1.Python环境及pip list
(1)Python环境

(2)pip list
2.视频学习笔记
一、机器学习概述




(1) 机器学习可以解决什么?
给定数据的预测问题:a.数据清洗/特征选择
b.确定算法模型/参数优化
c.结果预测
(2)机器学习不能解决什么?
大数据存储/并行计算
做一个机器人
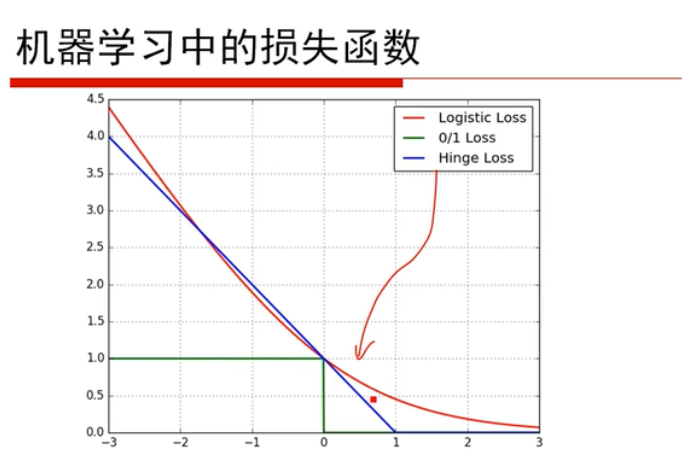
(3)损失函数
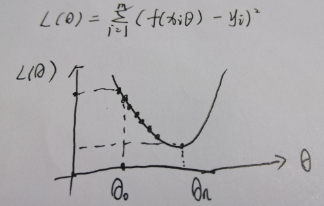
(4)机器学习的一般流程
数据收集 → 数据清洗 → 特征工程 → 数据建模 → 模型使用

建议自学参考文献:

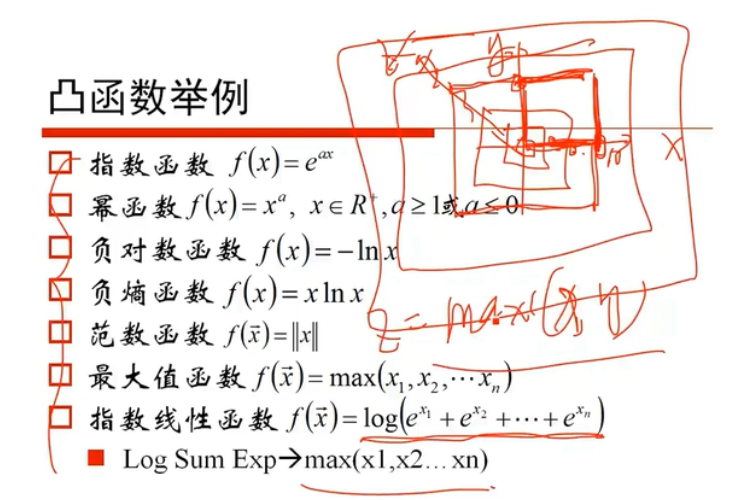
函数回顾:







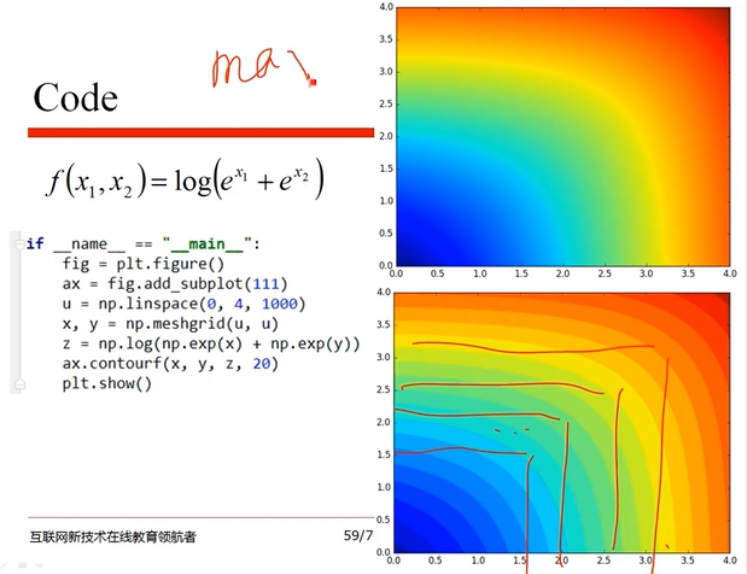
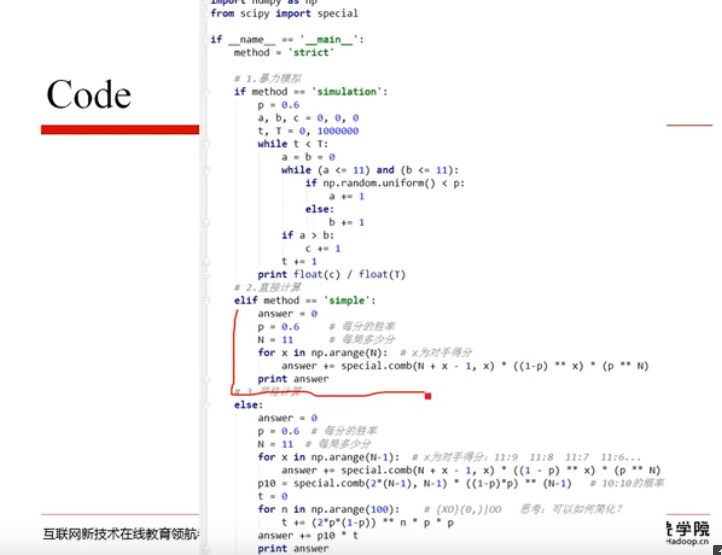
代码实践:
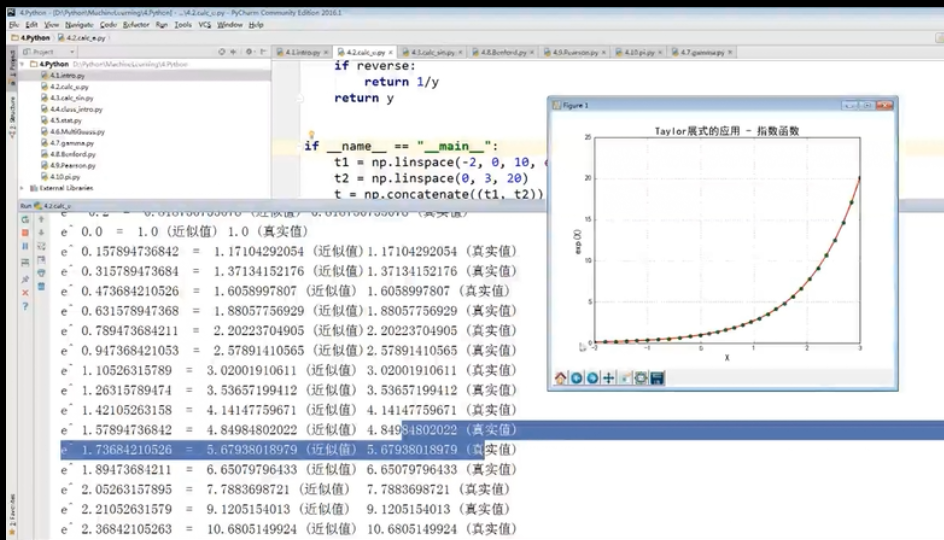
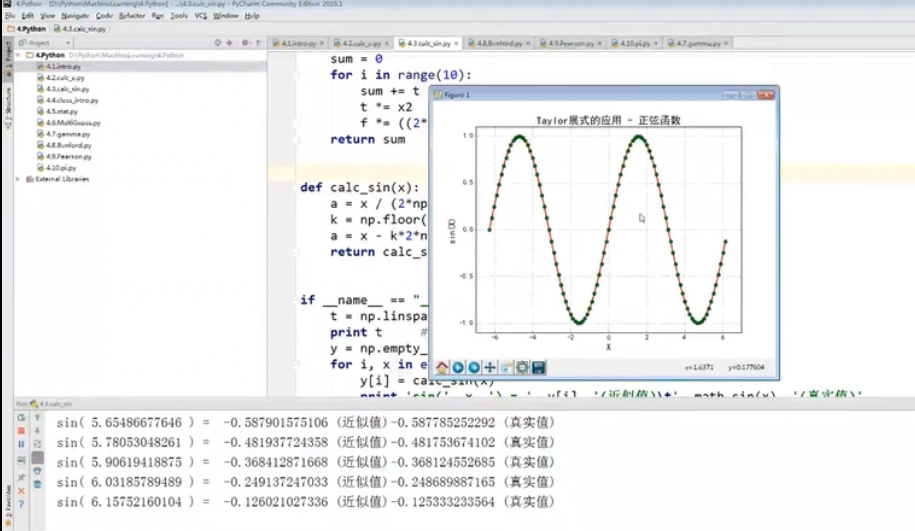



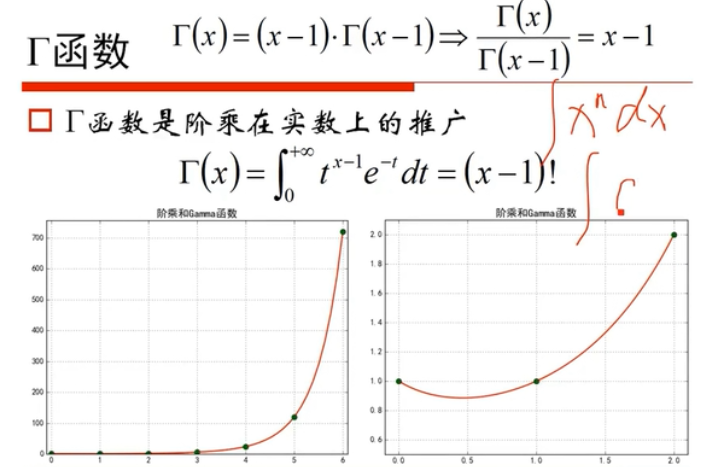
代码实现:




代码实现:


参考文献:

二、Python基础
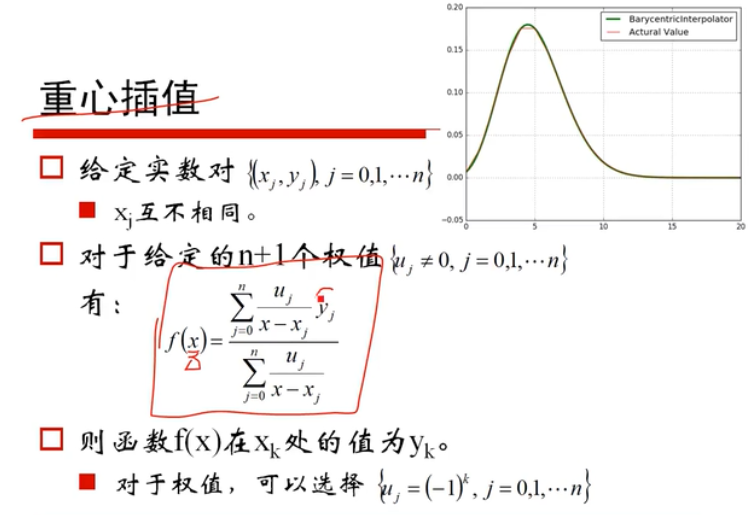
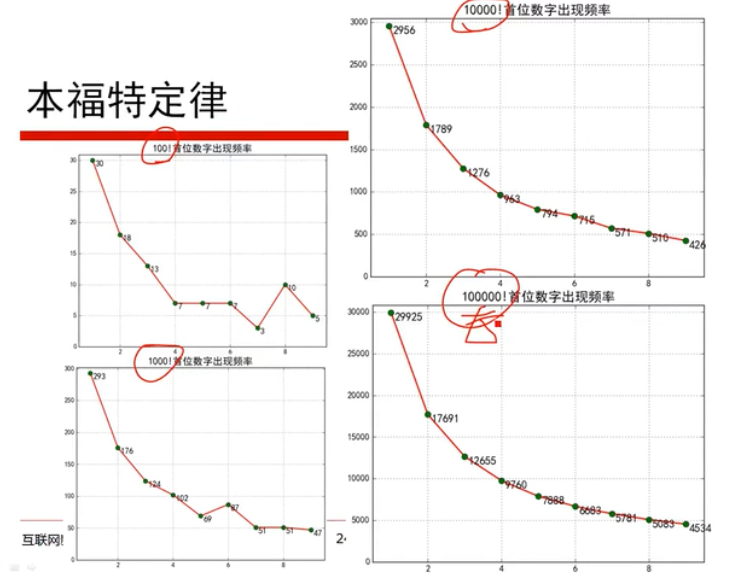
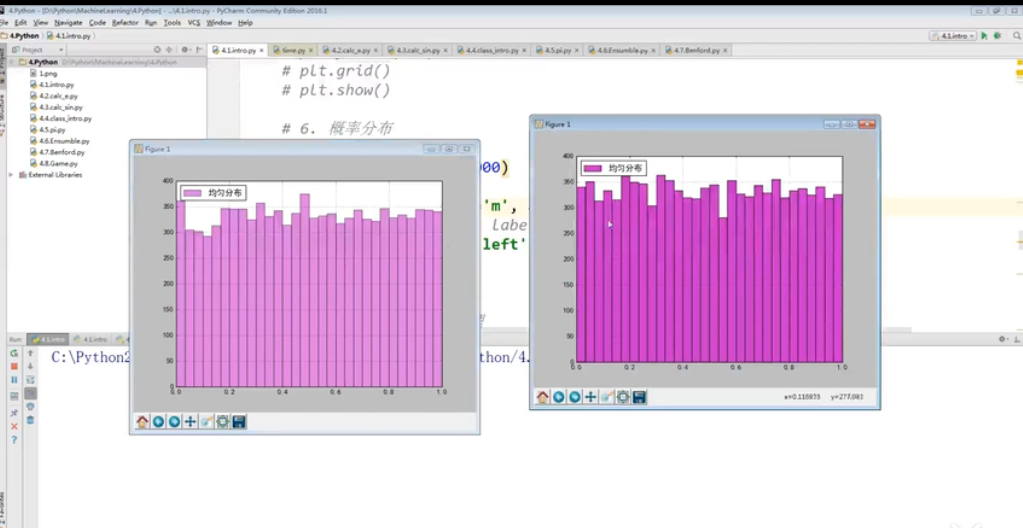
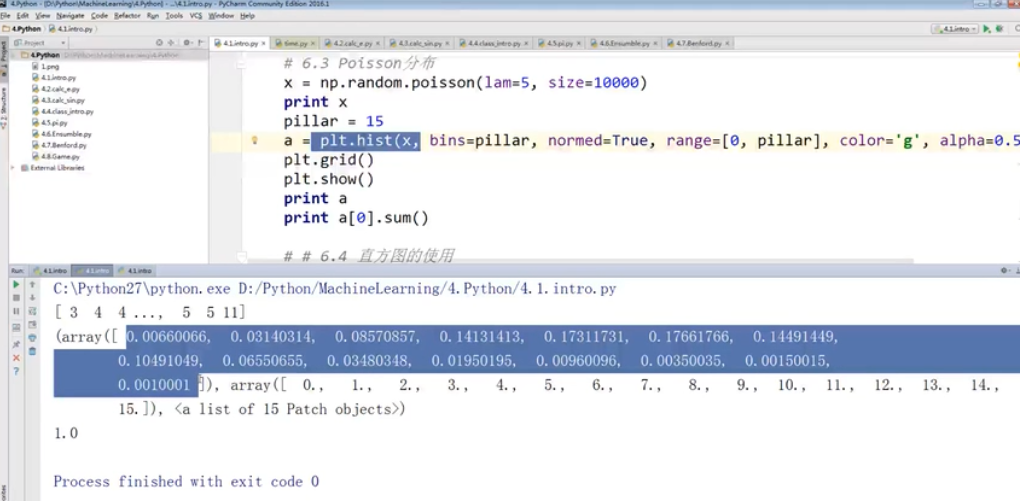
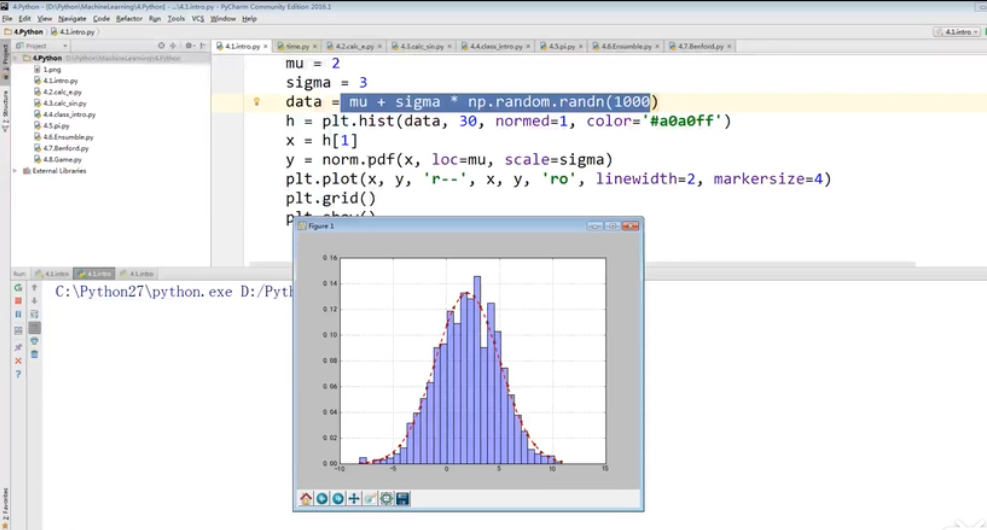
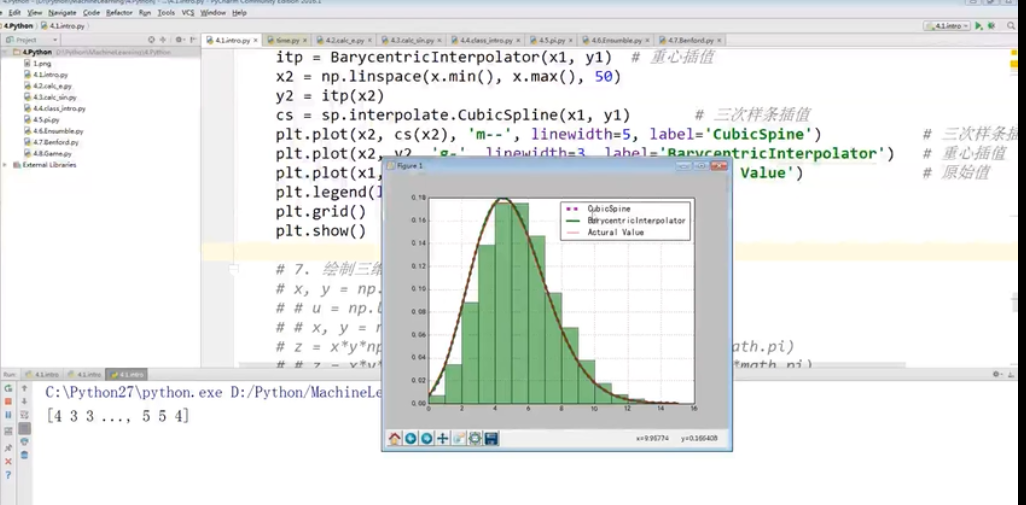
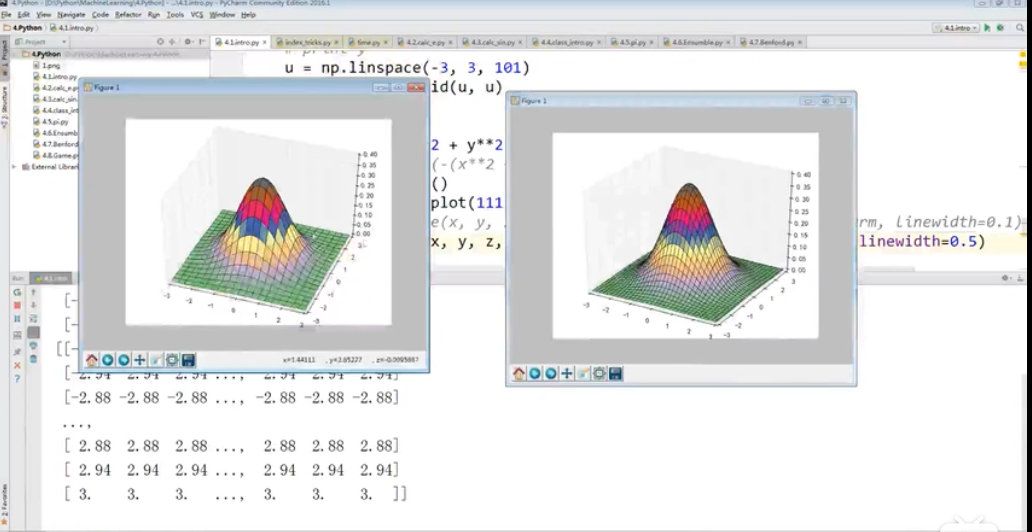
损失函数:(matplotlib绘制)






3.什么是机器学习,有哪些分类?
例如视频中所举例子,机器学习:“盯住2号位,她很容易起快球”。传统算法 :排球规则
再比如,文本分类作为一种有监督学习的任务,毫无疑问的需要一个可用于有监督学习的语料集(X,Y)。本文中使用以下标记,X为特征,文本分类中即为文本序列,Y是标签,即文本的分类名称。

传统的编程方式输入的是指令代码,而机器学习输入的是结构化数据。
因此,在机器学习任务中,数据的质量与数量对最终模型的预测结果好坏具有决定性的作用。在文本分类中,语料集(X,Y)的质量、数量决定了文本分类模型的分类效果。
机器学习通常分为四类:
- 监督学习
- 无监督学习
- 半监督学习
- 强化学习
监督学习有两个典型的分类:
- 分类
比如邮件过滤就是一个二分类问题,分为正例即正常邮件,负例即垃圾邮件。 - 回归
回归的任务是预测目标数值,比如房屋的价格,给定一组特性(房屋大小、房间数等),来预测房屋的售价。
无监督学习
我们有一些问题,但是不知道答案,我们要做的无监督学习就是按照他们的性质把他们自动地分成很多组,每组的问题是具有类似性质的(比如数学问题会聚集在一组,英语问题会聚集在一组,物理........)
所有数据只有特征向量没有标签,但是可以发现这些数据呈现出聚群的结构,本质是一个相似的类型的会聚集在一起。把这些没有标签的数据分成一个一个组合,就是聚类(Clustering
半监督
半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。在现实任务中,未标记样本多、有标记样本少是一个比价普遍现象,如何利用好未标记样本来提升模型泛化能力,就是半监督学习研究的重点。要利用未标记样本,需假设未标记样本所揭示的数据分布信息与类别标记存在联系。
强化学习
简单来说就是给你一只小白鼠在迷宫里面,目的是找到出口,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。强化学习的典型案例就是阿尔法
参考链接:https://www.bilibili.com/video/BV1Tb411H7uC?p=1
https://www.bilibili.com/video/BV1Tb411H7uC?p=4
https://www.jianshu.com/p/e6d71a9b1554