池化内存分配一
Netty 默认提供了池化对象的内存分配,使用完后归还到内存池,所以一套高性能的内存管理机制是 Netty 必不可少的。在上节课中我们介绍了原生 jemalloc 的基本原理,而 Netty 高性能的内存管理也是借鉴 jemalloc 实现的,它同样需要解决两个经典的核心问题:
- 在单线程或者多线程的场景下,如何高效地进行内存分配和回收?
- 如何减少内存碎片,提高内存的有效利用率?
内存规格介绍
Netty 保留了内存规格分类的设计理念,不同大小的内存块采用的分配策略是不同的,具体内存规格的分类情况如下所示。
Tiny
大小不定,从16B开始,按16B递增,一直到496B,比如16,32,48,64,...,480,496。总共31种。
Small
大小不定,从512B开始,按两倍递增,一直到4KB,比如512,1k,2k,4k。总共4种。
Normal
也可以叫做Run,大小不定,从8k开始到16m。
Huge
大于16m的。
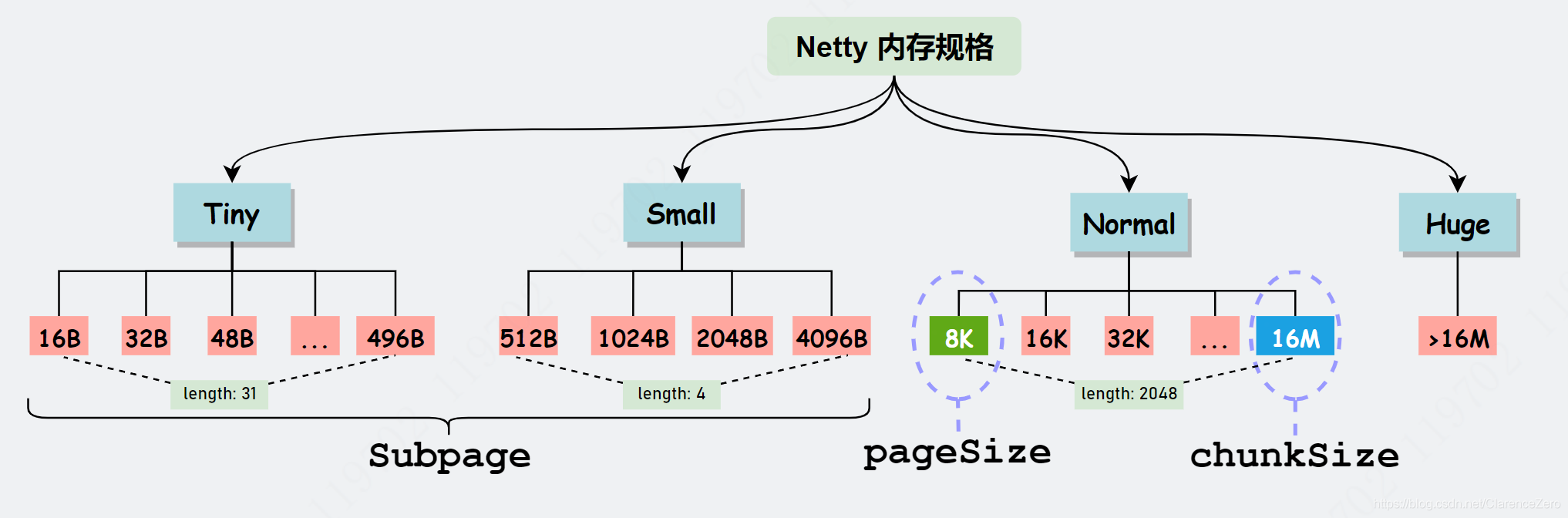
在 Netty 中定义了一个 SizeClass 类型的枚举,用于描述上图中的内存规格类型,分别为 Small 和 Normal,Tiny在最新的版本已经去掉。但是图中 Huge 并未在代码中定义,当分配大于 16M 时,可以归类为 Huge 场景,Netty 会直接使用非池化的方式进行内存分配。
Netty 在每个区域内又定义了更细粒度的内存分配单位,分别为 Chunk、Page、Subpage,我们将逐一对其进行介绍。
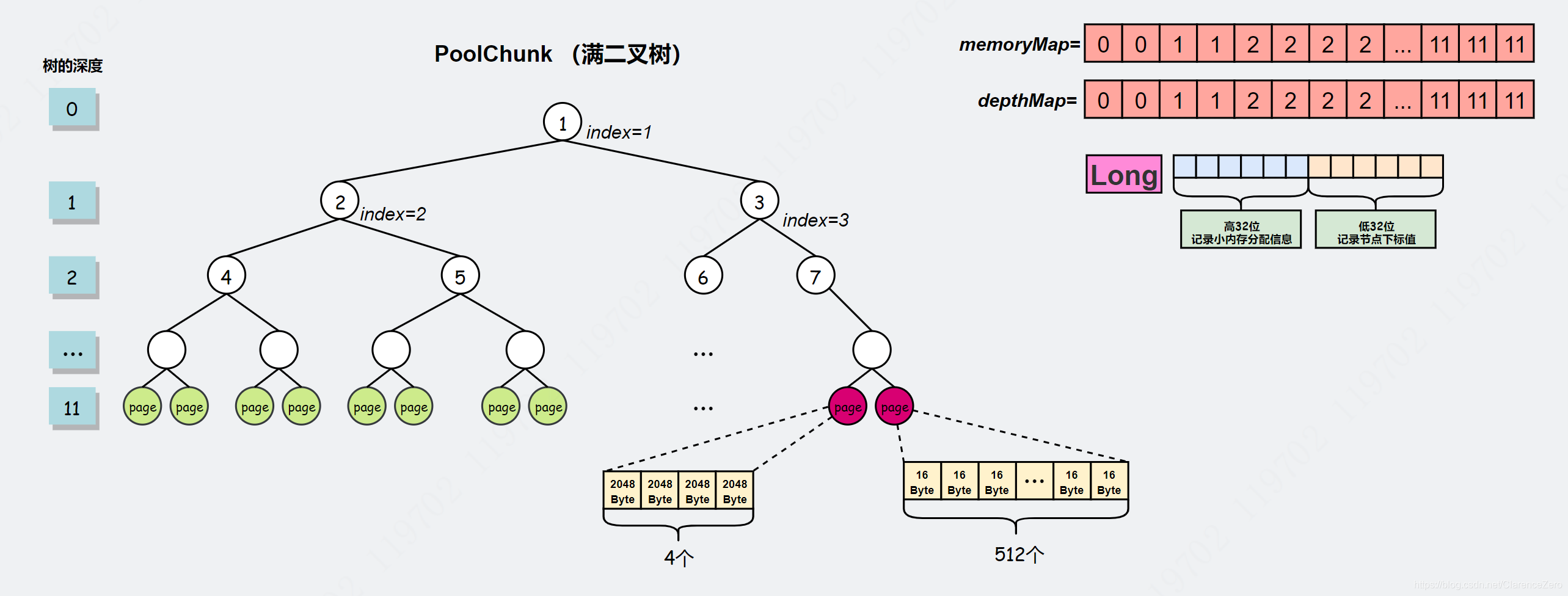
Chunk 是 Netty 向操作系统申请内存的单位,所有的内存分配操作也是基于 Chunk 完成的,Chunk 可以理解为 Page 的集合,每个 Chunk 默认大小为 16M。
Page 是 Chunk 用于管理内存的单位,Netty 中的 Page 的大小为 8K,不要与 Linux 中的内存页 Page 相混淆了。假如我们需要分配 64K 的内存,需要在 Chunk 中选取 8 个 Page 进行分配。
Subpage 负责 Page 内的内存分配,假如我们分配的内存大小远小于 Page,直接分配一个 Page 会造成严重的内存浪费,所以需要将 Page 划分为多个相同的子块进行分配,这里的子块就相当于 Subpage,把第 1 份用于此时的分配请求,其余份放入 PoolArena 的 subpage pool 池中等待下次申请同等大小的内存块时使用。按照 Tiny 和 Small 两种内存规格,SubPage 的大小也会分为两种情况。在 Tiny 场景下,最小的划分单位为 16B,按 16B 依次递增,16B、32B、48B ...... 496B;在 Small 场景下,总共可以划分为 512B、1024B、2048B、4096B 四种情况。Subpage 没有固定的大小,需要根据用户分配的缓冲区大小决定,例如分配 1K 的内存时,Netty 会把一个 Page 等分为 8 个 1K 的 Subpage。
上述方法属于jemalloc3 内存分配算法,Netty4.1.45 及以后的版本则基于jemalloc4.x算法进行重构。
虽然 jemalloc3 对内存规格进行的区域划分,目的也是为了减少内存碎片,但最坏的情况还是会出现 50% 内存浪费,内存碎片比想象中严重。比如我想分配 513Byte 的大小内存块,进行规格值计算后得到 1024,多出了 511 Byte 内存,浪费将近 50% 内存空间。因此,jemalloc4 通过构造复杂的 SizeClasses 让每个 size 的跨度变得小一点,从而达到减少内存碎片的目的。
Netty 重构了和内存分配相关的核心类,比如 PoolArena、PoolChunk、PoolSubpage 以及和缓存相关的 PoolThreadCache,并且新增了一个 SizeClasses 类。从整体上看,Netty 分配内存的逻辑是和 jemalloc3 大致相同:
- 首先尝试从本地缓存中分配,分配成功则返回。
- 分配失败则委托 PoolArena 进行内存分配,PoolArena 最终还是委托 PoolChunk 进行内存分配。
- PoolChunk 根据内存规格采取不同的分配策略。
- 内存回收时也是先通过本地线程缓存回收,如果实在回收不了或超出阈值,会交给关联的 PoolChunk 进行内存块回收。
jemalloc4 取消了 Tiny 级别,如今只有 Small、Normal 和 Huge,而 SizeClasses 就是记录 Small 和 Normal 规格值的一张表(table),这张表记录了很多有用的信息。
jemalloc4 的内存规格
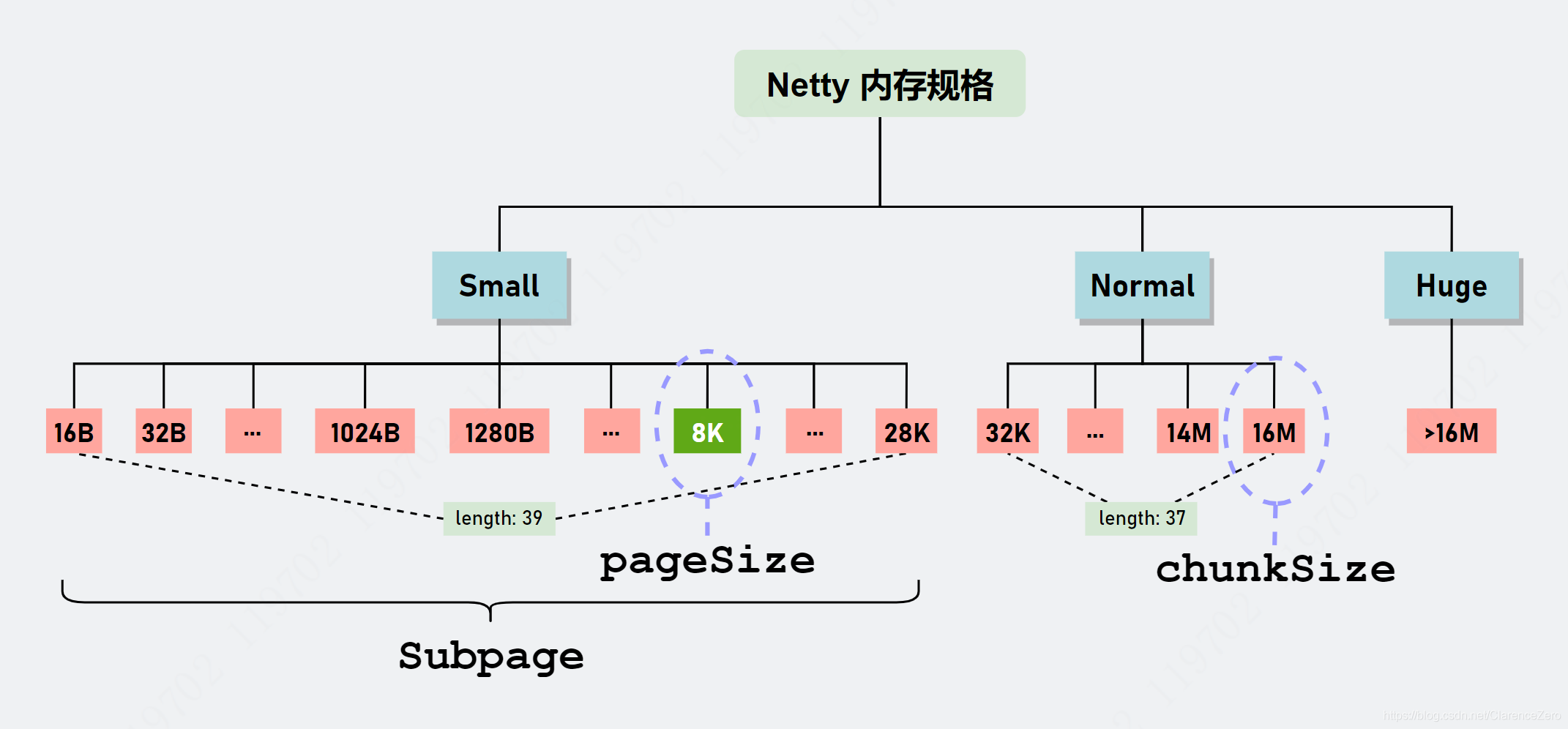
jemalloc4(Netty 实现)的算法分配逻辑:
- Netty 默认一次性向 JVM 申请 16MB 大小的内存块,也是划分为 2048 个page,每个 page 大小为 8192(8KB)(和 jemalloc3 一样)。
- 首先,根据用户申请的内存大小在 SizeClasses 查表得到确定的 index 索引值。
- 通过判断 index 大小就可以知道采用什么策略。当 index<=38(对应 size<=28KB)时,表示当前分配 Small 级别大小的内存块,采用 Small 级别分配策略。对于 38<index<nSize(75)(对应 size取值范围为 (28KB, 16MB])表示当前分配 Normal 级别大小的内存块,采用 Normal 级别分配策略。对于 index 的其他值,则对应 Huge 级别。
- 先讲 Normal 级别的内存分配,它有一个特点就是所需要的内存大小是 pageSize 的整数倍,PoolChunk 会从能满足当前分配的 run(由 long 型的句柄表示,从 LongPriorityQueue[] 数组中搜索第一个最合适的 run) 中得到若干个 page。当某一个 run 分配若干个 page 之后,可会还会有剩余空闲的 page,那么它根据剩余的空闲 pages 数量会从 LongPriorityQueue[] 数组选取一个合适的 LongPriorityQueue 存放全新的 run(handle 表示)。
- 对于 Small 级别的内存分配,经过 SizeClass 规格化后得到规格值 size,然后求得 size 和 pageSize 最小公倍数 j,j 一定是 pageSize 的整数倍。然后再按照 Normal 级别的内存分配方式从第一个适合的 run 中分配 (j/pageSize) 数量的 page。剩下的就和 jemalloc3 一样,将 page 所组成的内存块拆分成等分的 subpage,并使用 long[] 记录每份 subpage 的使用状态。
关于内存块回收逻辑,subpage 和 jemalloc3 并没有太大的区别。但是对于 run 的回收可太不一样了。
- 在回收某一个 run 之前,先尝试向前搜索并合并相邻的空闲的 run,得到一个全新的 handle。
- 然后再向后搜索并合并相邻的空闲的 run,得到一个全新的 handle。
- 再把 handle 写回前面两个重要的数据结构中,以待下次分配时使用。
使用案例
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10*1024*1024);
首先调用ByteBufAllocator.DEFAULT
ByteBufAllocator DEFAULT = ByteBufUtil.DEFAULT_ALLOCATOR;
调用了ByteBufUtil的默认分配器。此分配器在静态代码中定义,默认是池化的。然后调用的是PooledByteBufAllocator.DEFAULT
String allocType = SystemPropertyUtil.get( "io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled"); allocType = allocType.toLowerCase(Locale.US).trim(); ByteBufAllocator alloc; if ("unpooled".equals(allocType)) { alloc = UnpooledByteBufAllocator.DEFAULT; logger.debug("-Dio.netty.allocator.type: {}", allocType); } else if ("pooled".equals(allocType)) { alloc = PooledByteBufAllocator.DEFAULT; logger.debug("-Dio.netty.allocator.type: {}", allocType); } else { alloc = PooledByteBufAllocator.DEFAULT; logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType); } DEFAULT_ALLOCATOR = alloc;
PooledByteBufAllocator.DEFAULT
public static final PooledByteBufAllocator DEFAULT = new PooledByteBufAllocator(PlatformDependent.directBufferPreferred());
PooledByteBufAllocator
主要变量
private static final int DEFAULT_NUM_HEAP_ARENA;//堆缓冲区区域的数量 默认16 private static final int DEFAULT_NUM_DIRECT_ARENA;//直接缓冲区区域的数量 默认16 private static final int DEFAULT_PAGE_SIZE;//页大小 默认8192 private static final int DEFAULT_MAX_ORDER;//满二叉树的最大深度 默认11 private static final int DEFAULT_DIRECT_MEMORY_CACHE_ALIGNMENT;//直接内存对齐 默认0 static final int DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK;//每个块中最大字节缓冲区的数量 和ArrayDeque有关 默认1023 private static final int DEFAULT_SMALL_CACHE_SIZE;//SMALL缓存数量 默认256 private static final int DEFAULT_NORMAL_CACHE_SIZE;//NORMAL缓存数量 默认64
DEFAULT_MAX_ORDER(io.netty.allocator.maxOrder)
将chunk进行页大小的分割而使用的一棵满二叉树的最大深度,默认是11,也就是4095个结点,最深的一层是2048个节点,每个节点对应一个页大小,也即最深一层的容量就是一个chunk大小,8k x 2048=16m。
int defaultMaxOrder = SystemPropertyUtil.getInt("io.netty.allocator.maxOrder", 11); Throwable maxOrderFallbackCause = null; try { validateAndCalculateChunkSize(DEFAULT_PAGE_SIZE, defaultMaxOrder); } catch (Throwable t) { maxOrderFallbackCause = t; defaultMaxOrder = 11; } DEFAULT_MAX_ORDER = defaultMaxOrder;
DEFAULT_NUM_HEAP_ARENA和DEFAULT_NUM_DIRECT_ARENA
chunk的大小:final int defaultChunkSize = DEFAULT_PAGE_SIZE << DEFAULT_MAX_ORDER; 8k<<11=16M
然后计算堆缓冲区和直接缓冲区分配的区域ARENA的数量,一般是CPU个数的2倍。
这里有段runtime.maxMemory() / defaultChunkSize / 2 / 3的意思就是说,获取可用的最大内存,然后除以chunk的个数,除以2(因为每个区域个数不能超过50%呀),而且得有3个chunk,所以又除以3。当然这个值算出来貌似可以大于16m,但是太大了内部碎片多,分配灵活性也不好。当然这里还有两个参数可以调io.netty.allocator.numHeapArenas,io.netty.allocator.numDirectArenas。
Netty 借鉴了 jemalloc 中 Arena 的设计思想,采用固定数量的多个 Arena 进行内存分配,Arena 的默认数量与 CPU 核数有关,通过创建多个 Arena 来缓解资源竞争问题,从而提高内存分配效率。线程在首次申请分配内存时,会通过 round-robin 的方式轮询 Arena 数组,选择一个固定的 Arena,在线程的生命周期内只与该 Arena 打交道,所以每个线程都保存了 Arena 信息,从而提高访问效率。
final int defaultMinNumArena = NettyRuntime.availableProcessors() * 2; final int defaultChunkSize = DEFAULT_PAGE_SIZE << DEFAULT_MAX_ORDER; DEFAULT_NUM_HEAP_ARENA = Math.max(0, SystemPropertyUtil.getInt( "io.netty.allocator.numHeapArenas", (int) Math.min( defaultMinNumArena, runtime.maxMemory() / defaultChunkSize / 2 / 3))); DEFAULT_NUM_DIRECT_ARENA = Math.max(0, SystemPropertyUtil.getInt( "io.netty.allocator.numDirectArenas", (int) Math.min( defaultMinNumArena, PlatformDependent.maxDirectMemory() / defaultChunkSize / 2 / 3)));
构造函数
public PooledByteBufAllocator(boolean preferDirect) { this(preferDirect, DEFAULT_NUM_HEAP_ARENA, DEFAULT_NUM_DIRECT_ARENA, DEFAULT_PAGE_SIZE, DEFAULT_MAX_ORDER); }
默认堆外内存

最终构造函数
public PooledByteBufAllocator(boolean preferDirect, int nHeapArena, int nDirectArena, int pageSize, int maxOrder, int smallCacheSize, int normalCacheSize, boolean useCacheForAllThreads, int directMemoryCacheAlignment) { super(preferDirect); threadCache = new PoolThreadLocalCache(useCacheForAllThreads); this.smallCacheSize = smallCacheSize; this.normalCacheSize = normalCacheSize; chunkSize = validateAndCalculateChunkSize(pageSize, maxOrder); checkPositiveOrZero(nHeapArena, "nHeapArena"); checkPositiveOrZero(nDirectArena, "nDirectArena"); checkPositiveOrZero(directMemoryCacheAlignment, "directMemoryCacheAlignment"); if (directMemoryCacheAlignment > 0 && !isDirectMemoryCacheAlignmentSupported()) { throw new IllegalArgumentException("directMemoryCacheAlignment is not supported"); } if ((directMemoryCacheAlignment & -directMemoryCacheAlignment) != directMemoryCacheAlignment) { throw new IllegalArgumentException("directMemoryCacheAlignment: " + directMemoryCacheAlignment + " (expected: power of two)"); } int pageShifts = validateAndCalculatePageShifts(pageSize); if (nHeapArena > 0) { heapArenas = newArenaArray(nHeapArena); List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(heapArenas.length); for (int i = 0; i < heapArenas.length; i ++) { PoolArena.HeapArena arena = new PoolArena.HeapArena(this, pageSize, pageShifts, chunkSize, directMemoryCacheAlignment); heapArenas[i] = arena; metrics.add(arena); } heapArenaMetrics = Collections.unmodifiableList(metrics); } else { heapArenas = null; heapArenaMetrics = Collections.emptyList(); } if (nDirectArena > 0) { directArenas = newArenaArray(nDirectArena); List<PoolArenaMetric> metrics = new ArrayList<PoolArenaMetric>(directArenas.length); for (int i = 0; i < directArenas.length; i ++) { PoolArena.DirectArena arena = new PoolArena.DirectArena( this, pageSize, pageShifts, chunkSize, directMemoryCacheAlignment); directArenas[i] = arena; metrics.add(arena); } directArenaMetrics = Collections.unmodifiableList(metrics); } else { directArenas = null; directArenaMetrics = Collections.emptyList(); } metric = new PooledByteBufAllocatorMetric(this); }
HeapArena构造函数

看下父类PoolArena属性
enum SizeClass { Small, Normal } final PooledByteBufAllocator parent; final int numSmallSubpagePools;//small类型的子页数组的个数 final int directMemoryCacheAlignment;//对齐的缓存尺寸比如32 64 final int directMemoryCacheAlignmentMask;/对齐遮罩,求余数用,2的幂次可以用 private final PoolSubpage<T>[] smallSubpagePools;//small类型子页数组 默认4个 //根据块内存使用率状态分的数组,因为百分比是正数,所以就直接取整了 private final PoolChunkList<T> q050;//50-100 private final PoolChunkList<T> q025;//25-75 private final PoolChunkList<T> q000;//1-50 private final PoolChunkList<T> qInit;//0-25 private final PoolChunkList<T> q075;//75-100 private final PoolChunkList<T> q100;//100-100 //块列表的一些指标度量 private final List<PoolChunkListMetric> chunkListMetrics; // Metrics for allocations and deallocations private long allocationsNormal; // We need to use the LongCounter here as this is not guarded via synchronized block. private final LongCounter allocationsSmall = PlatformDependent.newLongCounter();//Small的分配个数 private final LongCounter allocationsHuge = PlatformDependent.newLongCounter();//huge的分配个数 private final LongCounter activeBytesHuge = PlatformDependent.newLongCounter();//huge的字节大小 private long deallocationsSmall; private long deallocationsNormal; // We need to use the LongCounter here as this is not guarded via synchronized block. private final LongCounter deallocationsHuge = PlatformDependent.newLongCounter(); // Number of thread caches backed by this arena. final AtomicInteger numThreadCaches = new AtomicInteger();
其有部分属性在SizeClasses类型中
protected final int pageSize;//页大小 默认8K protected final int pageShifts;//1左移多少位得到pageSize,页大小是8k = 1 << 13 所以默认13位 protected final int chunkSize;//块大小 默认16m
PoolArena构造函数
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int pageShifts, int chunkSize, int cacheAlignment) { super(pageSize, pageShifts, chunkSize, cacheAlignment); this.parent = parent; directMemoryCacheAlignment = cacheAlignment; directMemoryCacheAlignmentMask = cacheAlignment - 1; numSmallSubpagePools = nSubpages; smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools); for (int i = 0; i < smallSubpagePools.length; i ++) { smallSubpagePools[i] = newSubpagePoolHead(); } q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize); q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize); q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize); q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize); q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize); qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize); q100.prevList(q075); q075.prevList(q050); q050.prevList(q025); q025.prevList(q000); q000.prevList(null); qInit.prevList(qInit); List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6); metrics.add(qInit); metrics.add(q000); metrics.add(q025); metrics.add(q050); metrics.add(q075); metrics.add(q100); chunkListMetrics = Collections.unmodifiableList(metrics); }
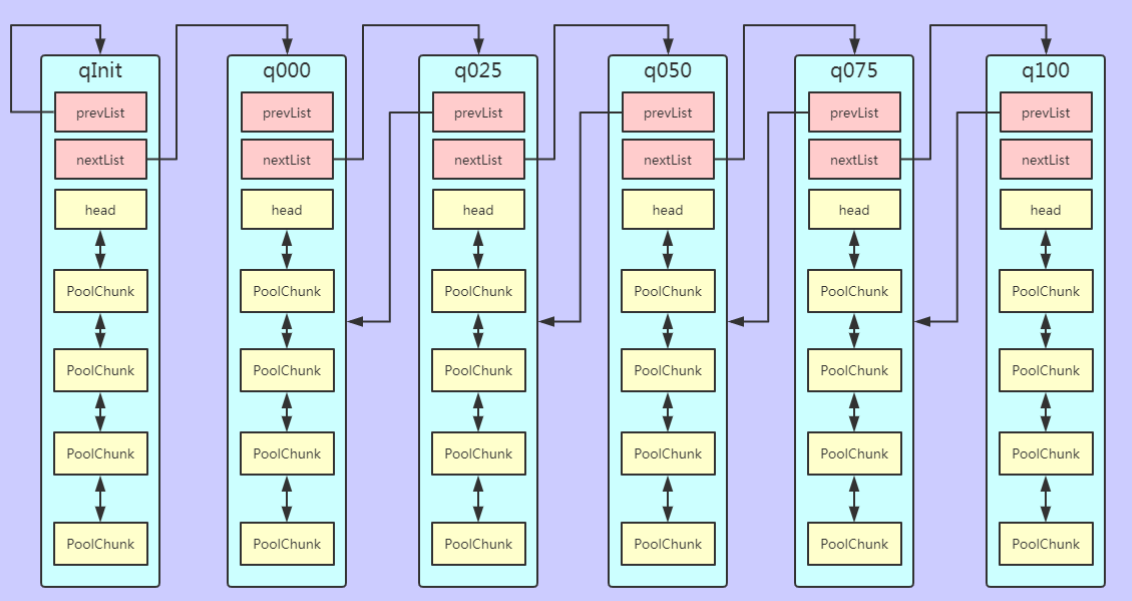
PoolChunkList 用于 Chunk 场景下的内存分配,PoolArena 中初始化了六个 PoolChunkList,分别为 qInit、q000、q025、q050、q075、q100,这与 jemalloc 中 run 队列思路是一致的,它们分别代表不同的内存使用率,如下所示:
- qInit,内存使用率为 0 ~ 25% 的 Chunk。
- q000,内存使用率为 1 ~ 50% 的 Chunk。
- q025,内存使用率为 25% ~ 75% 的 Chunk。
- q050,内存使用率为 50% ~ 100% 的 Chunk。
- q075,内存使用率为 75% ~ 100% 的 Chunk。
- q100,内存使用率为 100% 的 Chunk。
六种类型的 PoolChunkList 除了 qInit,它们之间都形成了双向链表

随着 Chunk 内存使用率的变化,Netty 会重新检查内存的使用率并放入对应的 PoolChunkList,所以 PoolChunk 会在不同的 PoolChunkList 移动。
qInit 和 q000 为什么需要设计成两个:
qInit 用于存储初始分配的 PoolChunk,因为在第一次内存分配时,PoolChunkList 中并没有可用的 PoolChunk,所以需要新创建一个 PoolChunk 并添加到 qInit 列表中。qInit 中的 PoolChunk 即使内存被完全释放也不会被回收,避免 PoolChunk 的重复初始化工作。
q000 则用于存放内存使用率为 1 ~ 50% 的 PoolChunk,q000 中的 PoolChunk 内存被完全释放后,PoolChunk 从链表中移除,对应分配的内存也会被回收。
还有一点需要注意的是,在分配大于 8K 的内存时,其链表的访问顺序是 q050->q025->q000->qInit->q075,遍历检查 PoolChunkList 中是否有 PoolChunk 可以用于内存分配。
为什么会优先选择 q050,而不是从 q000 开始呢?
可以说这是一个折中的选择,在频繁分配内存的场景下,如果从 q000 开始,会有大部分的 PoolChunk 面临频繁的创建和销毁,造成内存分配的性能降低。如果从 q050 开始,会使 PoolChunk 的使用率范围保持在中间水平,降低了 PoolChunk 被回收的概率,从而兼顾了性能。
SizeClasses
- index:表示的是每个size类型的索引
- log2Group:表示的对应size的对应的组,用于计算对应的size。以每 4 行为一组,一共有 19 组。第 0 组比较特殊,它是单独初始化的。因此,我们应该从第 1 组开始,起始值为 6,每组的 log2Group 是在上一组的值 +1。
- log2Delata:表示的是当前序号所对应的 size 和前一个序号所对应的 size 的差值的log2值,比如 index=6 对应的 size = 112,index=7 对应的 size= 128,因此 index=7 的 log2Delta(7) = log2(128-112)=4。不知道你们有没有发现,其实log2Delta=log2Group-2
- nDelta:表示组内增量的倍数。第 0 组也是比较特殊,nDelta 是从 0 开始 + 1。而其余组是从 1 开始 +1。
- isMultipageSize:表示的是这个size是否是pagesize(默认值:8192)的倍数。后续会把 isMultiPageSize=1 的行单独整理成一张表,你会发现有 40 个 isMultiPageSize=1 的行。
- isSubPage:表示其是否为一个subPage类型(即这种类型的size需要利用subPage进行分配)
- log2DeltaLookup:当 index<=27 时,其值和 log2Delta 相等,当index>27,其值为 0。但是在代码中没有看到具体用来做什么。
通过size = (1 << log2Group) + nDelta * (1 << log2Delta) 计算size。
|
index |
log2Group |
log2Delta |
nDelta |
isMultiPageSize |
isSubPage |
log2DeltaLookup |
size |
multiple(pagesize的倍数) |
|
0 |
4 |
4 |
0 |
0 |
1 |
4 |
16 |
|
|
1 |
4 |
4 |
1 |
0 |
1 |
4 |
32 |
|
|
2 |
4 |
4 |
2 |
0 |
1 |
4 |
48 |
|
|
3 |
4 |
4 |
3 |
0 |
1 |
4 |
64 |
|
|
4 |
6 |
4 |
1 |
0 |
1 |
4 |
80 |
|
|
5 |
6 |
4 |
2 |
0 |
1 |
4 |
96 |
|
|
6 |
6 |
4 |
3 |
0 |
1 |
4 |
112 |
|
|
7 |
6 |
4 |
4 |
0 |
1 |
4 |
128 |
|
|
8 |
7 |
5 |
1 |
0 |
1 |
5 |
160 |
|
|
9 |
7 |
5 |
2 |
0 |
1 |
5 |
192 |
|
|
10 |
7 |
5 |
3 |
0 |
1 |
5 |
224 |
|
|
11 |
7 |
5 |
4 |
0 |
1 |
5 |
256 |
|
|
12 |
8 |
6 |
1 |
0 |
1 |
6 |
320 |
|
|
13 |
8 |
6 |
2 |
0 |
1 |
6 |
384 |
|
|
14 |
8 |
6 |
3 |
0 |
1 |
6 |
448 |
|
|
15 |
8 |
6 |
4 |
0 |
1 |
6 |
512 |
|
|
16 |
9 |
7 |
1 |
0 |
1 |
7 |
640 |
|
|
17 |
9 |
7 |
2 |
0 |
1 |
7 |
768 |
|
|
18 |
9 |
7 |
3 |
0 |
1 |
7 |
896 |
|
|
19 |
9 |
7 |
4 |
0 |
1 |
7 |
1024 |
|
|
20 |
10 |
8 |
1 |
0 |
1 |
8 |
1280 |
|
|
21 |
10 |
8 |
2 |
0 |
1 |
8 |
1536 |
|
|
22 |
10 |
8 |
3 |
0 |
1 |
8 |
1792 |
|
|
23 |
10 |
8 |
4 |
0 |
1 |
8 |
2048 |
|
|
24 |
11 |
9 |
1 |
0 |
1 |
9 |
2560 |
|
|
25 |
11 |
9 |
2 |
0 |
1 |
9 |
3072 |
|
|
26 |
11 |
9 |
3 |
0 |
1 |
9 |
3584 |
|
|
27 |
11 |
9 |
4 |
0 |
1 |
9 |
4096 |
|
|
28 |
12 |
10 |
1 |
0 |
1 |
0 |
5120 |
|
|
29 |
12 |
10 |
2 |
0 |
1 |
0 |
6144 |
|
|
30 |
12 |
10 |
3 |
0 |
1 |
0 |
7168 |
|
|
31 |
12 |
10 |
4 |
1 |
1 |
0 |
8192 |
1 |
|
32 |
13 |
11 |
1 |
0 |
1 |
0 |
10240 |
1.25 |
|
33 |
13 |
11 |
2 |
0 |
1 |
0 |
12288 |
1.5 |
|
34 |
13 |
11 |
3 |
0 |
1 |
0 |
14336 |
1.75 |
|
35 |
13 |
11 |
4 |
1 |
1 |
0 |
16384 |
2 |
|
36 |
14 |
12 |
1 |
0 |
1 |
0 |
20480 |
2.5 |
|
37 |
14 |
12 |
2 |
1 |
1 |
0 |
24576 |
3 |
|
38 |
14 |
12 |
3 |
0 |
1 |
0 |
28672 |
3.5 |
|
39 |
14 |
12 |
4 |
1 |
0 |
0 |
32768 |
4 |
|
40 |
15 |
13 |
1 |
1 |
0 |
0 |
40960 |
5 |
|
41 |
15 |
13 |
2 |
1 |
0 |
0 |
49152 |
6 |
|
42 |
15 |
13 |
3 |
1 |
0 |
0 |
57344 |
7 |
|
43 |
15 |
13 |
4 |
1 |
0 |
0 |
65536 |
8 |
|
44 |
16 |
14 |
1 |
1 |
0 |
0 |
81920 |
10 |
|
45 |
16 |
14 |
2 |
1 |
0 |
0 |
98304 |
12 |
|
46 |
16 |
14 |
3 |
1 |
0 |
0 |
114688 |
14 |
|
47 |
16 |
14 |
4 |
1 |
0 |
0 |
131072 |
16 |
|
48 |
17 |
15 |
1 |
1 |
0 |
0 |
163840 |
20 |
|
49 |
17 |
15 |
2 |
1 |
0 |
0 |
196608 |
24 |
|
50 |
17 |
15 |
3 |
1 |
0 |
0 |
229376 |
28 |
|
51 |
17 |
15 |
4 |
1 |
0 |
0 |
262144 |
32 |
|
52 |
18 |
16 |
1 |
1 |
0 |
0 |
327680 |
40 |
|
53 |
18 |
16 |
2 |
1 |
0 |
0 |
393216 |
48 |
|
54 |
18 |
16 |
3 |
1 |
0 |
0 |
458752 |
56 |
|
55 |
18 |
16 |
4 |
1 |
0 |
0 |
524288 |
64 |
|
56 |
19 |
17 |
1 |
1 |
0 |
0 |
655360 |
80 |
|
57 |
19 |
17 |
2 |
1 |
0 |
0 |
786432 |
96 |
|
58 |
19 |
17 |
3 |
1 |
0 |
0 |
917504 |
112 |
|
59 |
19 |
17 |
4 |
1 |
0 |
0 |
1048576 |
128 |
|
60 |
20 |
18 |
1 |
1 |
0 |
0 |
1310720 |
160 |
|
61 |
20 |
18 |
2 |
1 |
0 |
0 |
1572864 |
192 |
|
62 |
20 |
18 |
3 |
1 |
0 |
0 |
1835008 |
224 |
|
63 |
20 |
18 |
4 |
1 |
0 |
0 |
2097152 |
256 |
|
64 |
21 |
19 |
1 |
1 |
0 |
0 |
2621440 |
320 |
|
65 |
21 |
19 |
2 |
1 |
0 |
0 |
3145728 |
384 |
|
66 |
21 |
19 |
3 |
1 |
0 |
0 |
3670016 |
448 |
|
67 |
21 |
19 |
4 |
1 |
0 |
0 |
4194304 |
512 |
|
68 |
22 |
20 |
1 |
1 |
0 |
0 |
5242880 |
640 |
|
69 |
22 |
20 |
2 |
1 |
0 |
0 |
6291456 |
768 |
|
70 |
22 |
20 |
3 |
1 |
0 |
0 |
7340032 |
895 |
|
71 |
22 |
20 |
4 |
1 |
0 |
0 |
8388608 |
1024 |
|
72 |
23 |
21 |
1 |
1 |
0 |
0 |
10485760 |
1280 |
|
73 |
23 |
21 |
2 |
1 |
0 |
0 |
12582912 |
1536 |
|
74 |
23 |
21 |
3 |
1 |
0 |
0 |
14680064 |
1792 |
|
75 |
23 |
21 |
4 |
1 |
0 |
0 |
16777216 |
2048 |
初始化
- sizeClasses:这个表即为上面的存储了log2Group等7个数据的表格,
- sizeIdx2sizeTab:这个表格存的则是索引和对应的size的对应表格(其实就是上面表格中size那一列的数据)
- pageIdx2SizeTab:这个表格存储的是上面的表格中isMultiPages是1的对应的size的数据
- sizeIdxTab:这个表格主要存储的是lookup下的size以每2B为单位存储一个size到其对应的size的缓存值(主要是对小数据类型的对应的idx的查找进行缓存)
1 protected SizeClasses(int pageSize, int pageShifts, int chunkSize, int directMemoryCacheAlignment) { 2 //每一页的大小(默认为8192,即8kB) 3 this.pageSize = pageSize; 4 //pageSize的最高位需要左移的次数(默认为13) 5 this.pageShifts = pageShifts; 6 //这个chunk的大小(默认为16777216,即16MB) 7 this.chunkSize = chunkSize; 8 //主要是对于Huge这种直接分配的类型的数据将其对其为directMemoryCacheAlignment的倍数 9 this.directMemoryCacheAlignment = directMemoryCacheAlignment; 10 //计算出group的数量 11 //这里我个人理解计算方式是通过计算log2Delta来计算group的数量的, 12 //log2(chunkSize)表示的是最大能达到的大小(默认值21) 13 //加1减LOG2_QUANTUM表示的是log2Delta有两个4并且是以4开始的 14 //不过log2Delta最多能达到21 15 //所以会奇怪的是默认情况下这里计算的值为21,而从表格上看到group的个数其实只有19个 16 int group = log2(chunkSize) + 1 - LOG2_QUANTUM; 17 //生成sizeClasses,对于这个数组的7个位置的每一位表示的含义为 18 //[index, log2Group, log2Delta, nDelta, isMultiPageSize, isSubPage, log2DeltaLookup] 19 sizeClasses = new short[group << LOG2_SIZE_CLASS_GROUP][7]; 20 nSizes = sizeClasses(); 21 //生成idx对size的表格,这里的sizeIdx2sizeTab存储的就是 22 //利用(1 << log2Group) + (nDelta << log2Delta)计算的size 23 sizeIdx2sizeTab = new int[nSizes]; 24 //pageIdx2sizeTab则存储的是isMultiPageSize是1的对应的size 25 pageIdx2sizeTab = new int[nPSizes]; 26 idx2SizeTab(sizeIdx2sizeTab, pageIdx2sizeTab); 27 //生成size对idx的表格,这里存储的是lookupMaxSize以下的,并且其size的单位是1<<LOG2_QUANTUM 28 //即为16B 29 size2idxTab = new int[lookupMaxSize >> LOG2_QUANTUM]; 30 size2idxTab(size2idxTab); 31 }sizeClasses
sizeClasses的主要作用即为生成sizeClasses这个数组,即为上面的数组。可以看到下面的代码其实就是以1<<(LOG2_QUANTUM)为一组,这一组的log2Group和log2Delta是相同,并增长这个nDelta来使得每组数据的两个size的差值相同。
1 private int sizeClasses() { 2 int normalMaxSize = -1; 3 int index = 0; 4 int size = 0; 5 int log2Group = LOG2_QUANTUM; 6 int log2Delta = LOG2_QUANTUM; 7 //这里表示的是每一组的数量 8 int ndeltaLimit = 1 << LOG2_SIZE_CLASS_GROUP; 9 //第一组从1<<LOG2_QUANTUM开始,从1<<(LOG2_QUANTUM+1)结束 10 int nDelta = 0; 11 while (nDelta < ndeltaLimit) { 12 size = sizeClass(index++, log2Group, log2Delta, nDelta++); 13 } 14 //后续组中log2Group比log2Delta大LOG2_SIZE_CLASS_GROUP,并且nDelta会从1走到1 << LOG2_SIZE_CLASS_GROUP 15 //这则可以保证size = (1 << log2Group) + (1 << log2Delta) * nDelta在nDelta=1 << LOG2_SIZE_CLASS_GROUP 16 //是size=1<<(1+log2Group) 17 log2Group += LOG2_SIZE_CLASS_GROUP; 18 //All remaining groups, nDelta start at 1. 19 while (size < chunkSize) { 20 nDelta = 1; 21 //生成一组数据nDeleta从1到1 << LOG2_SIZE_CLASS_GROUP 22 //表示这一组的数据中相邻两个size的差值为1<<nDelta 23 while (nDelta <= ndeltaLimit && size < chunkSize) { 24 size = sizeClass(index++, log2Group, log2Delta, nDelta++); 25 normalMaxSize = size; 26 } 27 log2Group++; 28 log2Delta++; 29 } 30 //这里进行了断言,表示chunkSize必须是sizeClass的最后一个 31 assert chunkSize == normalMaxSize; 32 return index; 33 }sizeClass
sizeClass方法主要是利用log2Group,log2Delta,nDelta计算出isMultiPage,isSubPage,log2DeltaLookup等其他字段的数据
1 private int sizeClass(int index, int log2Group, int log2Delta, int nDelta) { 2 short isMultiPageSize; 3 //log2Delta大于pageShifts则表示size的计算的最小单位都大于pageSize 4 if (log2Delta >= pageShifts) { 5 isMultiPageSize = yes; 6 } else { 7 int pageSize = 1 << pageShifts; 8 int size = (1 << log2Group) + (1 << log2Delta) * nDelta; 9 isMultiPageSize = size == size / pageSize * pageSize? yes : no; 10 } 11 int log2Ndelta = nDelta == 0? 0 : log2(nDelta); 12 byte remove = 1 << log2Ndelta < nDelta? yes : no; 13 //2^(log2Delta+log2Ndelta)即为(1 << log2Delta) * nDelta,故log2Delta + log2Ndelta == log2Group是size=2^(log2Group + 1) 14 int log2Size = log2Delta + log2Ndelta == log2Group? log2Group + 1 : log2Group; 15 if (log2Size == log2Group) { 16 remove = yes; 17 } 18 //要size必定是pageSize的倍数,则log2Delta需要大于等于pageShifts,而后续的log2Group=log2Delta+LOG2_SIZE_CLASS_GROUP 19 //又有size = (1 << log2Group) + (1 << log2Delta) * nDelta; 20 //当log2Delta>=pageShifts,很容易证明log2Size >= pageShifts + LOG2_SIZE_CLASS_GROUP + log2(1+2^(log2Ndelta-LOG2_SIZE_CLASS_GROUP)) 21 //即可有log2Size > pageShifts + LOG2_SIZE_CLASS_GROUP,其相反的则为log2Size <= pageShifts + LOG2_SIZE_CLASS_GROUP 22 //但是此处没有等于号,是因为当log2Size =pageShifts + LOG2_SIZE_CLASS_GROUP-1是,其对应的log2Ndelta=LOG2_SIZE_CLASS_GROUP 23 //(1 << log2Delta) * nDelta则为2^pageShifts的倍数,故此下面没有等号 24 short isSubpage = log2Size < pageShifts + LOG2_SIZE_CLASS_GROUP? yes : no; 25 //log2DeltaLookup在LOG2_MAX_LOOKUP_SIZE之前是log2Delta,之后是no 26 int log2DeltaLookup = log2Size < LOG2_MAX_LOOKUP_SIZE || 27 log2Size == LOG2_MAX_LOOKUP_SIZE && remove == no 28 ? log2Delta : no; 29 short[] sz = { 30 (short) index, (short) log2Group, (short) log2Delta, 31 (short) nDelta, isMultiPageSize, isSubpage, (short) log2DeltaLookup 32 }; 33 sizeClasses[index] = sz; 34 int size = (1 << log2Group) + (nDelta << log2Delta); 35 //计算是pageSize的数量 36 if (sz[PAGESIZE_IDX] == yes) { 37 nPSizes++; 38 } 39 //计算是subPage的数量 40 if (sz[SUBPAGE_IDX] == yes) { 41 nSubpages++; 42 //这个值是用来判断分配是从subpage分配还是直接从poolchunk中进行分配 43 smallMaxSizeIdx = index; 44 } 45 //计算lookupMaxSize 46 if (sz[LOG2_DELTA_LOOKUP_IDX] != no) { 47 lookupMaxSize = size; 48 } 49 return size; 50 }size2idxTab
这个方法比较简单,其主要是1在lookupMaxSize一下的小的size,以每隔2B为单位生成个(size-1)/2B-->idx的对应关系,从而在size小于lookupMaxSize时可以直接从size2idxTab数组中获取对应的idx。
1 private void size2idxTab(int[] size2idxTab) { 2 int idx = 0; 3 int size = 0; 4 for (int i = 0; size <= lookupMaxSize; i++) { 5 int log2Delta = sizeClasses[i][LOG2DELTA_IDX]; 6 int times = 1 << log2Delta - LOG2_QUANTUM; 7 //以2B为单位,每隔2B生成一个size->idx的对应关系 8 while (size <= lookupMaxSize && times-- > 0) { 9 size2idxTab[idx++] = i; 10 size = idx + 1 << LOG2_QUANTUM; 11 } 12 } 13 }pages2pageIdxCompute
这个方法其实就是根据给定的页数来计算出其对应的页的序号,这个方法主要的作用是在PoolChunk中进行调用。
1 private int pages2pageIdxCompute(int pages, boolean floor) { 2 int pageSize = pages << pageShifts; 3 //对于大于pageSize的则是 4 if (pageSize > chunkSize) { 5 return nPSizes; 6 } 7 //对pageSize进行log2的向上取整 8 int x = log2((pageSize << 1) - 1); 9 //x >= LOG2_SIZE_CLASS_GROUP + pageShifts + 1后则每个size都是 10 //1<<pageShifts的倍数 11 int shift = x < LOG2_SIZE_CLASS_GROUP + pageShifts 12 ? 0 : x - (LOG2_SIZE_CLASS_GROUP + pageShifts); 13 14 int group = shift << LOG2_SIZE_CLASS_GROUP; 15 //在x >= LOG2_SIZE_CLASS_GROUP + pageShifts + 1是 16 //对于公式size=1<<log2Group+nDelta*(1<<log2Delta), 17 //并且log2Group=log2Delta+LOG2_SIZE_CLASS_GROUP,nDela=[1,1<<LOG2_SIZE_CLASS_GROUP] 18 //那么此时的log2Delta必然是x - LOG2_SIZE_CLASS_GROUP - 1 19 //而在这之前的所有是(1<<pageShifts)的则必然是[1,1<<LOG2_SIZE_CLASS_GROUP) 20 //的所有值 21 int log2Delta = x < LOG2_SIZE_CLASS_GROUP + pageShifts + 1? 22 pageShifts :x - LOG2_SIZE_CLASS_GROUP - 1; 23 int deltaInverseMask = -1 << log2Delta; 24 //这里计算的是对于size中每一组中从[0,1 << LOG2_SIZE_CLASS_GROUP-1]这一段的值 25 int mod = (pageSize - 1 & deltaInverseMask) >> log2Delta & 26 (1 << LOG2_SIZE_CLASS_GROUP) - 1; 27 28 int pageIdx = group + mod; 29 30 if (floor && pageIdx2sizeTab[pageIdx] > pages << pageShifts) { 31 pageIdx--; 32 } 33 34 return pageIdx; 35 }
PoolArena构造函数
protected PoolArena(PooledByteBufAllocator parent, int pageSize, int pageShifts, int chunkSize, int cacheAlignment) { super(pageSize, pageShifts, chunkSize, cacheAlignment); this.parent = parent; directMemoryCacheAlignment = cacheAlignment; directMemoryCacheAlignmentMask = cacheAlignment - 1; //Small子页的个数,由上图可知39 numSmallSubpagePools = nSubpages; smallSubpagePools = newSubpagePoolArray(numSmallSubpagePools); for (int i = 0; i < smallSubpagePools.length; i ++) { smallSubpagePools[i] = newSubpagePoolHead(); } q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize); q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize); q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize); q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize); q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize); qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize); q100.prevList(q075); q075.prevList(q050); q050.prevList(q025); q025.prevList(q000); q000.prevList(null);//没有前一个列表,可以直接删除块 qInit.prevList(qInit); List<PoolChunkListMetric> metrics = new ArrayList<PoolChunkListMetric>(6);//使用率指标 metrics.add(qInit); metrics.add(q000); metrics.add(q025); metrics.add(q050); metrics.add(q075); metrics.add(q100); chunkListMetrics = Collections.unmodifiableList(metrics); }
按chunk的内存使用率进行分组
内部会按照chunk的使用率分成6组,每个组都是PoolChunkList类型的数组,里面还维护着chunk链表,每个链表有最大能申请的容量,有内存使用率的范围,然后PoolChunkList也以链表的形式连接,只要chunk的内存使用率发生变化,就会判断是否超出范围,超出会进行移动。 每个 PoolChunkList 的上下限都有交叉重叠的部分,如下所示。因为 PoolChunk 需要在 PoolChunkList 不断移动,如果每个 PoolChunkList 的内存使用率的临界值都是恰好衔接的,例如 1 ~ 50%、50% ~ 75%,那么如果 PoolChunk 的使用率一直处于 50% 的临界值,会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。
q050;//50-100 q025;//25-75 q000;//1-50 qInit;//0-25 q075;//75-100 q100;//100-100
PooledByteBufAllocator的heapBuffer
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();//获取线程本地缓存
PoolArena<byte[]> heapArena = cache.heapArena;
final ByteBuf buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);//调用allocate
} else {//用非池化的堆缓冲区
buf = PlatformDependent.hasUnsafe() ?
new UnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
heapArena.allocate
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) { PooledByteBuf<T> buf = newByteBuf(maxCapacity); allocate(cache, buf, reqCapacity); return buf; }
newByteBuf
protected PooledByteBuf<byte[]> newByteBuf(int maxCapacity) { return HAS_UNSAFE ? PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity) : PooledHeapByteBuf.newInstance(maxCapacity); }
PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity)
从一个RECYCLER的对象池里取得,然后返回
static PooledUnsafeHeapByteBuf newUnsafeInstance(int maxCapacity) { PooledUnsafeHeapByteBuf buf = RECYCLER.get(); buf.reuse(maxCapacity); return buf; }
核心方法allocate
对用户申请的内存大小进行 SizeClasses 规格化,获取在 SizeClasses 的索引,通过判断索引值的大小采取不同的分配策略
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 根据申请容量大小查表确定对应数组下标序号。
// 具体操作就是先确定 reqCapacity 在第几组,然后在组内的哪个位置。两者相加就是最后的值了 final int sizeIdx = size2SizeIdx(reqCapacity); //根据下标序号就可以得到对应的规格值 if (sizeIdx <= smallMaxSizeIdx) {//smallMaxSizeIdx:38
//下标序号<=「smallMaxSizeIdx」,表示申请容量大小<=pageSize,属于「Small」级别内存分配 tcacheAllocateSmall(cache, buf, reqCapacity, sizeIdx); } else if (sizeIdx < nSizes) {//nSizes:76
//下标序号<「nSizes」,表示申请容量大小介于pageSize和chunkSize之间,属于「Normal」级别内存分配 tcacheAllocateNormal(cache, buf, reqCapacity, sizeIdx); } else {
//超出「ChunkSize」,属于「Huge」级别内存分配 int normCapacity = directMemoryCacheAlignment > 0 ? normalizeSize(reqCapacity) : reqCapacity; // Huge allocations are never served via the cache so just call allocateHuge allocateHuge(buf, normCapacity); } }
tcacheAllocateNormal
先尝试从本地线程缓存中分配内存,如果失败就会从不同使用率的「PoolChunkList」链表中寻找合适的内存空间并完成分配。如果这样还是不行,那就只能创建一个船新PoolChunk对象。内存大小对应的 size 范围是 (28KB, 16MB],
private void tcacheAllocateNormal(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity, final int sizeIdx) {
//首先尝试从「本地线程缓存(线程私有变量,不需要加锁)」分配内存 if (cache.allocateNormal(this, buf, reqCapacity, sizeIdx)) { // was able to allocate out of the cache so move on // 尝试成功,直接返回。本地线程会完成对「ByteBuf」对象的初始化工作 return; }
// 因为对「PoolArena」对象来说,内部的PoolChunkList会存在线程竞争,需要加锁 synchronized (this) {
//委托给「PoolChunk」对象完成内存分配 allocateNormal(buf, reqCapacity, sizeIdx, cache); ++allocationsNormal; } }
PoolArena.allocateNormal
利用前面提到的PoolChunkList ,根据最低的使用率来决定在哪个链表中,可以根据名称(比如 q050 表示PoolChunk的使用率在 50%~100% 范围内)判断出来。 如果不能在 PoolChunkList 找到合适的 PoolChunk 的话,那就需要新建一个 PoolChunk 对象用于当前内存申请,并会把完成此次内存分配后的 PoolChunk 添加到合适的 PoolChunkList 中。Netty 会先从q050开始分配,并非从q000开始。 这是因为如果从q000开始分配内存的话会导致有大部分的PoolChunk面临频繁的创建和销毁,造成内存分配的性能降低。
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) {
//尝试从「PoolChunkList」链表中分配(寻找现有的「PoolChunk」进行内存分配) if (q050.allocate(buf, reqCapacity, sizeIdx, threadCache) || q025.allocate(buf, reqCapacity, sizeIdx, threadCache) || q000.allocate(buf, reqCapacity, sizeIdx, threadCache) || qInit.allocate(buf, reqCapacity, sizeIdx, threadCache) || q075.allocate(buf, reqCapacity, sizeIdx, threadCache)) { return; } // Add a new chunk. PoolChunk<T> c = newChunk(pageSize, nPSizes, pageShifts, chunkSize);//新建一个「PoolChunk」对象 boolean success = c.allocate(buf, reqCapacity, sizeIdx, threadCache);//使用新的「PoolChunk」完成内存分配 assert success; qInit.add(c);//根据最低的添加到「PoolChunkList」节点中 }
PoolChunkList的allocate
先判断有没有超过块列表中块的的最大容量,比如q050,他里面的块的最大容量是16m的50%,也就是8m,超过就返回,进行下一个块列表的申请。没超过就从头结点块开始,尝试申请内存,如果申请成功了,就判断块的使用率是否大于等于块列表的使用率,是的话就移动给下一个块列表,并从当前块列表中删除后返回,否则直接返回。
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache threadCache) { int normCapacity = arena.sizeIdx2size(sizeIdx); if (normCapacity > maxCapacity) {//超过了最大分配容量 // Either this PoolChunkList is empty or the requested capacity is larger then the capacity which can // be handled by the PoolChunks that are contained in this PoolChunkList. return false; } for (PoolChunk<T> cur = head; cur != null; cur = cur.next) { if (cur.allocate(buf, reqCapacity, sizeIdx, threadCache)) { if (cur.freeBytes <= freeMinThreshold) {//最小空闲大小 remove(cur);//从当前块列表移除 nextList.add(cur);//放到下一个块列表里 } return true; } } return false; }
PoolChunk.allocate
核心的内存分配是在 PoolChunk 完成。PoolChunk.allocate可以完成 Small&Normal 两种级别的内存分配,它是根据 sizeIdx 采用不同的分配策略。这个方法会有两条支路,一条是分配 Small 规格内存块,一条是分配 Normal 规格内存块。
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int sizeIdx, PoolThreadCache cache) { final long handle;//long型的handle表示分配成功的内存块的句柄值 if (sizeIdx <= arena.smallMaxSizeIdx) {//当sizeIdx<=38(38是默认值)时,表示当前分配的内存规格是Small // small handle = allocateSubpage(sizeIdx);//分配Small规格内存块 if (handle < 0) { return false; } assert isSubpage(handle); } else { // normal // runSize must be multiple of pageSize int runSize = arena.sizeIdx2size(sizeIdx); handle = allocateRun(runSize); if (handle < 0) { return false; } } //尝试从cachedNioBuffers缓存中获取ByteBuffer对象并在ByteBuf对象初始化时使用 ByteBuffer nioBuffer = cachedNioBuffers != null? cachedNioBuffers.pollLast() : null; initBuf(buf, nioBuffer, handle, reqCapacity, cache);//初始化ByteBuf对象 return true; }