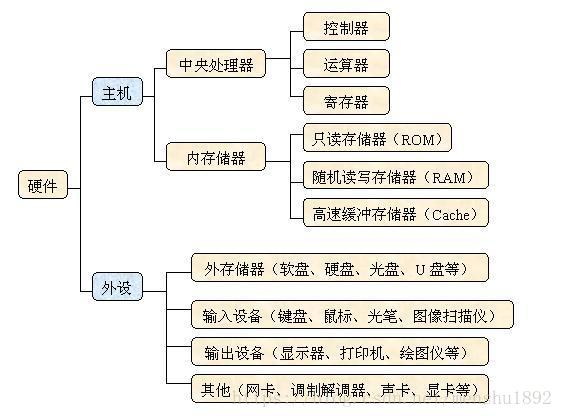
先看下计算机硬件的组成,这节主要是讲中央处理器
CPU简介
CPU内部结构图
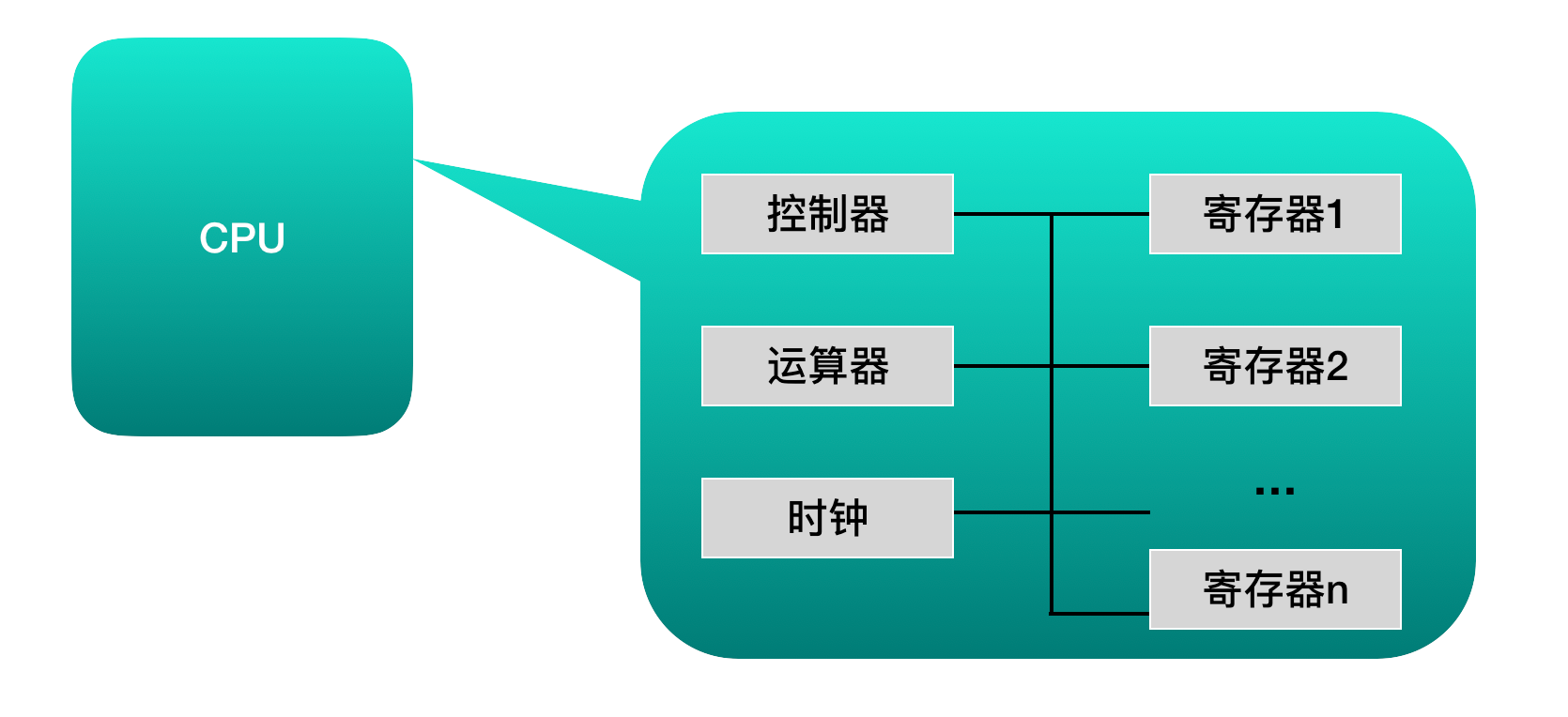
・ 寄存器是中央处理器内的组成部分。它们可以用来暂存指令、数据和地址。可以将其看作是内存 的一种。根据种类的不同,一个CPU内部会有20 - 100个寄存器。
・ 控制器负责把内存上的指令、数据读入寄存器,并根据指令的结果控制计算机
・ 运算器负责运算从内存中读入寄存器的数据
・ 时钟 负责发出CPU开始计时的时钟信号
作为一个程序员,我们要关心的是寄存器的原理
种类 功能
累加寄存器 存储运行的数据和运算后的数据。
标志寄存器 用于反应处理器的状态和运算结果的某些特征以及控制指令的执行。
程序计数器 程序计数器是用于存放下一条指令所在单元的地址的地方。
基址寄存器 存储数据内存的起始位置
变址寄存器 存储基址寄存器的相对地址
通用寄存器 存储任意数据
指令寄存器 储存正在被运行的指令,CPU内部使用,程序员无法对该寄存器进行读写
栈寄存器 存储栈区域的起始位置

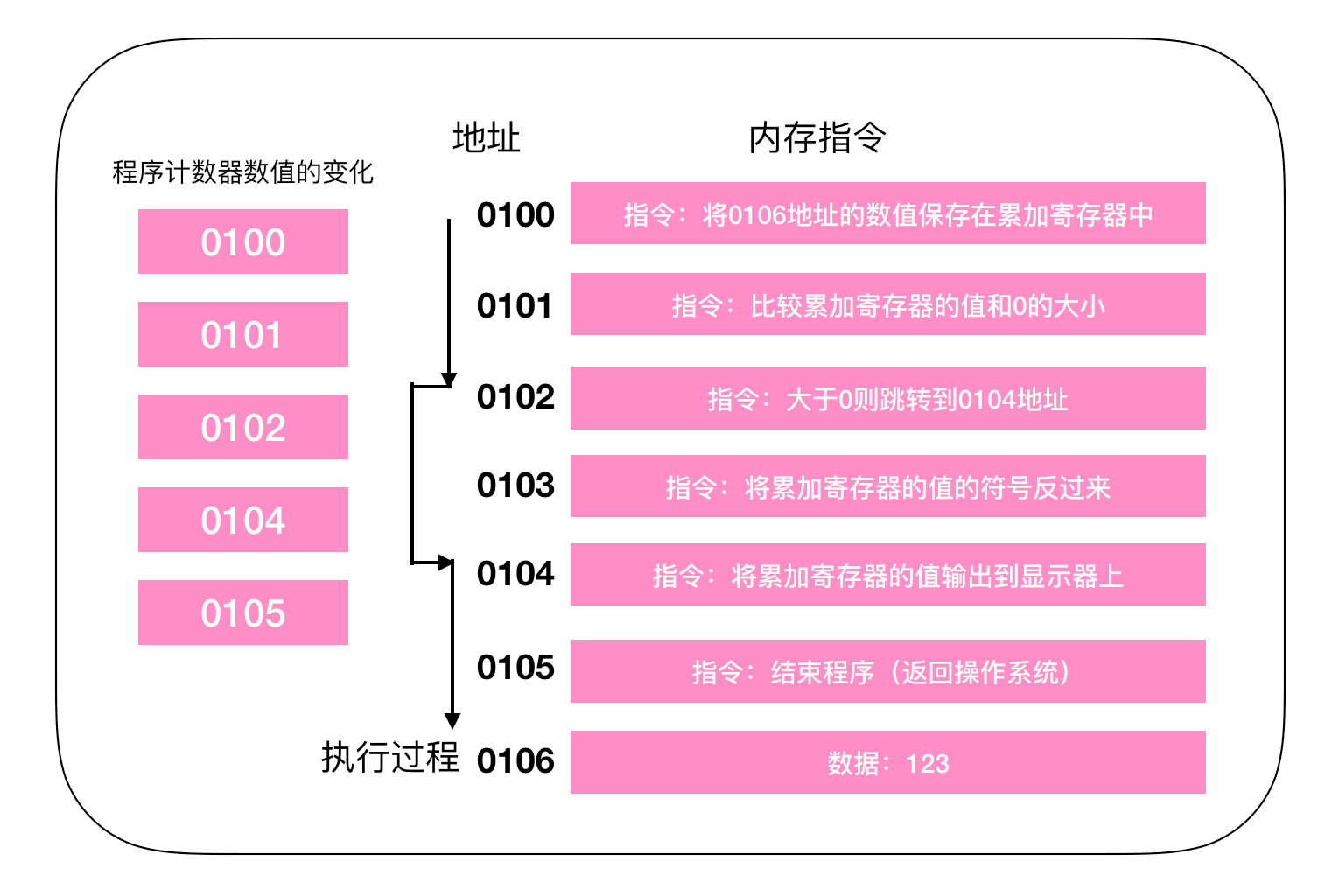
程序计数器
程序计数器是记录的下一条指令所在单元的地址的地方,如图可以看出当执行条件判断时候程序计数器的变化
标志计数器
CPU在进行运算时,标志寄存器的数值会根据当前运算的结果自动设定,运算结果的正、负和零三种 状态由标志寄存器的三个位表示。标志寄存器的第一个字节位、第二个字节位、第三个字节位各自的结 果都为1时,分别代表着正数、零和负数。

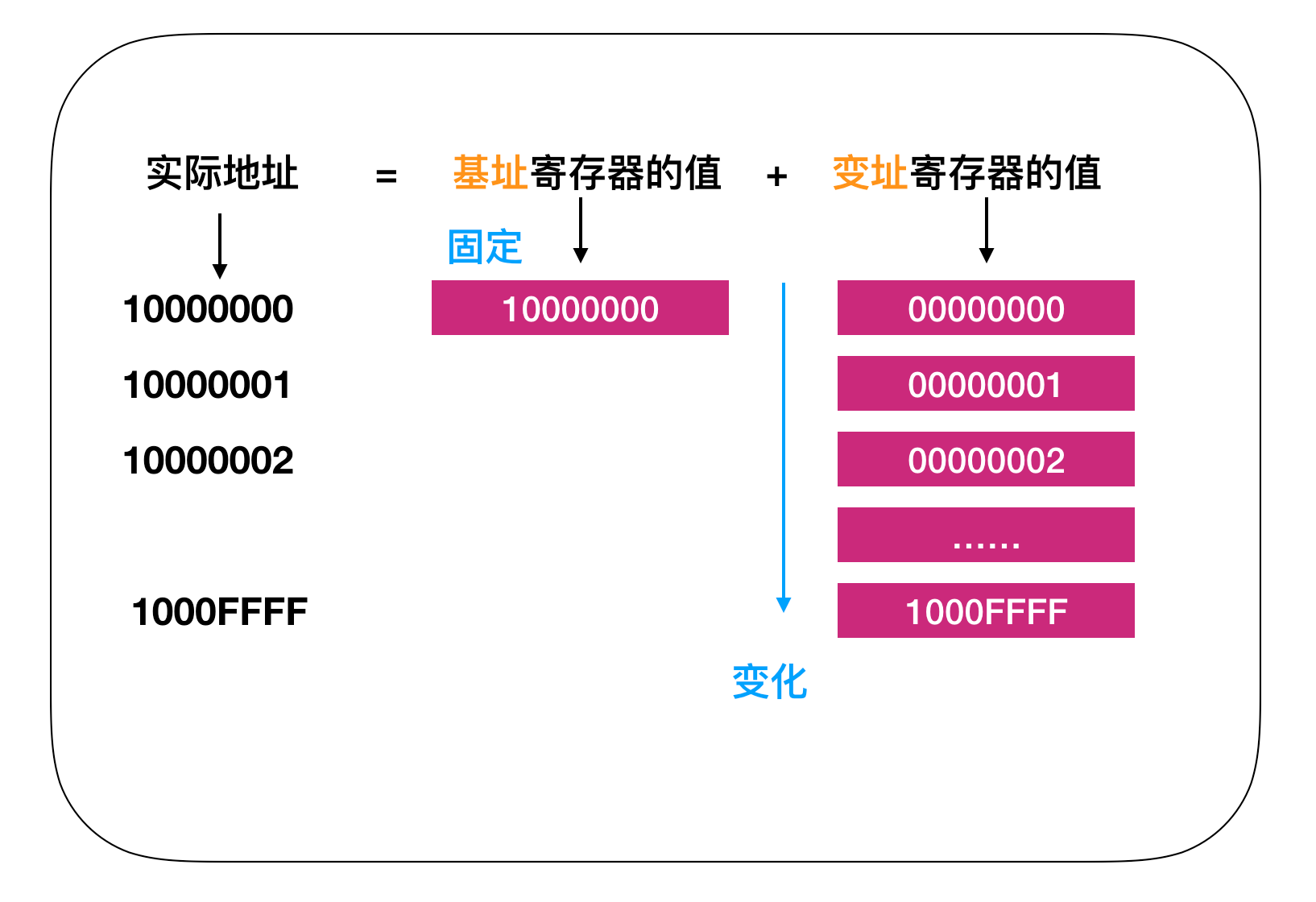
基址寄存器和变址寄存器
基址寄存器和变址寄存器有很多种用法,其中一种可以用来连续查看数组,如下图,固定基址寄存器的值,它作为数组实际地址的第一个元素地址,然后变址寄存器作为index使用。
指令的执行过程
我们知道,所有的高级语言或者低级语言,最终都会被编译成机器语言,然后一条条执行指令
几乎所有的冯•诺伊曼型计算机的CPU,其工作都可以分为5个阶段:取指令、指令译码、执行指令、访 存取数、结果写回。
取指令阶段,是将内存中的指令读取到CPU中寄存器的过程,程序寄存器用于存储下一条指令所 在的地址
指令译码阶段,在取指令完成后,立马进入指令译码阶段,在指令译码阶段,指令译码器按照预 定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的 方法。
执行指令阶段,译码完成后,就需要执行这一条指令了,此阶段的任务是完成指令所规定的各种 操作,具体实现指令的功能。
访问取数阶段,根据指令的需要,有可能需要从内存中提取数据,此阶段的任务是:根据指令地 址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算。
结果写回阶段,作为最后一个阶段,结果写回(WHte Back, WB)阶段把执行指令阶段的运行 结果数据“写回”到某种存储形式:结果数据经常被写到CPU的内部寄存器中,以便被后续的指令快 速地存取。
32位CPU和64位CPU的区别
这个32位和64位表示的是CPU一次能 处理的数据比特数,32位就是是说一次能执行32个bit,也就是4个字节。
下面看一下cpu的演变历史
8位的CPU: 一次只能处理一个8位的“数据”或者一个8位的"指令"。比如'00001101'. 又比如:“+1”这个运算,你要先指示CPU做“+”,完成后再输入“1”数据给CPU。
16位的CPU:我们就可以一次处理两个字节(16位)的数据了,比如“加1”这个命令。“加”是一个指令,占用8个位,余下的8位我们可以存放数据“1”了。
32位的CPU:就更加方便了,我们就可以一次处理一个a=a+b这样的命令了。
那么以32位cpu为例,他最多一次能执行32个bit,也就是说他能访问的内存地址是00000000 00000000 00000000 00000000 - FFFFFFFF FFFFFFFF FFFFFFFF FFFFFFFF。那么他能表示的数字最大也就是232 = 4294967296bit = 4G左右
所以说32位CPU最多只能使用4G内存
那么64位呢,呵呵,自己算下吧,理论来说只要你的内存插槽够,你可以启一万个程序。
32位的操作系统和64位的操作系统就是基于32位和64位cpu来开发的。
下一个问题来了,为什么我们64位系统可以兼容32位的程序,但是64位的程序不能在32位的系统上面跑呢?
在这之前我们先要讲一下指针,学过编程的人都不会陌生,指针指向的是内存地址,也就是说它保存的值是地址。那么在32位下和64位下,定义的两个指针一样吗,比如定义了int *p?
答案显然是NO,32位下的地址空间最大是4个字节,但是64位是8个字节,所以sizeof(p)在32位下是4个字节,在64位下面是8个字节。这也是32位和64位程序不兼容的根本原因。
要把32位和64位理清,我们分成3个方面 1. 硬件:主要是指CPU的指令集,寄存器,以及地址空间。比如x64体系结构的CPU,就是在32位的基础上添加了64位的操作指令,寄存器,同时提供了64位的虚拟地址空间 2. 操作系统:有了64位的CPU,你才能装64位的操作系统,当然,你也完全可以在x64的机子上安装32位的系统,因为其本来就是32位cpu的一个扩展,完全支持32位指令集。 3. 应用程序:有了64位的操作系统,你才能运行64位的应用程序。当然,你也完全可以在64位系统下以兼容模式运行32位程序,而且因为cpu本来就支持这些32位的指令集,所以性能基本不会有影响。
现在的64位操作系统中存在Program Files和Program Files (x86),以及System32和SysWoW64。这个是64位操作系统为了兼容32位程序专门设置的,当执行64位程序时,还是按照原来的做法,使用System32里面的系统文件来执行,Program Files存放的是64位的程序。当执行32位程序时,系统会转而使用SysWoW64里面的系统文件,然后Program Files (x86)里面存放的是32位的程序。
其实注册表里面也是类似的,在ComputerHKEY_LOCAL_MACHINESOFTWARE路径下可以看到一个WOW6432Node文件夹,里面存放的东西跟SOFTWARE类似,这个就是专门用于32位程序的注册表。假如64位程序执行注册表操作时,他获取的是ComputerHKEY_LOCAL_MACHINESOFTWARE路径下的数据,假如执行32位程序访问注册表时,它拿到的就是这个文件夹里面的数据。