Mindy', 'mindy@email.com'); hash.put('Paul', 'paul@email.com'); hash.put('Nathan', 'nathan@email.com');
输出结果如下:
19 - Gandalf 29 - John 16 - Tyrion 16 - Aaron 13 - Donnie 13 - Ana 5 - Jonathan 5 - Jamie 5 - Sue 32 - Mindy 32 - Paul 10 – Nathan
Tyrion和Aaron有相同的散列值(16)。Donnie和Ana有相同的散列值(13),Jonathan、Jamie和Sue有相同的散列值(5),Mindy和Paul也有相同的散列值(32)
那HashTable实例会怎样呢?执行之前的代码后散列表中会有哪些值呢?为了获得结果,我们来实现一个叫作print的辅助方法,它会在控制台上输出HashTable中的值:
this.print = function() { for (var i = 0; i < table.length; ++i) { //{1} if (table[i] !== undefined) { //{2} console.log(i + ": " + table[i]);//{3} } } };
首先,遍历数组中的所有元素(行{1})。当某个位置上有值的时候(行{2}),会在控制台上输出位置和对应的值(行{3})。现在来使用这个方法:
hash.print();
在控制台上得到如下的输出结果:
5:sue@email.com 10:nathan@email.com 13:ana@email.com 16:aaron@email.com 19:gandalf@email.com 29:johnsnow@email.com 32:paul@email.com
Jonathan、Jamie和Sue有相同的散列值,也就是5。由于Sue是最后一个被添加的,Sue将是在HashTable实例中占据位置5的元素。首先,Jonathan会占据这个位置,然后Jamie会覆盖它,然后Sue会再次覆盖。这对于其他发生冲突的元素来说也是一样的。
使用一个数据结构来保存数据的目的显然不是去丢失这些数据,而是通过某种方法将它们全部保存起来。因此,当这种情况发生的时候就要去解决它。处理冲突有几种方法:分离链接、线性探查和双散列法
【分离链接】
分离链接法包括为散列表的每一个位置创建一个链表并将元素存储在里面。它是解决冲突的最简单的方法,但是它在HashTable实例之外还需要额外的存储空间
例如,我们在之前的测试代码中使用分离链接的话,输出结果将会是这样:
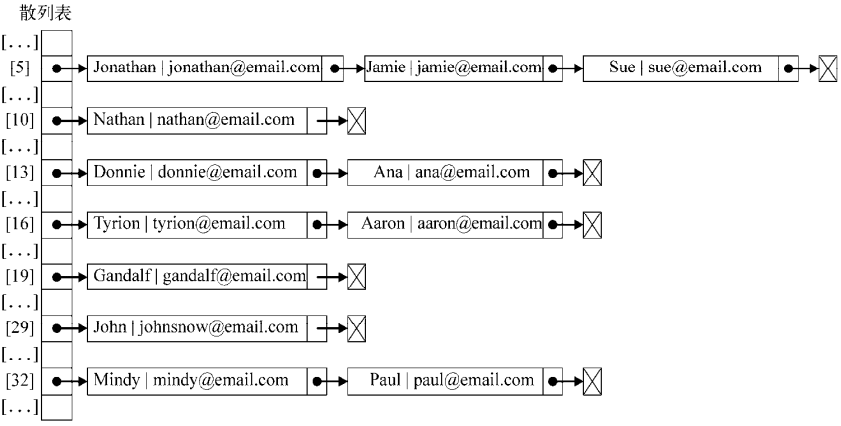
在位置5上,将会有包含三个元素的LinkedList实例;在位置13、16和32上,将会有包含两个元素的LinkedList实例;在位置10、19和29上,将会有包含单个元素的LinkedList实例
对于分离链接和线性探查来说,只需要重写三个方法:put、get和remove。这三个方法在每种技术实现中都是不同的
为了实现一个使用了分离链接的HashTable实例,我们需要一个新的辅助类来表示将要加入LinkedList实例的元素。我们管它叫ValuePair类(在HashTable类内部定义):
var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } };
这个类只会将key和value存储在一个Object实例中。我们也重写了toString方法,以便之后在浏览器控制台中输出结果
我们来实现第一个方法,put方法,代码如下:
this.put = function(key, value){ var position = loseloseHashCode(key); if (table[position] == undefined) { //{1} table[position] = new LinkedList(); } table[position].append(new ValuePair(key, value)); //{2} };
在这个方法中,将验证要加入新元素的位置是否已经被占据(行{1})。如果这个位置是第一次被加入元素,我们会在这个位置上初始化一个LinkedList类的实例(你已经在第5章中学习过)。然后,使用append方法向LinkedList实例中添加一个ValuePair实例(键和值)(行{2})
然后,我们实现用来获取特定值的get方法:
this.get = function(key) { var position = loseloseHashCode(key); if (table[position] !== undefined){ //{3} //遍历链表来寻找键/值 var current = table[position].getHead(); //{4} while(current.next){ //{5} if (current.element.key === key){ //{6} return current.element.value; //{7} } current = current.next; //{8} } //检查元素在链表第一个或最后一个节点的情况 if (current.element.key === key){ //{9} return current.element.value; } } return undefined; //{10} };
我们要做的第一个验证,是确定在特定的位置上是否有元素存在(行{3})。如果没有,则返回一个undefined表示在HashTable实例中没有找到这个值(行{10})。如果在这个位置上有值存在,我们知道这是一个LinkedList实例。现在要做的是遍历这个链表来寻找我们需要的元素。在遍历之前先要获取链表表头的引用(行{4}),然后就可以从链表的头部遍历到尾部(行{5},current.next将会是null)。
Node链表包含next指针和element属性。而element属性又是ValuePair的实例,所以它又有value和key属性。可以通过current.element.next来获得Node链表的key属性,并通过比较它来确定它是否就是我们要找的键(行{6})。(这就是要使用ValuePair这个辅助类来存储元素的原因。我们不能简单地存储值本身,这样就不能确定哪个值对应着特定的键。)如果key值相同,就返回Node的值(行{7});如果不相同,就继续遍历链表,访问下一个节点(行{8})。
如果要找的元素是链表的第一个或最后一个节点,那么就不会进入while循环的内部。因此,需要在行{9}处理这种特殊的情况
使用分离链接法从HashTable实例中移除一个元素和之前在本章实现的remove方法有一些不同。现在使用的是链表,我们需要从链表中移除一个元素。来看看remove方法的实现:
this.remove = function(key){ var position = loseloseHashCode(key); if (table[position] !== undefined){ var current = table[position].getHead(); while(current.next){ if (current.element.key === key){ //{11} table[position].remove(current.element); //{12} if (table[position].isEmpty()){ //{13} table[position] = undefined; //{14} } return true; //{15} } current = current.next; } // 检查是否为第一个或最后一个元素 if (current.element.key === key){ //{16} table[position].remove(current.element); if (table[position].isEmpty()){ table[position] = undefined; } return true; } } return false; //{17} };
在remove方法中,我们使用和get方法一样的步骤找到要找的元素。遍历LinkedList实例时,如果链表中的current元素就是要找的元素(行{11}),使用remove方法将其从链表中移除。然后进行一步额外的验证:如果链表为空了(行{13}——链表中不再有任何元素了),就将散列表这个位置的值设为undefined(行{14}),这样搜索一个元素或打印它的内容的时候,就可以跳过这个位置了。最后,返回true表示这个元素已经被移除(行{15})或者在最后返回false表示这个元素在散列表中不存在(行{17})。同样,需要和get方法一样,处理元素在第一个或最后一个的情况(行{16})
重写了这三个方法后,我们就拥有了一个使用了分离链接法来处理冲突的HashMap实例
分离链接的HashMap的完整代码如下所示
function HashTableSeparateChaining(){ var table = []; var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } }; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var hashCode = function(key){ return loseloseHashCode(key); }; this.put = function(key, value){ var position = hashCode(key); console.log(position + ' - ' + key); if (table[position] == undefined) { table[position] = new LinkedList(); } table[position].append(new ValuePair(key, value)); }; this.get = function(key) { var position = hashCode(key); if (table[position] !== undefined && !table[position].isEmpty()){ //iterate linked list to find key/value var current = table[position].getHead(); do { if (current.element.key === key){ return current.element.value; } current = current.next; } while(current); } return undefined; }; this.remove = function(key){ var position = hashCode(key); if (table[position] !== undefined){ //iterate linked list to find key/value var current = table[position].getHead(); do { if (current.element.key === key){ table[position].remove(current.element); if (table[position].isEmpty()){ table[position] = undefined; } return true; } current = current.next; } while(current); } return false; }; this.print = function() { for (var i = 0; i < table.length; ++i) { if (table[i] !== undefined) { console.log(table[i].toString()); } } }; }
【线性探查】
另一种解决冲突的方法是线性探查。当想向表中某个位置加入一个新元素的时候,如果索引为index的位置已经被占据了,就尝试index+1的位置。如果index+1的位置也被占据了,就尝试index+2的位置,以此类推
继续实现需要重写的三个方法。第一个是put方法:
this.put = function(key, value){ var position = loseloseHashCode(key); // {1} if (table[position] == undefined) { // {2} table[position] = new ValuePair(key, value); // {3} } else { var index = ++position; // {4} while (table[index] != undefined){ // {5} index++; // {6} } table[index] = new ValuePair(key, value); // {7} } };
和之前一样,先获得由散列函数生成的位置(行{1}),然后验证这个位置是否有元素存在(如果这个位置被占据了,将会通过行{2}的验证)。如果没有元素存在,就在这个位置加入新元素(行{3}——一个ValuePair的实例)
如果这个位置已经被占据了,需要找到下一个没有被占据的位置(position的值是undefined),因此我们声明一个index变量并赋值为position+1(行{4}——在变量名前使用自增运算符++会先递增变量值然后再将其赋值给index)。然后验证这个位置是否被占据(行{5}),如果被占据了,继续将index递增(行{6}),直到找到一个没有被占据的位置。然后要做的,就是将值分配到这个位置(行{7})
如果再次执行前面实例中插入数据的代码,下图展示使用了线性探查的散列表的最终结果:

让我们来模拟一下散列表中的插入操作
1、试着插入Gandalf。它的散列值是19,由于散列表刚刚被创建,位置19还是空的——可以在这里插入数据
2、试着在位置29插入John。它也是空的,所以可以插入这个姓名
3、试着在位置16插入Tyrion。它是空的,所以可以插入这个姓名
4、试着插入Aaron,它的散列值也是16。位置16已经被Tyrion占据了,所以需要检查索引值为position+1的位置(16+1)。位置17是空的,所以可以在位置17插入Aaron
5、接着,试着在位置13插入Donnie。它是空的,所以可以插入这个姓名
6、想在位置13插入Ana,但是这个位置被占据了。因此在位置14进行尝试,它是空的,所以可以在这里插入姓名
7、然后,在位置5插入Jonathan,这个位置是空的,所以可以插入这个姓名
8、试着在位置5插入Jamie,但是这个位置被占了。所以跳至位置6,这个位置是空的,因此可以在这个位置插入姓名
9、试着在位置5插入Sue,但是位置被占据了。所以跳至位置6,但也被占了。接着跳至位置7,这里是空的,所以可以在这里插入姓名。以此类推
现在插入了所有的元素,下面实现get方法来获取它们的值
this.get = function(key) { var position = loseloseHashCode(key); if (table[position] !== undefined){ //{8} if (table[position].key === key) { //{9} return table[position].value; //{10} } else { var index = ++position; while (table[index] === undefined || table[index].key !== key){ //{11} index++; } if (table[index].key === key) { //{12} return table[index].value; //{13} } } } return undefined; //{14} };
要获得一个键对应的值,先要确定这个键存在(行{8})。如果这个键不存在,说明要查找的值不在散列表中,因此可以返回undefined(行{14})。如果这个键存在,需要检查我们要找的值是否就是这个位置上的值(行{9})。如果是,就返回这个值(行{10})。
如果不是,就在散列表中的下一个位置继续查找,直到找到一个键值与我们要找的键值相同的元素(行{11})。然后,验证一下当前项就是我们要找的项(行{12}——只是为了确认一下)并且将它的值返回(行{13})。
我们无法确定要找的元素实际上在哪个位置,这就是使用ValuePair来表示HashTable元素的原因
remove方法和get方法基本相同,不同之处在于行{10}和{13},它们将会由下面的代码代替:
table[index]=undefined;
要移除一个元素,只需要给其赋值为undefined,来表示这个位置不再被占据并且可以在必要时接受一个新元素
线性探查的HashTable的完整代码如下所示
function HashLinearProbing(){ var table = []; var ValuePair = function(key, value){ this.key = key; this.value = value; this.toString = function() { return '[' + this.key + ' - ' + this.value + ']'; } }; var loseloseHashCode = function (key) { var hash = 0; for (var i = 0; i < key.length; i++) { hash += key.charCodeAt(i); } return hash % 37; }; var hashCode = function(key){ return loseloseHashCode(key); }; this.put = function(key, value){ var position = hashCode(key); console.log(position + ' - ' + key); if (table[position] == undefined) { table[position] = new ValuePair(key, value); } else { var index = ++position; while (table[index] != undefined){ index++; } table[index] = new ValuePair(key, value); } }; this.get = function(key) { var position = hashCode(key); if (table[position] !== undefined){ if (table[position].key === key) { return table[position].value; } else { var index = ++position; while (table[index] !== undefined && (table[index] && table[index].key !== key)){ index++; } if (table[index] && table[index].key === key) { return table[index].value; } } } else { //search for possible deleted value var index = ++position; while (table[index] == undefined || index == table.length || (table[index] !== undefined && table[index] && table[index].key !== key)){ index++; } if (table[index] && table[index].key === key) { return table[index].value; } } return undefined; }; this.remove = function(key){ var position = hashCode(key); if (table[position] !== undefined){ if (table[position].key === key) { table[position] = undefined; } else { var index = ++position; while (table[index] === undefined || table[index].key !== key){ index++; } if (table[index].key === key) { table[index] = undefined; } } } }; this.print = function() { for (var i = 0; i < table.length; ++i) { if (table[i] !== undefined) { console.log(i + ' -> ' + table[i].toString()); } } }; }
【更好的散列函数】
“loselose”散列函数并不是一个表现良好的散列函数,因为它会产生太多的冲突。如果使用这个函数的话,会产生各种各样的冲突。一个表现良好的散列函数是由几个方面构成的:插入和检索元素的时间(即性能),当然也包括较低的冲突可能性
另一个可以实现的比“loselose”更好的散列函数是djb2:
var djb2HashCode = function (key) { var hash = 5381; //{1} for (var i = 0; i < key.length; i++) { //{2} hash = hash * 33 + key.charCodeAt(i); //{3} } return hash % 1013; //{4} };
它包括初始化一个hash变量并赋值为一个质数(行{1}——大多数实现都使用5381),然后迭代参数key(行{2}),将hash与33相乘(用来当作一个魔力数),并和当前迭代到的字符的ASCII码值相加(行{3})
最后,我们将使用相加的和与另一个随机质数(比我们认为的散列表的大小要大——在本例中,我们认为散列表的大小为1000)相除的余数。
如果再次执行前面实例中插入数据的代码,这将是使用djb2HashCode代替loseloseHashCode的最终结果:
798-Gandalf 838-John 624-Tyrion 215-Aaron 278-Donnie 925-Ana 288-Jonathan 962-Jamie 502-Sue 804-Mindy 54-Paul 223-Nathan
没有冲突!这并不是最好的散列函数,但这是最被社区推荐的散列函数之一
ES6
ECMAScript 2015新增了Map类。我们可以基于ES6的Map类开发我们的Dictionary类
看看原生的Map类怎么用。还是用我们原来测试Dictionary类的例子:
var map = new Map(); map.set('Gandalf', 'gandalf@email.com'); map.set('John', 'johnsnow@email.com'); map.set('Tyrion', 'tyrion@email.com'); console.log(map.has('Gandalf')); //输出true console.log(map.size); //输出3 console.log(map.keys()); //输出["Gandalf", "John", "Tyrion"] console.log(map.values()); //输出["gandalf@email.com", "johnsnow@email.com", "tyrion@email.com"] console.log(map.get('Tyrion')); //输出tyrion@email.com
和Dictionary类不同,ES6的Map类的values方法和keys方法都返回Iterator,而不是值或键构成的数组。另一个区别是,我们实现的size方法返回字典中存储的值的个数,而ES6的Map类则有一个size属性
删除map中的元素可以用delete方法:
map.delete('John');
clear方法会重置map数据结构,这跟我们在Dictionary类里实现的一样
除了Set和Map这两种新的数据结构,ES6还增加了它们的弱化版本,WeakSet和WeakMap。基本上,Map和Set与其弱化版本之间仅有的区别是:
1、WeakSet或WeakMap类没有entries、keys和values等方法;
2、只能用对象作为键
创建和使用这两个类主要是为了性能。WeakSet和WeakMap是弱化的(用对象作为键),没有强引用的键。这使得JavaScript的垃圾回收器可以从中清除整个入口。另一个优点是,必须用键才可以取出值。这些类没有entries、keys和values等迭代器方法,因此,除非知道键,否则没有办法取出值
使用WeakMap类的例子如下:
var map = new WeakMap(); var ob1 = {name:'Gandalf'}, //{1} ob2 = {name:'John'}, ob3 = {name:'Tyrion'}; map.set(ob1, 'gandalf@email.com'); //{2} map.set(ob2, 'johnsnow@email.com'); map.set(ob3, 'tyrion@email.com'); console.log(map.has(ob1)); //{3} 输出true console.log(map.get(ob3)); //{4} 输出tyrion@email.com map.delete(ob2); //{5}
WeakMap类也可以用set方法,但不能使用数字、字符串、布尔值等基本数据类型,需要将名字转换为对象(行{1}和行{2})。搜索(行{3})、读取(行{4})和删除值(行{5}),也要传入作为键的对象。同样的逻辑也适用于WeakSet类